Intro
안녕하세요? JustKode, 박민재입니다. 오늘은 차세대 Table Format인 Apache Iceberg에 대해서 알아 보도록 하겠습니다.

왜 우리는 Table Format이 필요할까요? 사용자들은 여러 가지의 이유로 생성된, 여러 개의 테이블을 사용하게 됩니다. 우리들은 테이블의 다양한 사용처를 위해 데이터 구조화, 스키마 정의 및 확장, 인덱싱, 데이터 일관성 보장 및 버전 관리를 수행 할 수 있어야 하는데요, 이는 Apache Hive의 Meta Store 등으로 수행 하는데 있어, 제약사항이 존재 합니다. (ACID 미지원, Schema Evolution 미지원 등) 이를 원활하게 수행 할 수 있도록 도와주는 것이 Apache Iceberg, Apache Hudi, Delta Lake와 같은 Table Format 입니다.
그 중, Apache Iceberg는 Open Source 기반의 Table Format 입니다. Hive, Spark, Flink, Presto 등, 원하는 Engine에서 SQL을 사용 하더라도, 동일한 논리적 테이블에 동일 하게 데이터를 저장 할 수 있으며, ACID 지원, 동시성 제공, 메타데이터 확장 기능, Snapshot 기능을 통한 Rollback 기능 등을 제공 합니다. 이것들이 어떻게 가능 할 수 있었는지 한 번 알아 볼까요?
Architecture
Apache Iceberg는 Metadata을 기반으로 Snapshot을 관리 하며 데이터를 저장 합니다. 기존 Hive나 Spark의 파티셔닝 기능을 사용 한다면, Dictionary를 이용하여 파일을 저장 하였겠지만 (ex: month, day, hour로 파티셔닝을 수행 한다면, /month=202401/day=20240101/hour=2024010100) Apache Iceberg는 Metadata File과 Manifest List, Manifest File을 이용하여, 특정 Snapshot에 해당하는 파일들을 관리 합니다. 여기서 Metadata File은 Table의 특정 Snapshot 정보를 저장 합니다.
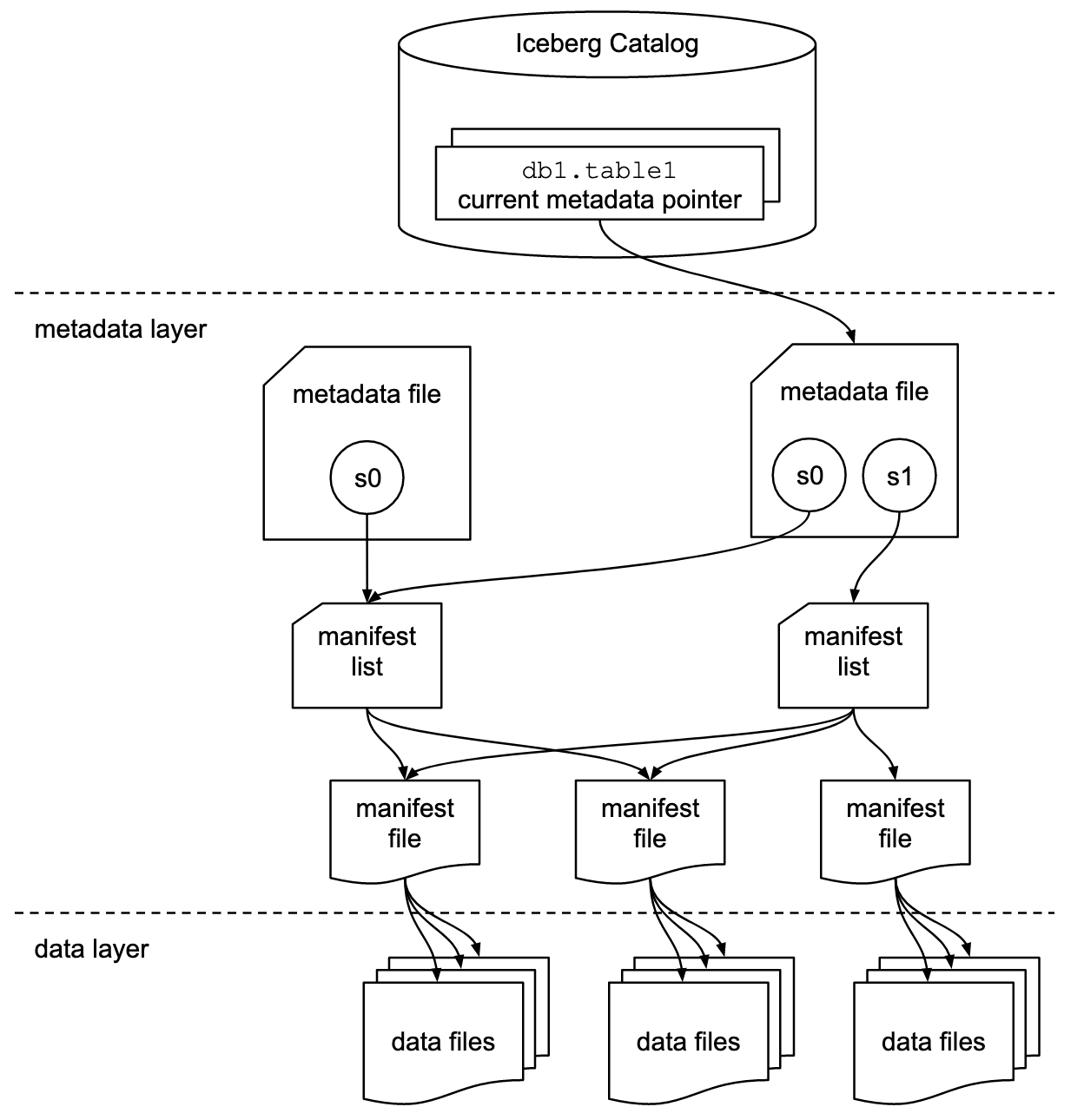
