안녕하세요? 오늘은 HDFS의 Architecture에 대해서 알아 보도록 하겠습니다. Hadoop Distributed File System(HDFS) 는 상용 하드웨어에서 동작하게 만든 오픈소스 SW입니다. 장애 발생에 강하며, 저비용 하드웨어 안에서도, 잘 작동 하게 설계 되었습니다. 또한, 많은 데이터 셋을 지닌 어플리케이션에 적합하며, 높은 throughput을 가지고 있습니다.
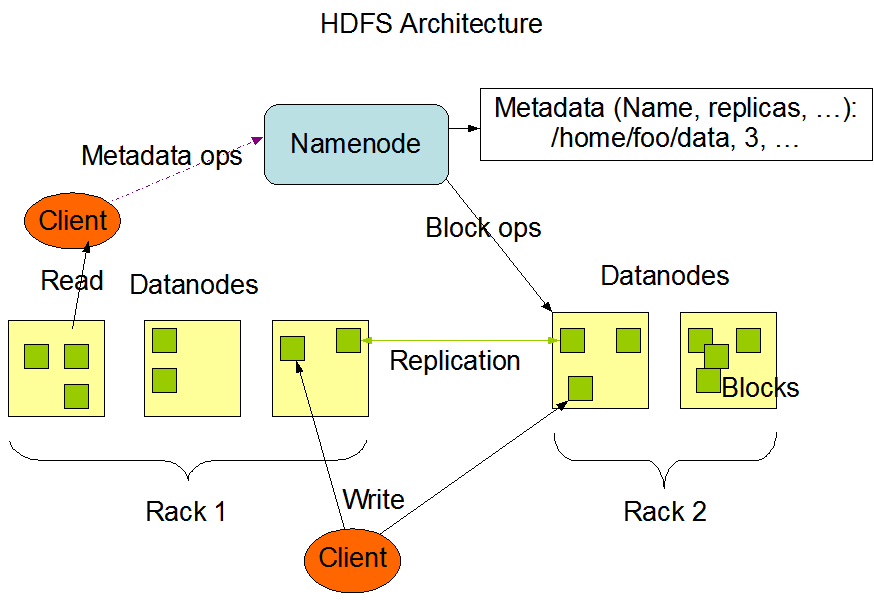
HDFS 구성
Assumptions and Goals
HDFS는 다음과 같은 것들을 가정하고, 그에 맞는 목표들을 가지고 있습니다.
- Hardware Failure
- 많은 수의 component로 제작된 클러스터 라면, 일부 component는 작동하지 않을 것을 의미합니다.
- 그렇기에, 빠른 이상 감지와, 빠르고 정확한 복구가 HDFS의 핵심입니다.
- Streaming Data Access
- HDFS를 사용하는 어플리케이션은 streaming access의 방식을 주로 사용 합니다.
- HDFS는 batch processing을 위해 설계 되었습니다. low latency보단, high throughput에 중점을 둡니다.
- Large Data Sets
- HDFS를 사용하는 어플리케이션은 많은 데이터를 다룹니다. 거의 테라 바이트 단위..
- 높은 집계 데이터 대역폭을 제공하고, 단일 클러스터에서 수백 개의 노드로 확장 가능하여, 단일 인스턴스는 수천만 개의 파일을 지원하도록 합니다.
- Simple Coherency Model (단순 일관성 모델)
- HDFS 애플리케이션은, 한 번 쓰고, 여러 번 읽는 액세스 모델이 권장 될니다.
- 일단 생성되고 쓰여지고 닫힌 파일은 추가 및 자르기를 제외, 변경 될 필요가 없습니다.
- 파일 끝 컨텐츠 추가는 가능하나, random access는 불가능 합니다.
- 이는 데이터 일관성 문제를 단순화 시키며, 높은 처리량 데이터 액세스를 가능케 하여, MapReduce, Web Crawling에 최적화 시킵니다.
