안녕하세요? 박민재입니다. 오늘은 Iceberg Table을 관리하는 방법을 Metadata Table의 사용을 중심으로 깊게 알아 보도록 하겠습니다.
Apache Iceberg의 경우에는 Metadata Table 기능을 매우 강력하게 지원합니다. 이를 통해 Iceberg Table을 운영을 쉽게 수행 할 수 있죠. 예를 들어, Table의 Evolution이 어떻게 진행 되었는지, 파일들이 어떻게 Partitioning 되어 운영 되는지, Partition별 File의 갯수, 특정 File 내에서 Column의 Upper Bound, Lower Bound 등이 어떻게 되는지 등을 기록할 수 있어요.
또한 메타데이터를 SHOW PARTITION 같은 Hive Dialect가 아닌, 대부분의 SQL 엔진에서 사용할 수 있는 형태로 제공 하고 있고요.
SELECT * FROM catalog.table.history AS OF VERSION 1059035530770364194크게 다음과 같은 Metadata Table 들을 지원하고 있습니다.
- history: Snapshot 생성 이력 기록
- metadata_log_entries: Table Update 중 생성 된 Metadata File 로깅
- snapshots: Snapshot 정보 기록
- files: Table 내 현재 Data File의 정보
- manifest: Manifest File에 대한 정보
- partitions: Partition에 대한 정보
- refs: Snapshot의 Reference
- entries: Manifest의 Entry (Manifest -> File)
history
history Metadata Table은 Table이 어떻게 evolution 되었는지 History를 기록하는 Table입니다.
Snapshot 정보를 기록 하며, 이는 데이터 복구 및 버전 제어에 사용 할 수 있습니다. 해당 스냅샷에 대해서 SQL 쿼리를 수행 하는 형식으로 사용합니다.
- made_current_at: 해당 스냅샷이 Current Snapshot으로 설정된 시점의 Timestamp
- snapshot_id: 각 스냅샷의 고유 ID.
- parent_id: 해당 Snapshot을 만들기 위해 사용한 이전 스냅샷의 식별자(존재하는 경우).
- is_current_ancestor: 해당 스냅샷이 현재 스냅샷의 조상인지 여부를 나타냅니다.

아래는 history 테이블에 특정 시점 이전의 Snapshot에 대해 쿼리 하는 예제 입니다.
SELECT snapshot_id
FROM catalog.table.metadata_log_entries
WHERE made_current_at < '2023-07-11 00:00:00'
ORDER BY made_current_at ASC이를 통해서 Rollback이 수행 되었는지 여부도 도출이 가능합니다.
- 두 개 이상의 동일한
parent_id를가지고 있는가? - 그 중 하나만이
is_current_ancestor가true인가? (Current Snapshot의 조상 인지 여부. 만약, 롤백 이후 다시 Snapshot이 생성 되었다면, 하나만 Current Snapshot의 조상에 해당 할 것)
metadata_log_entries
metadata_log_entries는 Table Update 중에 생성된 Metadata File을 로깅하여 Table Evolution을 추적 합니다. 이를 통해, snapshot이 어떤 시점의 Metadata File들을 가지고 있었는지 확인 할 수 있습니다.
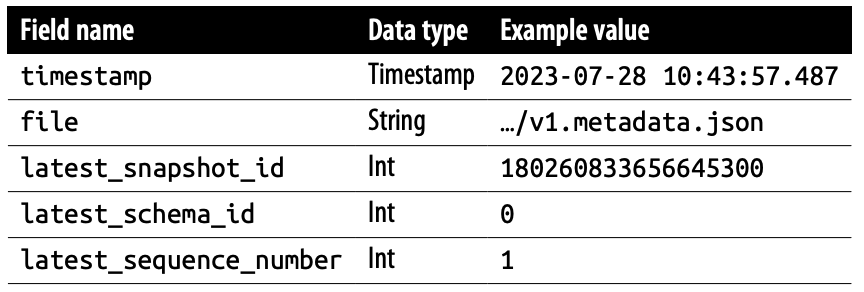
- timestamp: Metadata가 업데이트된 정확한 날짜와 시간을 기록 함
- file: 파일 위치
- latest_snapshot_id: Metadata가 업데이트 된 시점의 최신의 Snapshot의 ID
- latest_schema_id: Metadata가 업데이트 된 시점에서 사용 된 최신의 Schema ID
- latest_sequence_number: Metadata File의 Sequence 번호
응용하는 예시로는, Schema 변경이 일어나기 직전의 최근 Snapshot을 추출하여, Schema 변경 전으로 Rollback 하는 데 사용하는 예제가 있습니다.
