안녕하세요? 박민재입니다. 오늘날의 Data Engineer들은 로그, 혹은 이벤트 데이터를 적재 하고, 적절한 데이터 변환을 수행 하여 데이터 분석가, 백엔드 개발자, 혹은 소비자에게 직접 전달 하는 등의 다양한 업무들을 수행 합니다.
하지만, 점점 데이터의 요구사항이 복잡해지면서 데이터 엔지니어가 제공해야 하는 데이터와, 데이터 분석가가 제공해야 하는 데이터의 싱크를 맞추기가 상당히 어려워 졌습니다. 데이터 엔지니어가 데이터 분석가의 도메인 영역에 대해 완벽히 이해 하는 것도 어렵고, 데이터 분석가가 데이터 엔지니어들의 데이터 엔지니어링 영역에 대해 완벽히 이해 하는 것도 어렵습니다.
또한, Data Analysis Logic의 파편화로 인해 낮은 재사용성과 유지보수의 어려움을 겪게 되는 경우도 있고, 문서화의 부재로 Data Mart의 History 파악이 어렵게 되며, 당연스럽게도 이에 따라 Table 관리에 있어, Side Effect 파악이 어려워 지는 문제도 동반하게 됩니다.
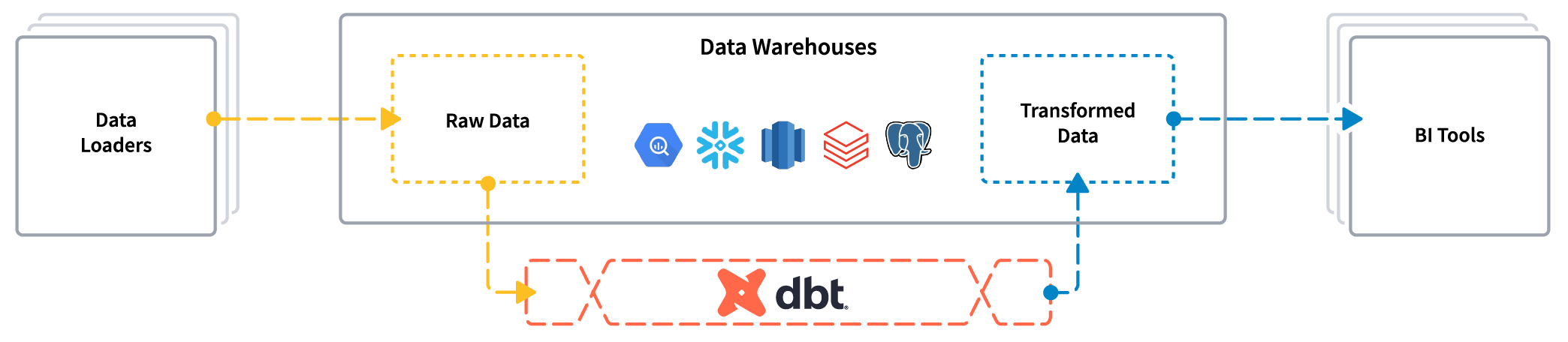
그렇기 때문에, 데이터 분석가와 데이터 엔지니어들이 서로의 공통된 언어로 이야기를 나눠야 하는데요, 바로 SQL 입니다. dbt는 SQL을 이용하여 Data Pipeline을 구성하게 해주는 툴입니다. ETL 과정 중의 Transform 파트를 전문적으로 다루며, 사용자가 SQL과 DB Connection, Schema 등이 포함된 yaml 파일을 전달하면, Data Lineage에 맞게 데이터를 Build 해주며, Versioning, Test, Documentation 모두를 일괄적으로 수행 할 수 있습니다. 추가적으로 dbt에서는 SQL의 모듈화를 수행 하여, 데이터의 중복 연산 방지, 통일된 지표를 통해 데이터 분석 결과에 오류를 줄이는 등의 효과를 누릴 수 있습니다.
dbt는 BigQuery, Snowflake, Databricks 등의 Cloud Platform 부터, Spark, Hive, Trino, Flink 등을 지원합니다.
Features
주요 기능은 다음과 같습니다.
