Intro
안녕하세요! 박민재, JustKode 입니다. 오늘은 Data Quality Tool인 Great Expectations에 대해서 알아 볼 것 입니다.
Data Quality란 무엇일까요? 한국어로 직역하면 데이터 품질입니다. 우리가 많은 양의 데이터를 다루게 될 때, 우리는 기대하지 않은 값이 들어오는 다양한 데이터 품질 이슈를 겪게 됩니다. 데이터의 중복, 누락된 데이터 등, 데이터를 다루시는 분들은 이런 경험들을 많이 하게 되는데요. 만약 데이터 사용처에서 잘못 된 데이터를 사용하여 문제가 발생 한다면 어떻게 될까요? ML 쪽이라면 고객에게 잘못 학습된 모델로 서비스가 제공 될 것이며, 분석 쪽이라면 잘못된 의사결정을, 사용자에게 요금을 청구 하는 쪽과 연결되었다면... 일은 더 커질 것 입니다. 그렇기 때문에, 잘못된 데이터를 사용 하기 전, 우리는 데이터의 품질을 확인 할 필요가 있는 것이지요.
그렇기 때문에, 우리는 수집된 데이터가 예상된 결과를 반환하는지 확인 할 수 있는 툴이 필요 하게 되는데요, 이를 위해서 우리는 Great Expectations를 사용 할 것입니다.
What is Great Expectations?
Great Expectations는 Python을 기반으로 한 Data Quality Open Source Framework 입니다. 다양한 데이터 소스를 사용 할 수 있으며 (S3, FileSystem, RDBMS 등) Pandas, Spark 등의 API를 이용할 수도 있습니다. 제공하는 핵심 기능을 요약 하면 다음과 같습니다.
- Data Validation: Expectation을 생성 하여, 특정 데이터 Batch 단위에 대해 원하는 결과가 반환 되는지 검증 합니다. (ex. null 여부, unique 여부, 문자열 길이, 값의 범위 등)
- Data Profiling: Data의 각 Column에 대한 통계 등을 반환 해 줍니다. (ex. 최대값, 최솟값, 중간값 등)
- Data Docs: Data Validation, Data Profiling에 대한 결과를 HTML Document로 반환 하여 줍니다.
Core Concepts of Great Expectations
Great Expectations를 사용 하기 위해서 이해 해야 할 Core Concepts들이 있습니다. Core Concepts는 다음과 같습니다.
- Data Context: Great Expectations Project를 실행 하기 위한 메타 데이터 정보들이 포함 되어 있습니다.
- Data Sources: Great Expectations Project와 실제 데이터를 연결 해 주는 컴포넌트입니다.
- Checkpoints: Checkpoint는 Great Expectations에서 데이터를 검증하는 추상적인 계층입니다.