WITH Ranked_Entries AS (
SELECT
latest_snapshot_id,
latest_schema_id,
timestamp,
ROW_NUMBER() OVER(PARTITION BY latest_schema_id ORDER BY timestamp DESC) as row_num
FROM
catalog.table.metadata_log_entries
WHERE
latest_schema_id IS NOT NULL
)
SELECT
latest_snapshot_id,
latest_schema_id,
timestamp AS latest_timestamp
FROM
Ranked_Entries
WHERE
row_num = 1
ORDER BY
latest_schema_id DESC;snapshots
snapshots는 Snapshot의 정보를 담고 있는 테이블 입니다. Version 관리, Time Travel, 증분 처리, 과거 추적 등등을 수행 할 수 있습니다.
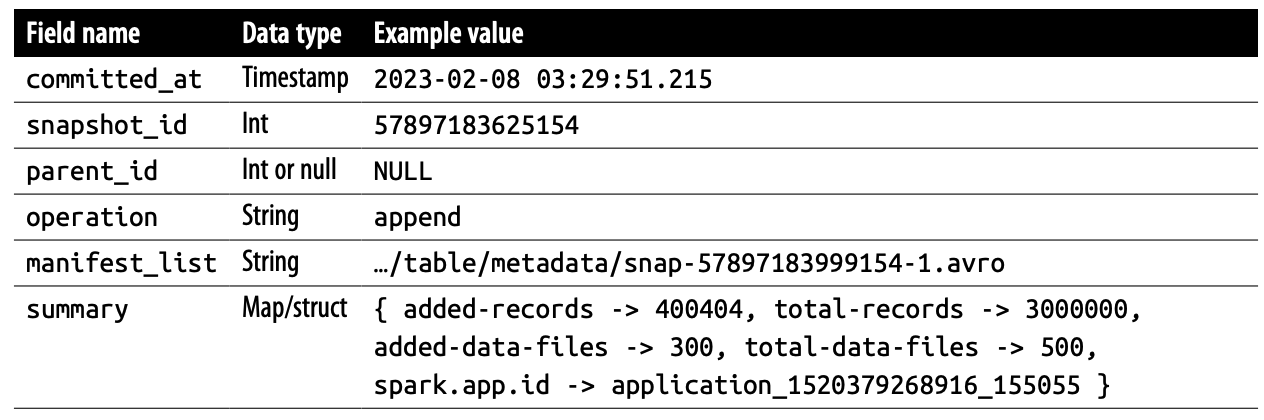
- committed_at: Snapshot이 생성된 시점 입니다.
- snapshot_id: Snapshot의 고유 ID입니다.
- parent_id: 해당 Snapshot의 부모 Snapshot ID 입니다. 해당 Snapshot이 어디서 부터 만들어졌는지 알 수 있습니다.
- operation: 어떤 연산으로 만들어 졌는지를 나타냅니다. (예시: APPEND and OVERWRITE)
- manifest_list: 해당 Snapshot이 가지고 있는 manifest_list 경로를 나타냅니다.
- summary: 해당 Snapshot의 요약 정보입니다.
해당 Query를 통해서, Table 내에 있는 Snapshot ID 별로 몇 개의 Record 들이 추가 되었는지 확인 할 수 있습니다. 혹은, 하루에 몇 개의 Snapshot이 만들어 졌는지도 확인 할 수 있어요.
