Summary
- Data Engineering이 구체적으로 무엇인지 알아 봅니다.
- 왜 Data Engineering이 필요 하게 되었는지 알아 봅니다.
- Data Engineer는 팀 혹은 회사에서 어떤 역할을 수행 하는지 알아 봅니다.
머릿말
안녕하세요? JustKode, 박민재입니다. 오늘은 Data Engineering이 구체적으로 무엇 인지, Data Engineer는 왜 필요 하게 되었고, 어떤 역할을 구체적으로 수행 하는지 알아 보겠습니다.
Data Engineering은 무엇 일까요? 사실 양지로 나온지 얼마 되지 않은 직군이다 보니, 많은 사람들이 Data Engineer라는 직군을 Data Scientist, Data Analysist와 혼동을 하곤 합니다. (회사의 사정에 따라 병행하는 곳도 많습니다.) Data Engineering은 본론으로 넘어 가기 전, 간단하게 언급 하자면, '데이터를 가져와서 적절한 형태로 변환하여 저장하고, 데이터 과학자나 분석가 등이 사용 할 수 있도록 준비하는 것' 입니다. 이런 작업이 왜 필요하게 되었고, 어떤 식으로 서비스 운영에 기여 하는지, 이제 알아 보도록 하겠습니다.

What is Data Engineering?
많은 사람들이 데이터 엔지니어링에 대해 정의한 공통된 맥락을 요약 하면, 아까 설명 드렸던 것처럼 '데이터를 가져와서 적절한 형태로 변환하여 저장하고, 데이터 과학자나 분석가 등이 사용 할 수 있도록 준비하는 것' 입니다.
우리의 서비스에 AI, ML, 데이터 분석을 적용 하기 위해서는 어떤 것을 해야 할까요? 일단 제일 먼저 데이터 수집을 수행 해야 합니다. 이는 사용자의 사용 로그 및 이벤트 일 수도 있고, 사용자가 서비스에 업로드 한 게시물, 댓글, 사진, 영상 등 여러 가지가 될 수 있습니다.
하지만, 로그 및 이벤트를 그대로 다른 엔지니어들이 사용 하게 하기는 어렵습니다. 만약 몇 백억 건의 이벤트가 저장 되어 있는 스토리지가 있다고 가정 할 때, 해당 스토리지에 필요 할 때마다 쿼리를 해야 한다면? 그렇게 되면, 컴퓨팅 리소스가 너무 많이 사용이 될 것이기 때문에, 미리 사람들이 자주 조회하는 데이터에 대해서 미리 집계를 하여, OLAP(Online Analytical Processing) Platform 등을 이용, 서비스 혹은 BI 에서 쉽게 사용 할 수 있게 하여야 할 것입니다.
또한, ML 쪽이라고 다르진 않습니다. 정제 되지 않은 서비스 로그를 ML Engineer들이 그대로 사용 하기에는 어려움이 존재 합니다. AI 모델의 Input 데이터의 형식에도 맞춰 줘야 하고, 필요한 메타 데이터가 있다면 이에 맞춰 데이터를 조인하여 적재하는 기술 또한 필요하게 됩니다. 실시간성이 중요하다면, 더 빠르게 서빙이 될 수 있도록 하는 기술도 필요하겠네요!
제가 생각하는 그림은 다음과 같아요.

다양한 데이터의 원천으로 부터(Service에서 사용하는 DBMS, Event Receiver, Message Queue의 데이터 등) 정제되지 않은 많은 데이터를 수집하고, 변환하고, 이를 다시 사용자들의 필요에 맞게 Data Lake, Data Warehouse, Data Mart, OLAP Platform 등에 적재합니다. 이를 줄여서 ETL (Extract, Transform, Load) 이라고 합니다. 그렇게 적재 된 데이터는 내부 사용자인 Data Anaysist, Data Scientist, ML Engineer 등과, 외부 사용자인 Application의 User와 SW Engineer가 사용하게 됩니다.