Data Context
Data Context는 Great Expectations (이하 GX) Project의 파일 접근 등에 필요한 메타 데이터와 설정 값 등을 가지고 있습니다.
GX Project Python API의 Entrypoint 역할을 수행 하며, 대부분의 작업이 Data Context의 메타 데이터를 이용하여 수행 됩니다.
Data Context에는, 추후 설명할 Data Docs의 접근에 필요 한 정보들과 Stores의 접근에 필요 한 정보들을 지정해 줄 수 있습니다.
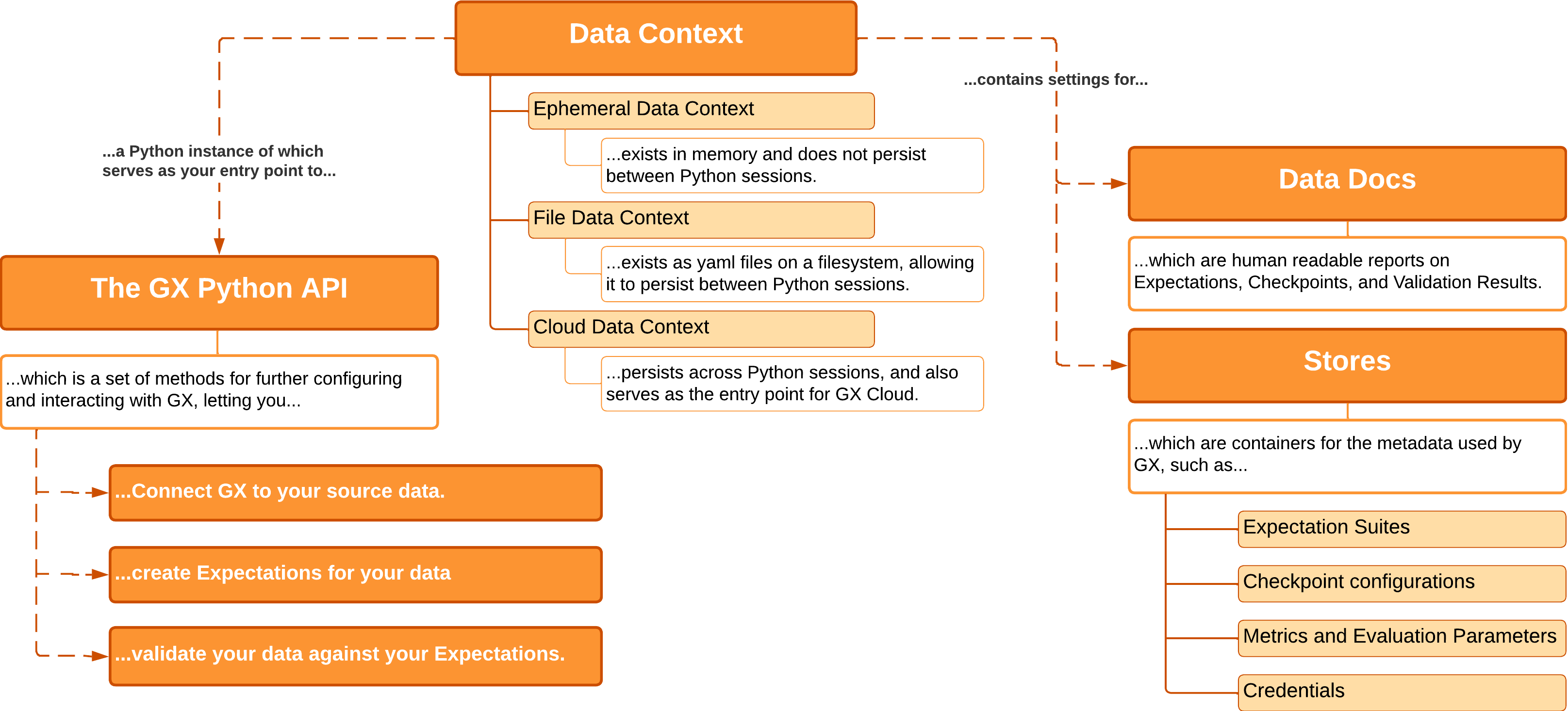
Data Context는 세 가지 종류가 있습니다.
- Ephemeral Data Context: In-Memory 내에 존재하는 Data Context 입니다. GX Context를 실행하는 Python Session 외에서는 존재 하지 않습니다.
- File Data Context: File 형태로 Configuration을 설정 하는 방식입니다. GX Context를 실행하는 Python Session 간 해당 설정을 공유 할 수 있습니다. 큰 프로젝트를 관리 한다면 권장 하는 형식 입니다.
- Cloud Data Context: GX Cloud를 사용 할 때만 해당합니다. GX Cloud에 Context를 저장하는 형태 입니다.
Stores
Data Context는 각 Core Concepts에서 필요한 저장 공간에 대한 정보들도 지정 해 줄 수 있습니다. 저장 공간으로는 다음을 사용 할 수 있습니다.
- Local File System
- Amazon S3
Store의 종류는 다음과 같습니다.
- Expectation Store: 데이터 검증을 담당하는 Expectation 정보를 저장합니다.
- Validation Store: 데이터 검증 결과를 저장합니다.
- Checkpoint Store: Checkpoint의 메타 데이터를 저장합니다.
- Data Docs Store: Data Docs를 저장합니다.
- Metric Store: Anomaly Detection을 위해 사용 되며, 계산 완료 된 Metric (e.g. 열의 평균, 레코드 수)를 저장 한 후, 데이터의 추이를 분석 하는데 사용 됩니다.
Data Docs
Data Docs를 이용하여 Great Expectations Application으로 생성 된 데이터 (Data Validation, Data Profiling 결과 등)를 HTML 문서로 확인 할 수 있습니다.
원하는 File System에 호스팅 하여 사용 가능합니다.
Data Sources
Data Sources는 Great Expectations와 실제 데이터 (Local file, S3, HDFS, RDBMS 등)를 연결 해 주는 Component입니다.