SELECT
committed_at,
snapshot_id,
summary['added-records'] AS added_records
FROM
catalog.table.snapshots;
SELECT
operation,
COUNT(*) AS operation_count,
DATE(committed_at) AS date
FROM
catalog.table.snapshots
GROUP BY
operation,
DATE(committed_at)
ORDER BY
date;files
files는 테이블 내의 현재 데이터 파일을 보여주며, 각 데이터 파일의 위치, 형식, 내용, 파티셔닝 정보등을 제공 합니다.
다른 Table의 정보들과 함께 이용하여 사용 하면, Data Lineage Tracking, Schema Evolution 등, 다양한 케이스를 대응 할 수 있습니다.
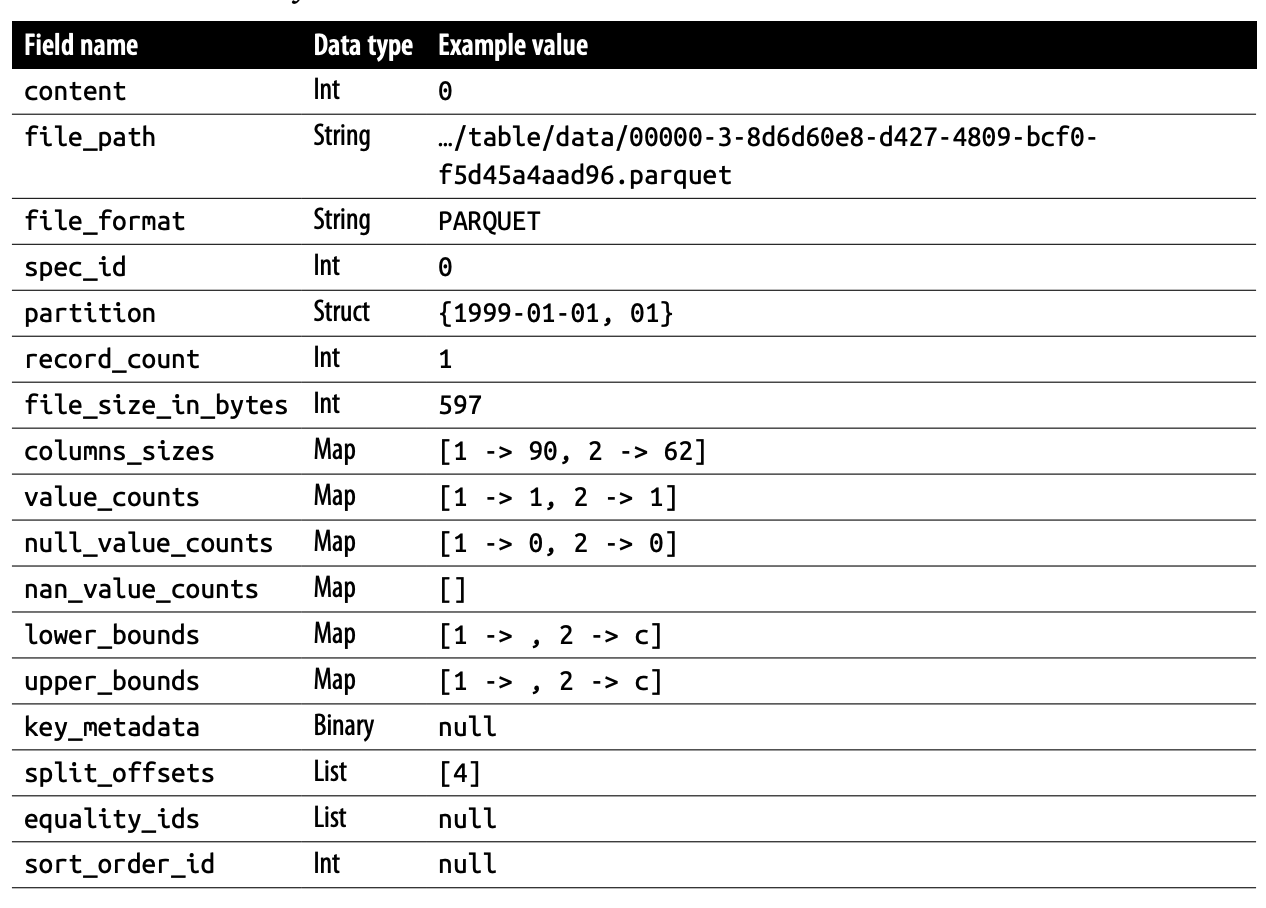
- content: datafile (0), position delete file (1), equality delete file (2)
- file_path: 파일 경로
- file_format: 파일 형식
- spec_id: 파일이 준수하는 Partition Spec ID. 데이터가 어떻게 분할 되는지 참조함
- partition: 파티션 정보
- record_count: 레코드 갯수
- file_size_in_bytes: 파일 사이즈
- columns_size: Column 당 파일 크기
- value_counts: Column당 non-null인 count
- null_value_counts: Column당 null인 count
- nan_value_counts: Column당 NaN (Not a Number)인 count
- lower_bounds: Column별 최소값
- upper_bounds: Column별 최대값
- key_metadata: Spark, Flink Engine에서 용도에 맞게 구현 해서 넣은 Binary Metadata. 없는 경우가 많다.