- SQL Script를 모듈화 하여, 모델 간 의존 관계를 추적 하여 작업 수행 가능
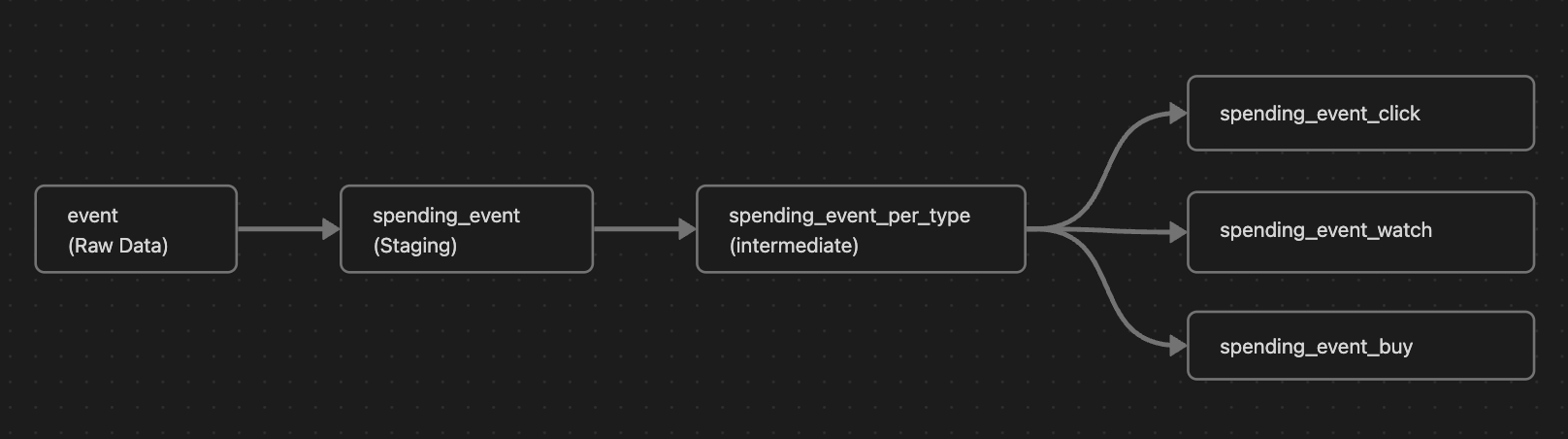
- event Table에서 매출이 발생한 경우의 데이터만 추출 한 spending_event 라는 Staging Model을 생성
- spending_event에서 이벤트 유형, 광고 ID 별로 group by 한 spending_event_per_type 이라는 Intermediate Model 생성
- spending_event_per_type에서 Click이 발생 한 경우만 추출한 spending_event_click 이라는 최종 Mart Table Model 생성
- 집계 된 데이터에서, 어떤 데이터를 참고하는지 Data Lineage를 제공해 줄 수 있음.
- SQL Script에 대해 Git과 같은 버전 관리 시스템으로 History를 추적 할 수 있음
- Data Quality Check에 있어서도, dbt Model에 대해서 null 값, 중복 키등에 대한 Test를 손쉽게 수행 할 수 있음
Model
모델은 하나의 SQL 쿼리로 대응됩니다. Source 데이터가 준비 되었다면, 이를 통해, 여러 가지 모델을 구성 할 수 있습니다.
또한, materialized Option을 통해, 실물 테이블을 생성할지 말지를 결정 할 수 있습니다.
- table: 실물 테이블 생성
- view: View만 생성
- incremental: 증분된 데이터에 대해서만 생성, 증분 기준은 템플릿을 통해 지정 가능.
dbt 공식 문서에서는 Staging, Intermediate, Mart 패턴을 사용 하는 것을 권장 합니다.
Staging
초기 정제가 진행 되는 모델입니다. 작성 예제는 다음과 같습니다.
stg_spending_event.sql
{{ config(materialized='table') }} -- materialized table: 실제 Table로 파일을 생성하겠다는 의미입니다.