- “Moving Computation is Cheaper than Moving Data”
- 데이터 세트의 크기가 크면, 데이터가 근처에 있을 때, 계산이 효과적입니다. (데이터의 지역성)
- 이는 네트워크 정체를 최소화하며, 시스템의 전체 처리량을 증가 시킨다.
- 데이터를 응용 프로그램의 위치로 옮기는게 아닌, 데이터가 있는 위치에 더 가깝게 계산을 마이그레이션 하는 것이 더 나은 경우가 많다고 가정합니다.
- Portability Across Heterogeneous Hardware and Software Platforms (H, S/W 플랫폼간 이식성)
- 한 플랫폼에서 다른 플랫폼으로 이동하기 쉽게 설계합니다.
NameNode & DataNode
HDFS는 master/slave architecture를 가지고 있습니다. 요약하면 Namenode는 master 역할로, 데이터를 관리하는 역할을, Datanode는 자신에게 할당된 데이터 블록을 처리하는 역할을 합니다.
NameNode
- 마스터 서버의 역할을 합니다.
- File system namespace와, 클라이언트의 파일 액세스를 규제하는 역할을 담당 합니다.
- file system namespace의 변동 내역은 NameNode에 저장 됩니다.
- replication factor에 대한 정보들 또한 보관하고 있습니다.
- 블록 복제에 관한 모든 결정을 내리며, 클러스터의 각 DataNode에서 정기적으로 Heartbeat 및 Blockreport를 수신 합니다.
- 클러스터 내, 단 한 개만 존재하며, 고가용성을 위해, 예비 NameNode도 만들어 놓는 것이 좋습니다.
- 파일 열기, 닫기, 파일/폴더 이름 수정과 같은 operation을 수행 합니다.
- DataNode에 대한 블록의 Mapping도 결정 합니다.
DataNode
- HDFS에서 파일이 저장 될 때, 한 개 이상의 block으로 나누어 지고, 이들은 DataNode 들에 적재 됩니다.
- 그렇기 때문에, 파일을 저장 할 때, 적절한 Block 크기를 고려 하여야 합니다. 사용 하는 입장에서는 Block을 그대로 가져와 병렬 처리를 수행 할테니까요!
- DataNode는 system’s clients의 파일을 읽고, 쓰는 역할을 합니다.
- NameNode로 부터 온, block 생성, 삭제, 복제를 수행 합니다.
- 실제 배포에서는 DataNode를 한 곳에 때려 박지 않습니다. (여러 서버 렉에 저장)
The File System Namespace
- HDFS는 전통적인 계층형 파일 구성을 지원 합니다.
- 즉, 폴더를 생성하고, 그 안에 파일을 집어 넣는 것이 가능 하다.
- HDFS는 hard link와, soft link를 지원 하지 않지만, 배제 하지는 않습니다.
- naming도 대부분 비슷하게 지원 합니다만, 몇 개의 경로와 이름은 예약 되어 있습니다. 이는 암호화, 스냅샷과 관련이 있습니다. (e.g. /.reserved and .snapshot)
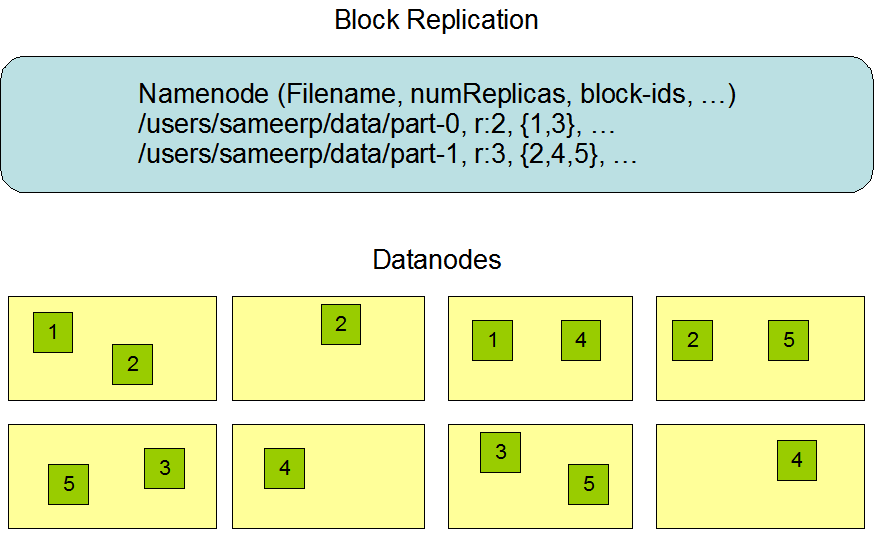
Data Replication
데이터 고가용성
HDFS는 데이터 고가용성을 위해 Data Replica를 여러 개의 노드에 삽입하는 방식을 사용 합니다.