- split_offsets: 병렬 처리를 위해서, file split 위치를 기록
- equality_ids: Equality Delete에서 사용 되는, row id 집합
- sort_order_id: Sort Order 관련 ID
- readable_metrics: File Metric을 제공 합니다.
이를 통해 많은 것을 할 수 있는데요, 어떤 Partition을 Merge 하면 좋을지를 결정 하기 위해서, Partition별 평균 file_size를 측정 할 수도 있고요.
SELECT
partition,
COUNT(*) AS num_files,
AVG(file_size_in_bytes) AS avg_file_size
FROM
catalog.table.files
GROUP BY
partition
ORDER BY
num_files DESC,
avg_file_size ASC혹은, 특정 Column에 null value가 있는 지도 확인 해 볼 수 있습니다.
SELECT
partition, file_path
FROM
catalog.table.files
WHERE
null_value_counts['3'] > 0물론, 테이블 내의 File Total Size도 측정 할 수 있어요.
SELECT sum(file_size_in_bytes) from catalog.table.filesTime Travel 기능을 통해, 이전 Snapshot에서 가지고 있는 File의 목록 또한 한 눈에 볼 수 있습니다.
SELECT file_path, file_size_in_bytes
FROM catalog.table.files
VERSION AS OF <snapshot_id>;all_data_files
유사한 Table인 all_data_files가 있습니다. 이는 똑같은 Datafile로 스냅샷이 두 개 이상 만들어 졌다면 중복 될 수 있는 구조입니다.
file과 field가 같습니다.
manifests
manifests Metadata Table은 Manifest File에 대해서 자세하게 기술 되어 있는 Metadata Table 입니다.