Why need Data Engineer?
데이터 엔지니어들이 하던 업무들은 원래 서버 엔지니어들이 같이 수행 하던 업무였습니다. 하지만, 점점 빅데이터의 중요성이 대두 되고, 많은 회사에서 데이터 기반 의사결정 혹은 Application 내 AI 서비스, 혹은 빅데이터 기반 Analysis 서비스를 공격적으로 제공 할 필요성이 대두됨에 따라, Data Engineering에 대해서 특화된 사람들이 필요하게 되었죠. 그렇게 Data Engineer라는 직군이 생겨 나게 되었습니다. 그렇다면 데이터 엔지니어들은 어떤 역량을 가지고 있어야 할까요? 자세히 알아보기 이전에, 데이터 엔지니어들이 다루게 되는 데이터 생명 주기에 대해서 알아 보도록 하죠!
데이터 생명 주기
데이터 생명 주기는 5단계로 나눌 수 있는데요, 여기서 데이터 엔지니어링 생명 주기에 해당하는 부분은 볼드체로 처리 하도록 하겠습니다.
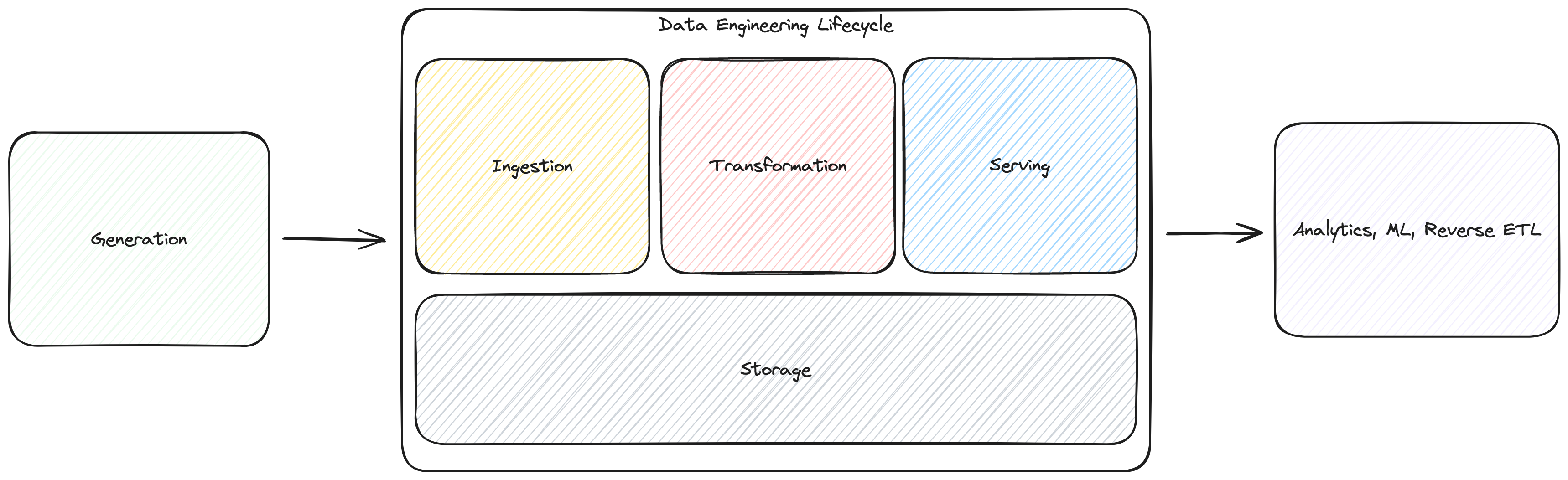
- 데이터 생성 (Generation)
- DBMS, Messgae Queue 등의 원천 시스템으로부터 데이터의 원본이 생성 됩니다.
- 데이터 엔지니어들은 원본 데이터의 생성 방식, 빈도 및 속도, 다양성을 실무적으로 이해 해야 합니다.