이렇게 Metadata 기반으로 관리를 하게 되면, 각 Snapshot의 데이터를 디렉토리가 아닌, Metadata가 각 개별 파일을 바라보는 방식으로로 관리를 수행 할 수 있습니다.
Features
기본적으로 Apache Iceberg는 Spark SQL을 사용하는 경우에는 Catalog, Database, Table의 Hierarchy로 작동 합니다. 해당 예제들은 Spark SQL을 사용 한다고 가정 합니다.
SELECT * FROM prod.db.table; -- catalog: prod, namespace: db, table: tableExpressive SQL
Iceberg는 기존에 제공하지 않는 다양한 SQL 문들을 제공합니다. MERGE INTO와 같이 조건에 따라 데이터를 업데이트 하거나 추가 할 수 있는 문법을 제공 합니다. 다음은 기존 테이블의 id와 겹치지 않는다면, 데이터를 삽입 해 주는 예시입니다.
MERGE INTO prod.nyc.taxis pt
USING (SELECT * FROM staging.nyc.taxis) st
ON pt.id = st.id
WHEN NOT MATCHED THEN INSERT *;또한, 테이블 내에서 데이터를 삭제할 때, Metadata 상에서만 삭제를 수행 한 뒤, 추후에 File을 Rewrite 하는 방식으로 Read & Update Performance를 높이기도 합니다.
Schema Evolution
기존 Hive Metastore를 이용 하는 것과 다르게, Apache Iceberg 에서는 유연한 Schema Evolution이 가능 합니다. ADD, DROP, RENAME, UPDATE, REORDER 등의 기능을 지원 하는데요, 이가 가능한 이유는 Iceberg 내부적으로 이를 Metadata로 저장 하기 때문에 가능 합니다. Iceberg를 사용 하는 각 Engine (Spark, Hive 등)에서는, Metadata에 저장 되어 있는 테이블 정보와 데이터가 일치 하도록 File Read를 수행 합니다. 없는 Column은 읽지 않고, 추가된 Column으로 과거 데이터를 읽는다면 null 혹은 기본 값으로 데이터를 반환 합니다.