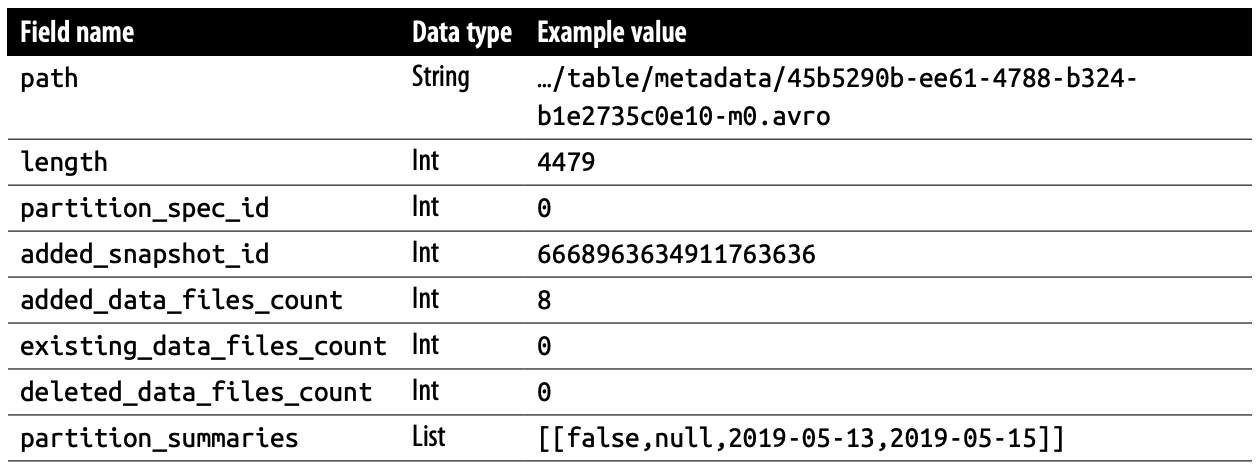
- path: manifest file의 위치
- length: manifest file의 크기
- partition_spec_id: 해당 manifest file의 Partition Spec의 ID
- added_snapshot_id: 해당 manifest file이 추가 될 때 같이 만들어진 Snapshot ID
- added_data_files_count: 해당 manifest file로 추가 된 file count
- existing_data_files_count: 해당 manifest file 이전, 기존에 있던 file count
- deleted_data_files_count: 해당 manifest로 삭제된 file count
- partition_summaries (최신 버전의 경우 partitions로 이름이 변경 됨): Partition Value에 따라 각각 contains_null, contains_nan, lower_bound, upper_bound를 제공 합니다.
manifest를 압축 해야하는 경우에는 평균보다 낮은 Manifest File에 대해서 압축 하기 위해, 이를 추출하는 예제도 존재 합니다.
WITH avg_length AS (
SELECT AVG(length) as average_manifest_length
FROM catalog.table.manifests
)
SELECT
path,
length
FROM
catalog.table.manifests
WHERE
length < (SELECT average_manifest_length FROM avg_length);데이터의 추가 및 삭제 추이도 확인 할 수 있습니다.
SELECT
added_snapshot_id,
SUM(added_data_files_count) AS total_added_data_files
FROM
catalog.table.manifests
GROUP BY
added_snapshot_id;
SELECT
added_snapshot_id
FROM
catalog.table.manifests
WHERE
deleted_data_files_count > 0;all_manifests
이 또한, all_data_files 와 동일 하게 중복해서 나올 수 있는 구조 입니다. manifest는 여러 개의 Snapshot에 포함 될 수 있습니다.
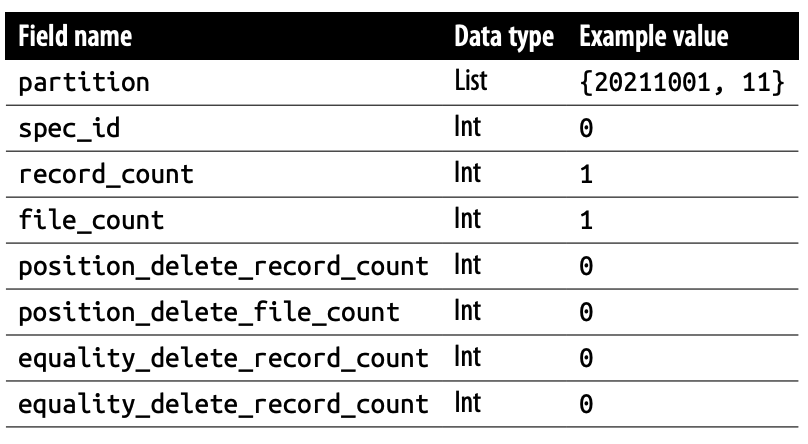
partitions
partitions 는 Partition에 대한 정보를 나타냅니다.
- partition: Partition Value를 나타냅니다. Query Processing에 사용 됩니다.
- spec_id: Partition Spec ID를 나타냅니다.
- record_count: 파티션 내 총 레코드 수를 나타냅니다. Repartition 정책을 세울 때 좋습니다.
- file_count: 파티션 내 File Count 갯수를 나타냅니다.