- 데이터 저장 (Storage)
- 데이터를 저장하는 과정입니다. 데이터의 접근 빈도을 기반으로 적절한 스토리지 시스템을 선택 하는 것이 관건입니다.
- 또한, 원본 저장이 목적인지, 쿼리 수행이 목적인지에 따라 저장 방식이 달라 질 수 있습니다.
- 데이터 수집 (Ingestion)
- 원천 시스템의 특징과, 데이터 저장 방법이 숙지 되었다면, 이에 맞춰, 원천 데이터로부터 필요한 데이터를 수집해야 합니다.
- 가장 큰 병목 현상이 일어날 가능성이 높습니다.
- 서빙될 데이터의 SLA (Service-Level Agreement, 서비스 수준의 사용에 문제가 없을 시간)와 데이터의 용량에 따라서 Batch 기법 (데이터를 특정 시간 단위로 한꺼번에 수집) 혹은 Streaming 기법 (데이터를 실시간으로 수집) 중 하나를 선택 합니다.
- 필요한 데이터를 원본 데이터에서 찾아 Pull 하는 방식과, 원본 데이터에서 데이터 스토리지로 Push 하는 방식 두 가지가 있습니다.
- 데이터 변환 (Transformation)
- 데이터를 Down Stream에서 사용 하기 유용한 형태로 변환 합니다. 다운스트림 사용자의 데이터 소비를 위한 가치를 창출하는 단계입니다.
- 데이터 수집 후 수행 되며, 배치 단위로 수행 되거나, 스트리밍으로 데이터를 수집하면서 동시에 변환하는 방식도 사용 됩니다.
- 쿼리, 데이터 모델링, 데이터 품질 보장을 위한 작업들이 수행 됩니다.
- 데이터 서빙 (Serving)
- 변환된 데이터를 바탕으로 가치를 창출하는 단계 입니다.
- 분석 (BI, 운영 분석, 임베디드 분석), 머신러닝, 역 ETL 등에서 사용 됩니다.
이렇게 데이터 생명 주기를 나열해 보았는데요, 그럼 이제부터는 데이터 생명 주기를 바탕으로, 데이터 엔지니어들이 필요로 하게 되는 역량들을 한 번 분석 해 보도록 하겠습니다.
Data Engineering에 필요한 역량들
컴퓨터 과학 지식
먼저, 가장 기본적인 역량은 컴퓨터 과학 지식입니다. 데이터를 저장할 스토리지를 고를 때도, 어떤 네트워크 프로토콜을 사용 하는지, in-memory 기반의 저장소를 사용 하는지 여부, 내부 인덱싱 알고리즘, 파일 저장, 캐싱은 어떤 식으로 이루어지는 지를 이해한 후, 장단점을 파악하여 적절한 스토리지를 선택 할 수 있어야 합니다. 또한 ETL 과정 에서도, 배치와 스트리밍 방식의 장단점을 파악하고 적절하게 활용 할 수 있어야 하며, 대용량의 데이터를 처리 하기 위한 분산 컴퓨팅 시스템 알고리즘에 대한 이해를 가지고 있어야 합니다. 데이터를 정확하고 적절하게 처리 하는 것도 중요하지만, 적은 리소스로 수 많은 데이터를 처리해야 하기 때문에, 운영체제, 알고리즘, 네트워크에 대한 지식은 필수적이라고 볼 수 있습니다,
도메인 지식
두 번째는 현재 운영 하는 서비스에 대한 도메인 지식입니다. 기본적인 도메인 지식이 없어 운영 되는 데이터의 의미를 모르게 된다면, 아무리 프로젝트 매니저가 존재하더라도, 데이터 운영에 있어 애로 사항을 겪을 수 있습니다. 어떤 데이터가 자주 조회되고, 어떤 데이터가 어떤 비즈니스 로직으로부터 왔는지, 이 데이터는 다시 어떻게 사용 하기 위해 수집 되고 있는지 등에 대한 지식이 있어야 합니다. 그렇게 해야 데이터 파이프라인의 운영에 있어, 중복되는 테이블은 병합하고, 사용하지 않는 데이터는 과감하게 수집 하지 않고, 사용자 입장에서 필요한 데이터만을 적극적으로 제공 해 주는 등, 컴퓨팅 리소스 혹은 커뮤니케이션 리소스 최적화에 있어 큰 힘을 쓸 수 있습니다.