SELECT
event_type,
country,
cost,
ad_id
FROM local.event
WHERE cost > 0Intermediate
중간 집계나 조인 테이블이 들어가는 모델입니다.
int_spending_event_per_type.sql
{{ config(materialized='table') }}
SELECT event_type, country, ad_id, sum(cost)
FROM {{ ref('stg_spending_event') }}
GROUP BY event_type, country, ad_idMart
최종 분석용 테이블입니다.
spending_event_click.sql
{{ config(materialized='table') }}
SELECT event_type, country, ad_id, sum(cost)
FROM {{ ref('int_spending_event_per_type') }}
GROUP BY event_type, country, ad_idProject Structure
Spark를 이용하여 Build 하는 것을 기준으로 한다면,
pip install dbt-core "dbt-spark[session]" 을 통해 Package 설치 이후 (PySpark 포함)
dbt init <project_name> 을 통해서 프로젝트를 초기화 한 이후에, dbt 설치 경로에 있는 profiles.yml 을 수정하여 실행 옵션을 설정 할 수 있습니다.
your_profile_name:
target: dev
outputs:
dev:
type: spark
method: session
schema: [database/schema name]
host: NA # not used, but required by `dbt-core`
server_side_parameters:
"spark.driver.memory": "4g"실제 Model이 추가 된 Project는 다음과 같이 구성할 수 있습니다.
models/
├── staging/
│ ├── stg_spending_event.sql
├── intermediate/
│ ├── int_spending_event_per_type.sql
└── mart/
└── country/
├── spending_event_click.sql
├── spending_event_watch.sql
└── spending_event_buy.sqldbt run을 통해서 이를 실행 할 수 있습니다. 자세한 내용은 공식 문서를 참조 해 주세요.
- dbt core Quickstart: https://docs.getdbt.com/guides/manual-install?step=1
- Spark Session 설정: https://docs.getdbt.com/docs/core/connect-data-platform/spark-setup#session
Incremental Materilization
dbt는 데이터를 증분해서 가져올 수 있는 기능을 가지고 있습니다. 위의 예제에서 만약 현재 데이터 연산이 완료된 이후의 데이터만 가져오고 싶다면, 다음과 같이 필터링을 수행 할 수 있습니다.
(is_incremental()은, 최초 Build를 제외한 Build에 bool True를 반환 합니다.)
{{ config(
materialized='incremental',
unique_key=['hour']
) }}
SELECT
event_type,
country,
cost,
ad_id,
hour
FROM local.event
WHERE cost > 0
{% if is_incremental() %}
-- 이미 처리된 테이블이 있는 경우에만 실행
AND hour > (SELECT coalesce(max(hour), 1990010100) FROM {{ this }})
-- {{ this }}는 현재 생성되는 테이블을 참조
{% endif %}FYI
if is_incremental() 내에 있는 코드는 템플릿 입니다.
만약 모델을 선언하는 SQL에 WHERE 절이 없다면, is_incremental에 WHERE 절을 추가하여
증분된 데이터에 대해서만 가져올 수 있도록 합니다. 예제는 아래와 같습니다.
{{ config(materialized='incremental') }}
select
*,
my_slow_function(my_column)
from {{ ref('app_data_events') }}
{% if is_incremental() %}
where event_time >= (select coalesce(max(event_time),'1900-01-01') from {{ this }} )
{% endif %}이를 통해서 증분된 데이터에 대해서만 연산을 수행 하여, UPDATE 혹은 APPEND를 수행 할 수 있습니다.
Airflow Integration
아무리 생각해도 dbt Job을 Scheduling 하기 위해서는 Airflow가 적합 할 것으로 보입니다. 어떻게 하면 좋을까요? 바로 Astronomer 사에서 준비한 Astronomer Cosmos를 이용하여, DBT Job을 Airflow DAG 으로 제작 하면 됩니다.
당근 마켓에서 실제로 이를 활용한 사례가 있으니, 이를 참고해 주세요. https://medium.com/daangn/dbt%EC%99%80-airflow-%EB%8F%84%EC%9E%85%ED%95%98%EB%A9%B0-%EB%A7%88%EC%A3%BC%ED%95%9C-7%EA%B0%80%EC%A7%80-%EB%AC%B8%EC%A0%9C%EB%93%A4-61250a9904ab
지금 까지 간단하게 dbt와 dbt의 모델 구성법에 대해서 러프하게 살펴보았습니다. 긴글 읽어 주셔서 감사합니다.