안녕하세요? 박민재입니다. 오늘은 Iceberg Table을 관리하는 방법 중 하나인, Branching & Tagging 그리고 Rollback Action에 대해서 알아 보도록 하겠습니다.
Isolation of Changes with Branches
Iceberg에서는 git과 같은 방식으로 Branch를 만들어, 데이터 변경 사항을 관리 할 수 있습니다.
우리의 사례로 빗대어 보면 H/W 이슈, 혹은 Application 이슈를 통해서 데이터 오염 발생 시에 Branch 생성 후, 오염된 데이터를 수행 한 후에 Main에 merge 하는 형식으로 대응 하는 방법으로 사용 할 수 있습니다.
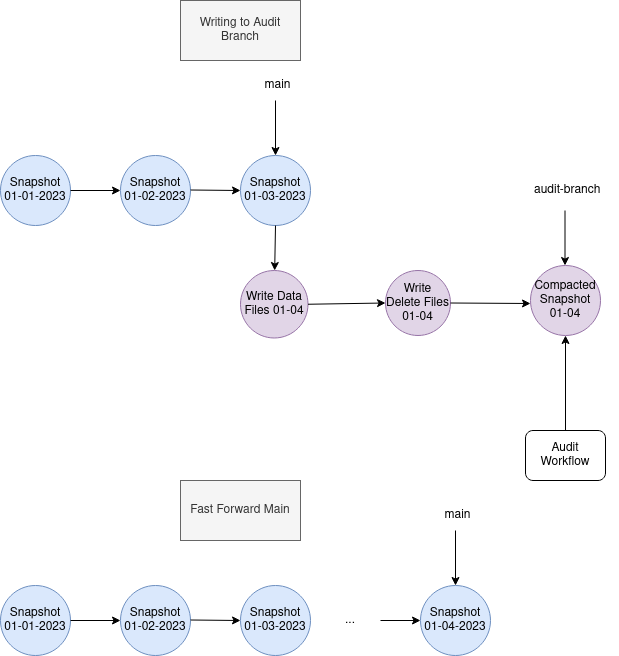
Table Branching and Tagging
Table Branching
Table Branching은 독립적인 Snapshot Lineage를 만들 수 있게 합니다. 각 Branch에 대한 설정도 가능한데요, 전 시간에 언급하였던 refs Table을 이용 하여 최대 스냅샷 수명, 브랜치에 존재해야 하는 최소 스냅샷 수에 대한 설정도 가능합니다.
Branch를 만들 수 있기 때문에, Prod 환경에서도 편하게 데이터 검증을 수행 할 수 있습니다. 나중에 합병하거나, 버리면 되니까요.
아래는 Java Code 입니다.
// Using Iceberg Java API
// String to be used as branch name
String branch = "ingestion-validation-branch";
// branch 생성
table.manageSnapshots()
.createBranch(branch, 3) // 특정 snapshot으로 부터 branch 생성
.setMinSnapshotsToKeep(branch, 2) // Snapshot을 몇 개 까지 keep 할 것인가?
.setMaxSnapshotAgeMs(branch, 3600000) // Snapshot을 얼마나 유지 할 것인가?
.setMaxRefAgeMs(branch, 604800000) // Branch의 수명은?
.commit();
// Branch에 데이터 작성
table.newAppend()
.appendFile(INCOMING_FILE)
.toBranch(branch) // 어떤 브랜치에 작성 할 것인지
.commit();
// Read from the branch for validation
TableScan branchRead = table
.newScan()
.useRef(branch);
// Main Branch에 생성 한 Branch 병합
table
.manageSnapshots()
.fastForward("main", "ingestion-validation-branch") // 만약 데이터가 검증이 완료 되었다면 fastForward 수행
.commit();SQL문으로도 수행 가능합니다.
-- Create the new branch
ALTER TABLE my_catalog.my_db.sales_data
CREATE BRANCH ingestion-validation-branch
RETAIN 7 DAYS
WITH RETENTION 2 SNAPSHOTS;
SET spark.wap.branch = 'ingestion-validation-branch';Tagging
Tagging은 명명된 참조라고 이해해 주시면 될 것 같습니다. 만약, 특정 Snapshot에 이름을 붙여서 관리 하고 싶을 경우에는, 이를 이용할 수 있습니다.
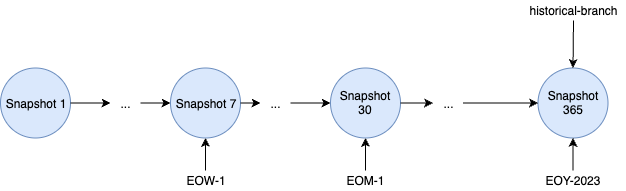
최적의 사용 시나리오는 아래와 같은, 감사 목적으로 중요한 Snapshot을 보관하거나, 문제 발생 시, 쿼리 재현에 도움을 주기 위해 특정 시점 Tagging을 하는 등에 사용 하는 것 입니다.
Java 코드 입니다.
// create a tag
String tag = "end-of-quarter-Q3FY23";
table.manageSnapshots()
.createTag(tag, 8) // create a tag out of snapshot 8
.setMaxRefAgeMs(tag, 1000 * 60 * 60 * 2486400000) // set the max age of the tag
.commit();
// Read from a tag
String tag = "end-of-quarter-Q3FY23";
Table tagRead = table
.newScan()
.useRef(tag);예제 SQL Code 입니다.
-- end of week snapshot. 1주일 보관
ALTER TABLE prod.db.table CREATE TAG `EOW-01` AS OF VERSION 7 RETAIN 7 DAYS;
-- end of month snapshot. 6개월 보관
ALTER TABLE prod.db.table CREATE TAG `EOM-01` AS OF VERSION 30 RETAIN 180 DAYS;
-- end of the year snapshot. 평생 보관
ALTER TABLE prod.db.table CREATE TAG `EOY-2023` AS OF VERSION 365;Rolling Back Changes
Iceberg에서는 Tag, Snapshot ID를 기준으로 Rollback 할 수 있는 함수를을 지원 합니다.
rollback_to_snapshot
Snapshot ID를 기준으로 테이블을 Rollback 할 수 있습니다. 테이블 이름과 롤백 하고자 하는 Snapshot의 ID를 이용 합니다.
spark.sql("CALL catalog.database.rollback_to_snapshot('orders', 12345)")rollback_to_timestamp
Timestamp를 기준으로 테이블을 Rollback 할 수 있습니다. 테이블 이름과 원하는 Timestamp를 입력 합니다.
spark.sql(s"CALL iceberg.system.rollback_to_timestamp('db.orders', timestamp('2023-06-01 00:00:00'))")set_current_snapshot
Currennt Snapshot의 ID를 변경 합니다. Rollback과 다른 점은, 설정 하고자 하는 Snapshot이 Current Snapshot의 조상이 아니어도 가능합니다.
// Update를 수행할 Table
val tableName = "db.inventory"
// 대상 Snapshot ID
val snapshotId = 123456789L
// current snapshot 변경
spark.sql(s"CALL iceberg.system.set_current_snapshot('$tableName', $snapshotId)")cherrypick_snapshot
Git의 Cherrypick 처럼, Current Snapshot에, Target Snapshot ID를 Cherry-picking 하여, 원본을 변경하거나 제거하지 않고 기존 Snapshot에서 새로운 Snapshot을 만듭니다.
Cherry-picking 하고자 하는 ID가 Append 혹은 Overwrite 연산 이어야 합니다.
// Cherry Pick
spark.sql(s"CALL iceberg.system.cherrypick_snapshot('db.products', 987654321)")