Partition에 대한 Schema Evolution도 유연하게 수행 할 수 있는데요, 이가 가능한 이유는, Iceberg는 Partitioning을 Metadata 기반으로 수행 하기 때문입니다. Partition 관련 정보가 수정 되면, 그 이후 부터는 파일 저장을 내부적으로 Hash, Range 기법으로 특정 Value 값을 가진 Row 끼리 묶어서 파일을 저장하고 (Bucketing), 해당 정보들을 Metadata에 저장 합니다. 그 이후 쿼리 수행 시, Metadata를 참조한 후, 필요한 파일 만을 이용하여 쿼리를 수행 합니다. (관련 Spec)
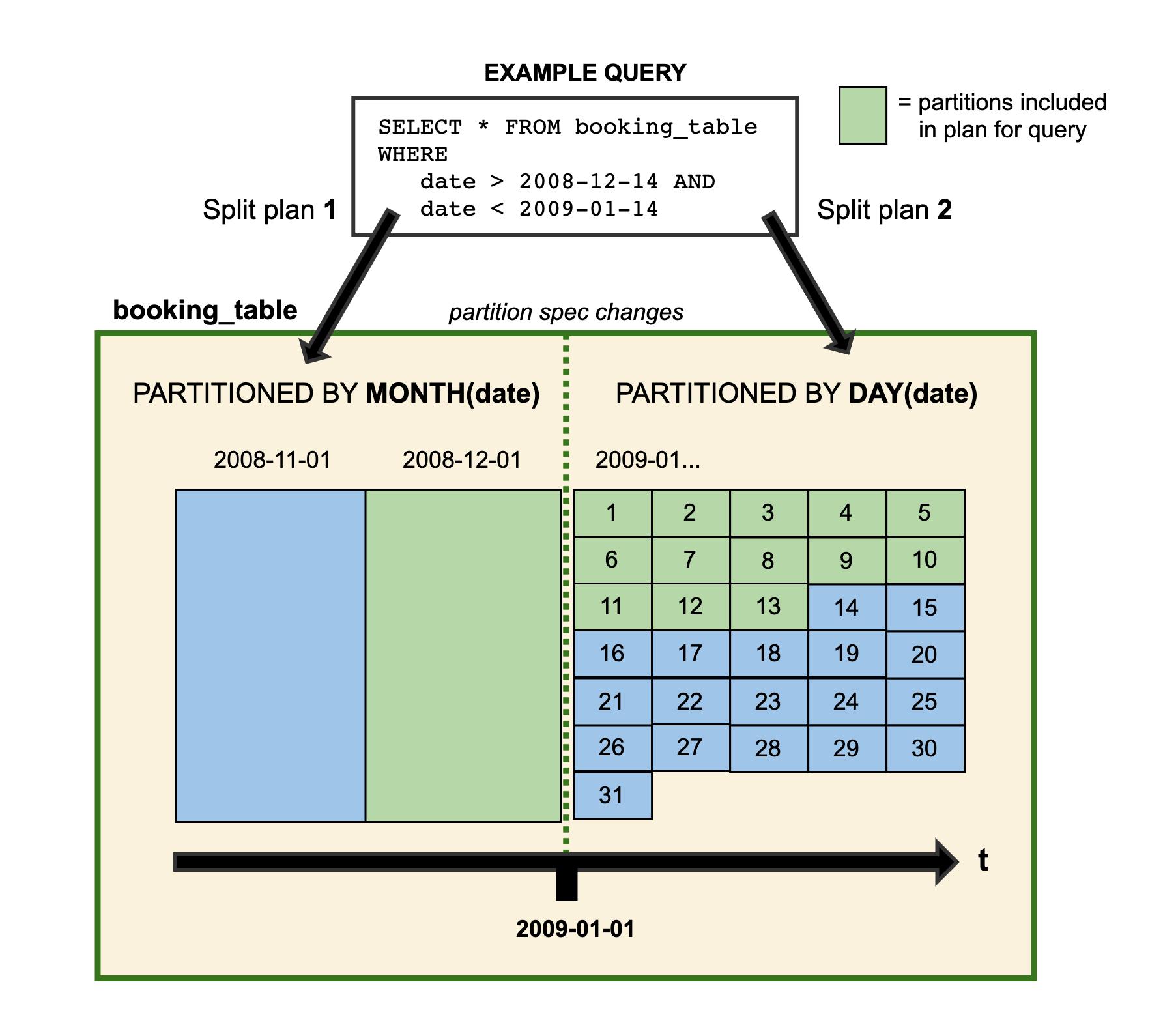
Hidden Partitioning
아까 설명한 Schema Evolution의 근본이 되는 원리입니다. Iceberg 에서는 물리적으로 Partitioning을 수행 하지 않아도, 내부적으로 Hidden Partitioning을 수행 하여, Hive와 다르게, 파일을 Dictionary 등을 이용 하여 물리적으로 Partitioning을 수행 할 필요가 없습니다. Metadata에 특정 파일이 가지고 있는 특정 Column의 Upper Bound, Lower Bound 등을 가지고 있어, 해당 값을 바탕으로 필요한 파일만 Read 하여, Partitioning의 효과를 냅니다.
