Intro
안녕하세요, 박민재입니다. 오늘은 Apache Iceberg의 Table에 수행 되는 쿼리가 최적의 성능으로 작동 될 수 있도록, File Compaction을 통해 이를 수행하는 방법에 대해 이야기 하는 시간을 가져 보도록 하겠습니다.
File Compaction
우리가 쿼리를 수행 시, Hive Metastore의 정보를 이용하더라도, 혹은 Iceberg의 Metadata 정보를 보더라도, 우리는 결론적으로 단일 파일을 읽는 과정이 필요 하게 됩니다. 하지만, 만약 1GB 정도의 Table을 읽는 데 있어, 정보가 10000개의 파일로 쪼개져 있다면 어떤 문제가 발생 할까요? 이를 넘어서 백 만개의 파일로로 쪼개져 있다면요?
그렇다면 우리는 파일 수 만큼의 File Operation을 수행 해야 될 것입니다. 10000개면 10000번의 File Open + Read를, 1000000개면 1000000번의 File Open + Read를 말이죠. 파일이 Hadoop 환경이라면 NameNode에 엄청난 부하를 가져오게 될 꺼에요.
그렇기 때문에 우리는 File Compaction이 필요하게 됩니다.
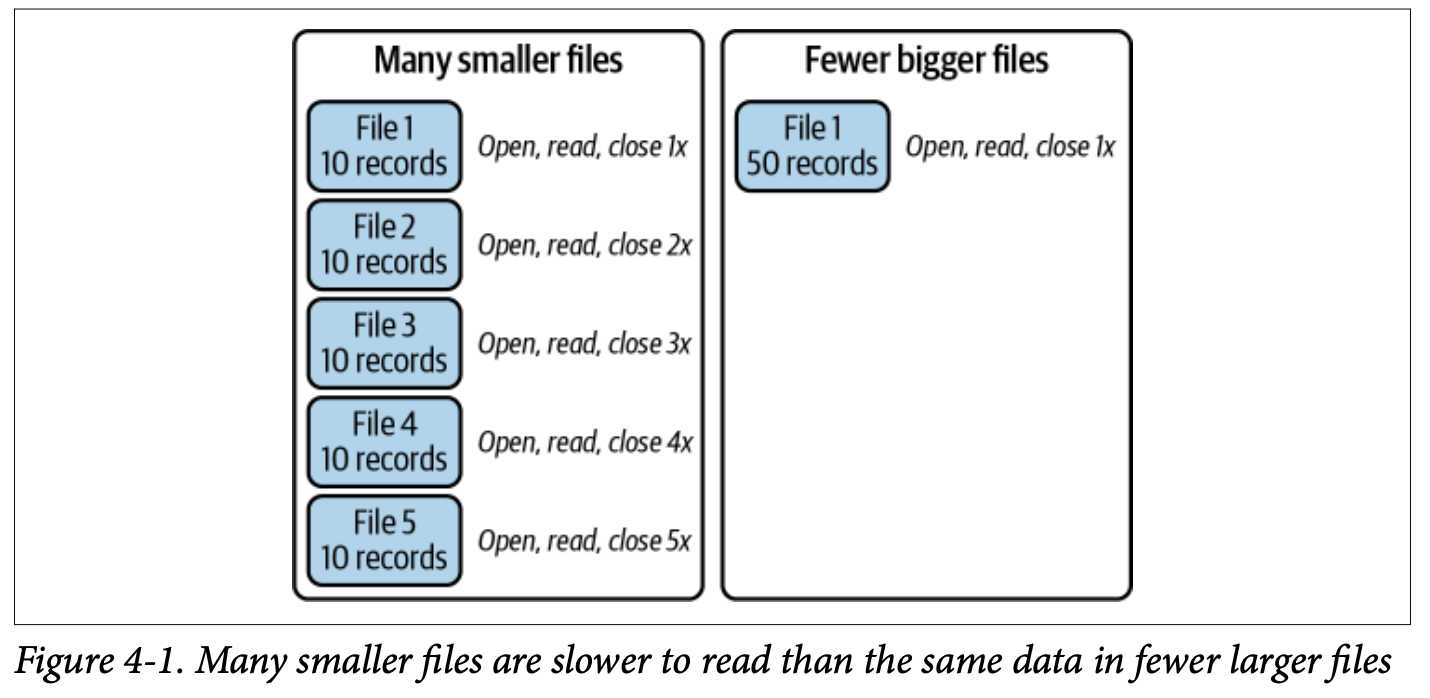
Example
우리는 Java, Python, 그리고 Spark SQL을 이용하여, SparkActions API를 호출하는 방식으로 File Compaction을 수행 할 수 있어요.