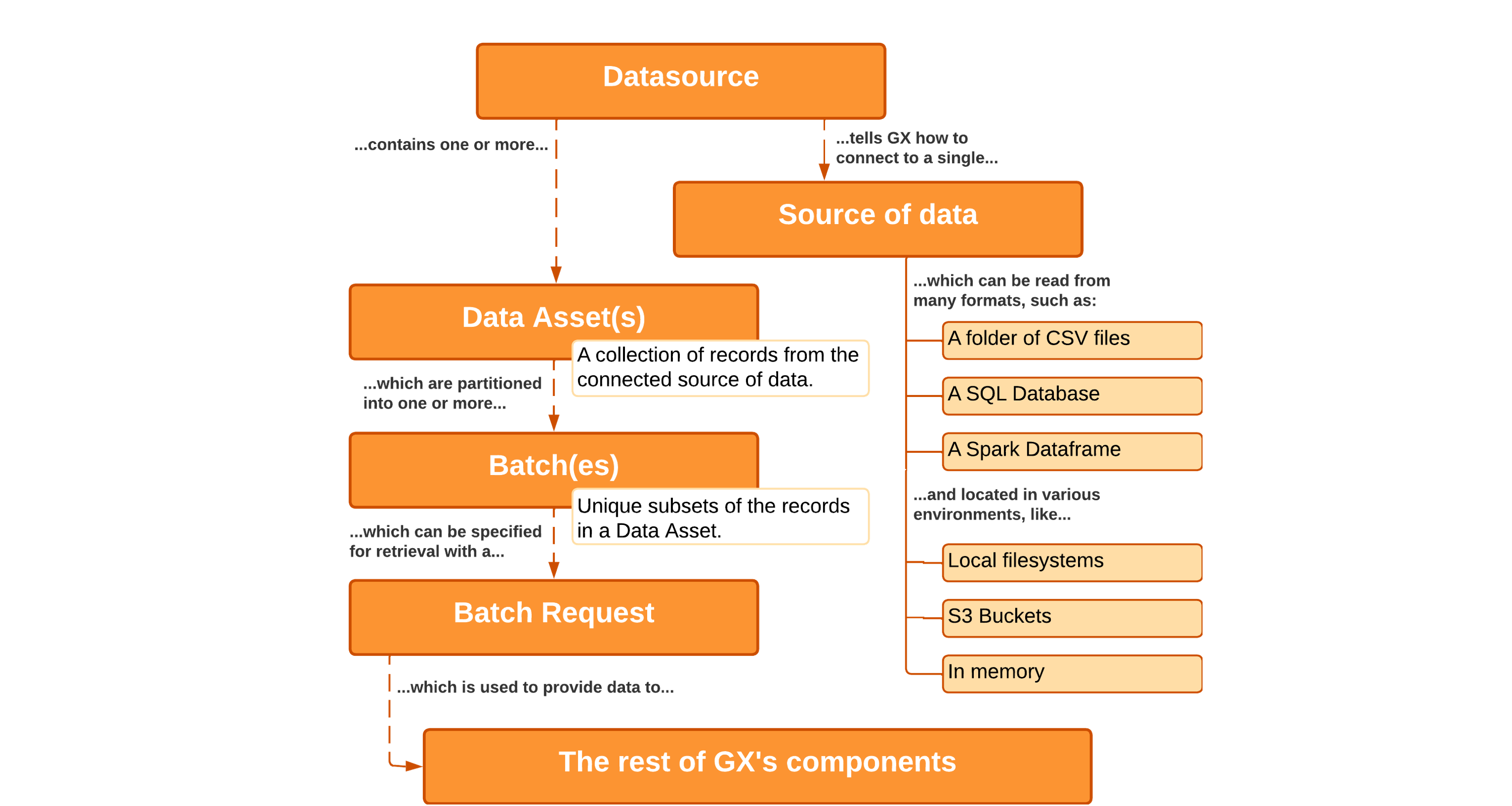
Data Asset(s)
Data Asset은 Data Sources 내의 Data Record의 추상적인 모음 입니다. Data Asset > Batch > Batch Request로 Hierarchy가 설정 되어 있습니다.
Batch(es)
Batch는 Data Asset의 고유한 부분 집합입니다. 예를 들면 특정 테이블을 Data Asset이라고 가정 하였을 때, month, day, hour 등의 partition으로 나누어진 데이터가 Batch라고 볼 수 있습니다.
Batch Requests
Great Expectations Application에서 한 개 이상의 Batch 데이터를 가져올 수 있습니다. Batch 객체를 가져와, Batch Requests로 파티션 별 데이터를 추출 하여, 이를 추후 Expectations Suite에서 사용, 검증 로직을 수행 하는 방식으로 사용 할 수 있습니다.
Expectations
Expectations는 데이터를 검증하는 컴포넌트입니다. 입력 되는 데이터에 대해 (Batch) 검증을 수행 합니다.
Expectation Suites
Expectation Suites는 Expectation의 집합입니다. Great Expectations에서는 Expectation Suites에 있는 Expectation들을 바탕으로, Data Verification을 수행합니다.
Data Assistants
Data Assistant는 Batch Data를 분석 하여 Expectation Suites를 빠르게 생성 할 수 있도록 돕는 도구입니다.