- position_delete_record_count: 파티션에 position delete 된 record 갯수
- position_delete_file_count: 파티션에 있는 position deletefile 갯수
- equality_delete_record_count: 파티션에 equality delete 된 record 갯수
- equality_delete_file_count: 파티션에 있는 equality deletefile 갯수
다음과 같이, Partition 별 File Count를 확인 하거나
SELECT partition, file_count FROM catalog.table.partitionsFile Size를 확인 하여, 추가 Partition Evolution이 필요한지에 대한 여부도 판단 할 수 있습니다.
SELECT partition, SUM(file_size_in_bytes) AS partition_size
FROM catalog.table.files
GROUP BY partitionrefs
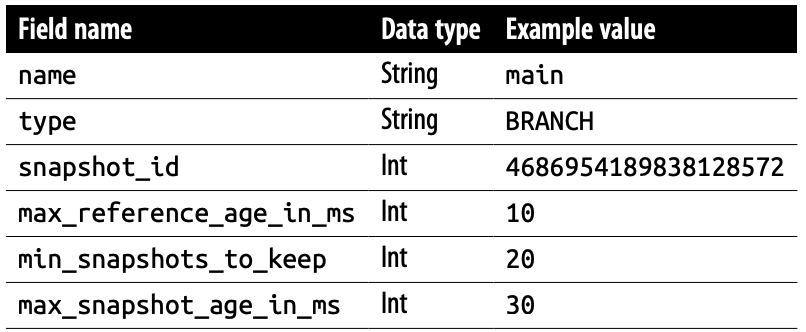
Snapshot의 Reference를 기록 합니다. refs는 특정 Snapshot의 Pointer로 간주가 되며, Snapshot을 Branching + Tagging 하기 위해서 사용합니다.
FYI) 추후 설명 할테지만, TAG / BRANCH에 Retention을 적용 할 수 있습니다.
- name: reference의 이름
- type: reference의 형식 (BRANCH or TAG)
- snapshot_id: reference의 Snapshot ID
- min_reference_age_in_ms: Snapshot을 참조할 수 있는 기간을 밀리초 단위로 표현
- min_snapshots_to_keep: Table에 최소한으로 남길 Snapshot 수의 하한
- max_snapshot_age_in_ms: 참조 된 Snapshot을 남길 수 있는 기간을 밀리초 단위로 표현
entries
Manifest의 entry로 사용 합니다. (Manifest → flie)
- status: datafile (0), position delete file (1), equality delete file (2)
- snapshot_id: 해당 Manifest File의 Snapshot ID
- sequence_number: 작업 순서를 나타냄. 추가, 수정 또는 삭제 여부에 관계 없이 변경 사항 있을때 마다 증가
- data_file
- file_path: 파일 경로
- file_format: 파일 유형
- record_count: 레코드 갯수
- file_size_in_bytes: 파일 사이즈
- columns_size: Column 당 파일 크기
- value_counts: Column당 non-null인 count
- null_value_counts: Column당 null인 count
- nan_value_counts: Column당 NaN (Not a Number)인 count
- lower_bounds: Column별 최소값
- upper_bounds: Column별 최대값
- key_metadata: Spark, Flink Engine에서 용도에 맞게 구현 해서 넣은 Binary Metadata. 없는 경우가 많다.
- split_offsets: 병렬 처리를 위해서, file split 위치를 기록

Metadata Table Join
상기한 Metadata Table 들에 대해 Join하여 조회하는 방법으로, 원하는 데이터 들을 추출 할 수 있습니다.
- Snapshot 에서 추가된 File 전체 조회 (entries + files)
- 어떤 LifeCycle에서 파일이 삭제 되었는 지 확인 (entries + manifests)
- Partition Evolution 과정 확인 (entries + partition)
- 특정 branch의 file 모니터링 (refs + entries)
- 두 branch 사이의 차이 찾기 (refs + entries + files)
- 각 branch에서 쌓인 데이터 양 확인 하기 (refs + entries + files)
다음 시간에는 Branching & Tagging에 대해서 알아 보도록 하겠습니다.