안정적인 운영을 위한 기술들
세 번째는 안정적인 운영을 위한 기술들입니다. 저는 크게 컨테이너/클라우드 기술과 모니터링 기술을 뽑을 수 있을 것 같습니다. 우리가 데이터 생명 주기내에서 데이터 엔지니어링 업무를 수행 하며, 다양한 환경에서 실행 되는 수 많은 툴들을 사용 합니다. 하지만, 이를 단일 노드에서 환경 분리 없이 수행 하기는 너무나도 어려운 일이죠. 그렇기 때문에, 우리는 Docker를 기반으로 한 컨테이너 기술과, 컨테이너의 안정적인 리소스 관리를 위한 Kubernetes와 같은 컨테이너 오케스트레이션 기술들을 배워 놓는 것이 좋습니다. 또한, Kubernetes 환경에서 효율적으로 패키지를 관리 하기 위한 Helm 같은 기술들도 필요 하게 될 것 같구요. ETL Job의 워크플로우를 관리 해 주는 Airflow 같은 프레임워크의 지식도 필요 할 것 입니다. 만약, 회사가 On-Premise 환경이 아니라면, AWS, GCP와 같은 환경에도 익숙 해 질 필요가 있을 거에요. Prometheus, Grafana와 같이 컴퓨팅 리소스 자체를 모니터링 할 수 있는 툴도 좋고, 데이터의 품질을 보장하기 위한, Data Quality 모니터링 관련 툴인 Great Expectation, Amazon Deequ도 활용 할 수 있다면 좋을 것입니다.
새로운 기술들
Data Engineering을 수행 하며 직면하는 많은 문제들을 해결 하기 위해서, 우리는 끊임 없이 학습 하여야 합니다. 대충 우리가 알아야 하는 지식들은 다음과 같습니다.
- 기본적인 Python, Java, Scala, Go 등의 데이터 엔지니어링에 기본적으로 사용 되는 언어
- Streaming, Batch 데이터를 처리 하는 기술들 (Spark, Flink 등)
- ETL Job Workflow를 관리 하는 기술들 (Airflow 등)
- OLAP Platfrom의 운영을 위한 툴
- HDFS Cluster 등의 여러 가지 데이터 스토리지의 지식
- Docker Container 혹은 Kubernetes Cluster의 관리를 위한 기술들
- Data Quality를 보장 하기 위한 툴들
- Data Discovery를 쉽게 수행 할 수 있도록 하는, Data Discovery Platform 오픈 소스들
- Apache Iceberg 등의 새로운 Table Format
- 고가용성을 보장하기 위한 기술들
- 모니터링을 위한 툴들
- Unit Test, Test Coverage 등, 코드 안정성을 보장 하기 위한 기술들
어... 엄청 많네요, 필요한 상황에 맞게 우리가 운영 하는 컴포넌트가 주어진 요구 사항들을 문제 없이 수행 할 수 있도록, 해당 지식들에 대한 끊임 없는 학습을 하여야 합니다.
마치며
여기까지 긴 글 읽어 주신 여러분 모두 감사드립니다. 자세한 데이터 엔지니어링 로드맵은 해당 링크의 Github Repository에서 확인 해 볼 수 있습니다. 혹시 잘못된 내용이 있거나, 피드백할 내용이 있다면 편하게 댓글 달아 주세요!
참고 문헌
- 견고한 데이터 엔지니어링 <2023, 한빛미디어>