Use Case는 Automatic Constraints Suggestion등이 있습니다.
Checkpoints
Checkpoint는 Great Expectations에서 데이터를 검증하는 수단입니다. Data Batch와 Expectation Suites를 묶은 추상 계층입니다.
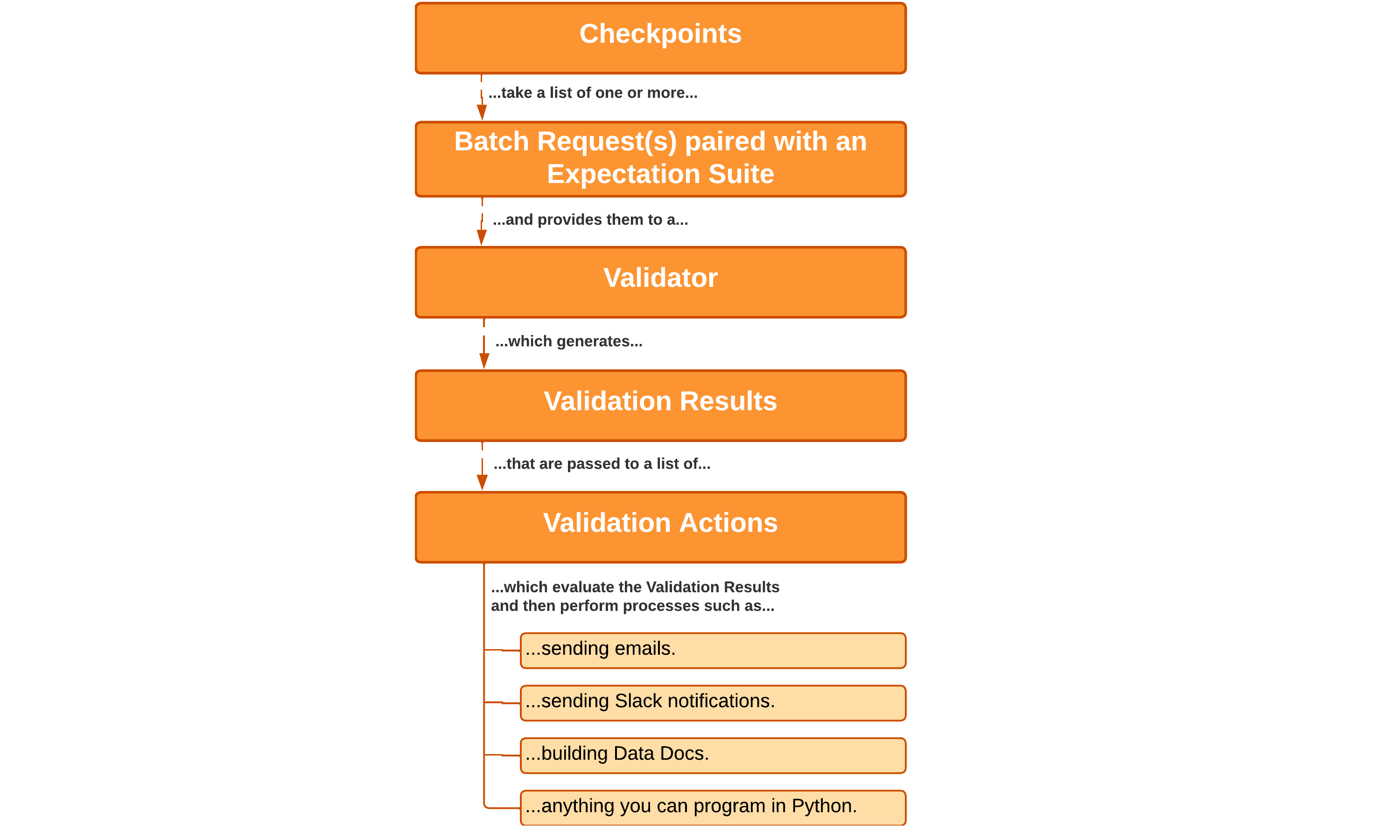
Validation Results
Checkpoint를 통해 수행한 Validation 결과 입니다. Data Context를 통해 Data Docs로 Export 가능 합니다.
Actions
Validation Result에 따라서, 사용자가 설정한 Action을 수행 할 수 있습니다. Email Notification, Slack Notification 등을 수행 할 수 있습니다.
마치며
이렇게 간단하게 Great Expectations가 필요 한 이유와, 핵심 컨셉에 대해서 알아 보았는데요. 다음 시간에는 실제 코드로 작성 해 보고, 실제로 어떻게 반환 되는지 확인 해 보는 시간을 가져보도록 하겠습니다.
긴 글 읽어 주셔서 감사합니다.