Data Replication
- HDFS는 매우 큰 파일들을 클러스터 내에 안전하게 저장 되도록 설계 되었습니다.
- fault tolerance를 지원함. block size와 replication factor는 파일 마다 설정 가능합니다.
- 마지막 블록을 제외한 파일의 모든 블록은 동일한 크기로 저장 됩니다.
- 가변 길이 블록에 대한 지원이 추가 된 후, 블록 크기를 끝까지 안채워도 새 블록을 시작 할 수 있습니다.
- Application에서 파일 생성 시, 파일의 복제본 수를 지정 할 수 있습니다. 블록 크기도요!
- 쓰기는 1회이며, 항상 하나의 작성자만 존재 한다.
Replica Placement: The First Baby Steps
- 복제본 배치는 HDFS 안정성과 성능에 매우 중요한 요소 입니다. 이를 최적화 하여 성능을 올리는 것이, HDFS의 특징입니다.
- 이는 많은 튜닝과 경험을 필요로 합니다. rack-aware replica placement의 목적은, 데이터의 안정성, 가용성 및 네트워크 대역폭 활용도를 개선하는 것입니다.
- 현재의 replica placement policy는 이를 목적으로 하고 있으며, 이 정책을 구현하는 단기 목표는 프로덕션 시스템에서 이를 검증하고, 동작에 대해 자세히 알아보고, 보다 정교한 정책을 테스트하고 연구하기 위한 기반을 구축 하는 것입니다.
- NameNode는 Hadoop rack awareness를 통해, DataNode가 속하는 랙 ID를 결정합니다. 대부분 replica를 고유한 rack에 배치 하는 것이 대부분입니다.
- 이래야 데이터 손실 방지 및 여러 rack의 대역폭을 사용할 수 있습니다. Component 장애 시 부하를 쉽게 분산 가능 하고요.
- 하지만, 블록을 여러 랙으로 전송 하는 것이, write 비용을 증가 시킨다는 단점이 있습니다.
- 그래서 3개의 replica를 놓는다고 하면 (복제본의 1/3은 한 노드에 있고, 복제본의 2/3은 한 랙에 있으며, 나머지 1/3은 나머지 랙에 고르게 분산 됨.)
- a rack의 A datanode 안에
- a rack의 B datanode 안에
- b rack의 C datanode 안에
- 이렇게 해야, 일반적으로 write 성능을 향상시킬 수 있으며, 랙 사이에서 발생하는 write 트래픽을 줄일 수 있습니다.
- replication factor가 3 이상인 경우, 랙당 복제본 수를 상한선 (기본적으로 (복제본 - 1) / 랙 + 2) 이하로 유지하는 방향으로, 4번째 이후 복제본의 배치가 무작위로 결정 됩니다.
- 최대 복제본의 수는 DataNode의 총 갯수입니다. (하나의 DataNode 내 동일 Replica를 허용 하지 않음)
Recent Posts in Data-Engineering Category