다음은 테이블 내부의 Metadata 정보를 반환 하는 예제입니다.
SELECT * FROM prod.db.table.files; -- catalog: prod, namespace: db, table: table| content | file_path | file_format | spec_id | partition | record_count | file_size_in_bytes | column_sizes | value_counts | null_value_counts | nan_value_counts | lower_bounds | upper_bounds | key_metadata | split_offsets | equality_ids | sort_order_id |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | s3:/.../table/data/00000-3-8d6d60e8-d427-4809-bcf0-f5d45a4aad96.parquet | PARQUET | 0 | {1999-01-01, 01} | 1 | 597 | [1 -> 90, 2 -> 62] | [1 -> 1, 2 -> 1] | [1 -> 0, 2 -> 0] | [] | [1 -> , 2 -> c] | [1 -> , 2 -> c] | null | [4] | null | null |
| 0 | s3:/.../table/data/00001-4-8d6d60e8-d427-4809-bcf0-f5d45a4aad96.parquet | PARQUET | 0 | {1999-01-01, 02} | 1 | 597 | [1 -> 90, 2 -> 62] | [1 -> 1, 2 -> 1] | [1 -> 0, 2 -> 0] | [] | [1 -> , 2 -> b] | [1 -> , 2 -> b] | null | [4] | null | null |
| 0 | s3:/.../table/data/00002-5-8d6d60e8-d427-4809-bcf0-f5d45a4aad96.parquet | PARQUET | 0 | {1999-01-01, 03} | 1 | 597 | [1 -> 90, 2 -> 62] | [1 -> 1, 2 -> 1] | [1 -> 0, 2 -> 0] | [] | [1 -> , 2 -> a] | [1 -> , 2 -> a] | null | [4] | null | null |
Travel And Rollback
Apache Iceberg는 Snapshot 기반으로 Metadata를 저장하고 운영 합니다. 그렇기에 Snapshot Metadata와 해당하는 Snapshot의 파일 들이 남아있다면, 해당 시점의 데이터에 대해서 조회가 가능합니다.
sql> SELECT count(*) FROM nyc.taxis;
2,853,020
sql> SELECT count(*) FROM nyc.taxis FOR VERSION AS OF 2188465307835585443;
2,798,371
sql> SELECT count(*) FROM nyc.taxis FOR TIMESTAMP AS OF TIMESTAMP '2022-01-01 00:00:00.000000 Z';
2,798,371File Compaction
Apache Iceberg 에는 File Compaction 기능이 존재 하는데요, 이는 Hadoop 등의 Block Size를 관리 해 주어야 하는 경우에 유용 합니다. 특정 테이블에 산개해 있는 파일을 미리 설정한 Size로 Compaction 할 수 있습니다. 이는 HDFS의 Block Size와 유사 할 수록 좋겠죠?
Table table = ...
SparkActions
.get()
.rewriteDataFiles(table)
.filter(Expressions.equal("date", "2020-08-18"))
.option("target-file-size-bytes", Long.toString(500 * 1024 * 1024)) // 500 MB
.execute();당연히, Metadata 또한 HDFS에서 File로 관리 될 터이니, 이 또한 잘 관리 해 주는 것이 좋습니다. Manifest 또한 Compaction을 수행 할 수 있어요.
Table table = ...
SparkActions
.get()
.rewriteManifests(table)
.rewriteIf(file -> file.length() < 10 * 1024 * 1024) // 10 MB
.execute();마치며
이렇게 Apache Iceberg에 대해서 전반적인 원리와 기능들에 훑어 보는 시간을 가졌습니다. 다음 시간에는 이를 Spark와 연동하는 예제로 찾아 뵙겠습니다. 감사합니다.