FYI) Iceberg에서는 Spark Engine을 주력으로 지원 하지만, 다른 Computing Engine에서도 구현만 완료 된다면 사용 가능합니다.
Java 예제입니다.
Table table = catalog.loadTable("myTable");
SparkActions
.get()
.rewriteDataFiles(table)
.option("rewrite-job-order", "files-desc")
.execute();
Table table = catalog.loadTable("myTable");
SparkActions
.get()
.rewriteDataFiles(table)
.sort()
.filter(Expressions.and(
Expressions.greaterThanOrEqual("date", "2023-01-01"),
Expressions.lessThanOrEqual("date", "2023-01-31")))
.option("rewrite-job-order", "files-desc")
.execute();SparkSQL 예제 입니다.
CALL catalog.system.rewrite_data_files(
table => 'musicians',
strategy => 'binpack',
where => 'genre = "rock"',
options => map(
'rewrite-job-order','bytes-asc',
'target-file-size-bytes','1073741824', -- 1GB
'max-file-group-size-bytes','10737418240' -- 10GB
)
)Options
대표적으로 Compaction 도중 다음과 같은 옵션을 삽입하여 수행 할 수 있습니다.
- Sort: 압축 과정에서 Sort를 수행 할 수 있습니다.
- zOrder: 압축 과정에서 zOrder Sort를 수행 할 수 있습니다.
- filter: 압축 과정에서 어떤 파일을 다시 쓸 지 선택할 수 있습니다. (ex: 특정 파티션에 대해서만 압축)
- option (단일 key-value), options (Map): 상기한 이외의 Option을 Map 형태로 추가 해 줄 수 있습니다.
- target-file-size-bytes: 원하는 압축 파일의 크기를 설정 해 줄수 있습니다. 기본 값은 Table 내의 property인 write.target.file-size-bytes (default: 512MB) 입니다.
- max-concurrent-file-group-rewrites: 동시에 작성할 최대 File Group의 갯수를 결정합니다.
- max-file-group-size-bytes: File Group의 최대 파일 크기의 합을 결정 합니다. 파일 크기가 메모리 크기 보다 큰 경우, OOM을 방지하기 위해서 주로 사용합니다.
- partital-progress-enabled: Partial Progress로 압축 작업이 진행 되며, 파일 압축 작업이 오래 걸리게 될 때 사용하면 좋은 옵션입니다. 파일 압축 중에 Commit을 허용 하며, 압축 중에 Read 쿼리가 발생 할 경우, 이미 압축된 File Group을 사용 할 수 있게 됩니다.
- partial-progress-max-commits: 전체 Partial Progress 작업이 완료 될 때 까지, 최대 Commit을 몇 회 허용할 지 설정 합니다.
- rewrite-job-order: 파일 압축 시, 어떤 File Group 먼저 Partial Progress를 수행 할 지 결정 합니다. (Option: bytes-asc, bytes-desc, files-asc, files-desc, none)
아래는 target-file-size-bytes: 1073741824 (1GB), max-file-group-size-bytes: 10737418240 (10GB)을 적용한 예시입니다.
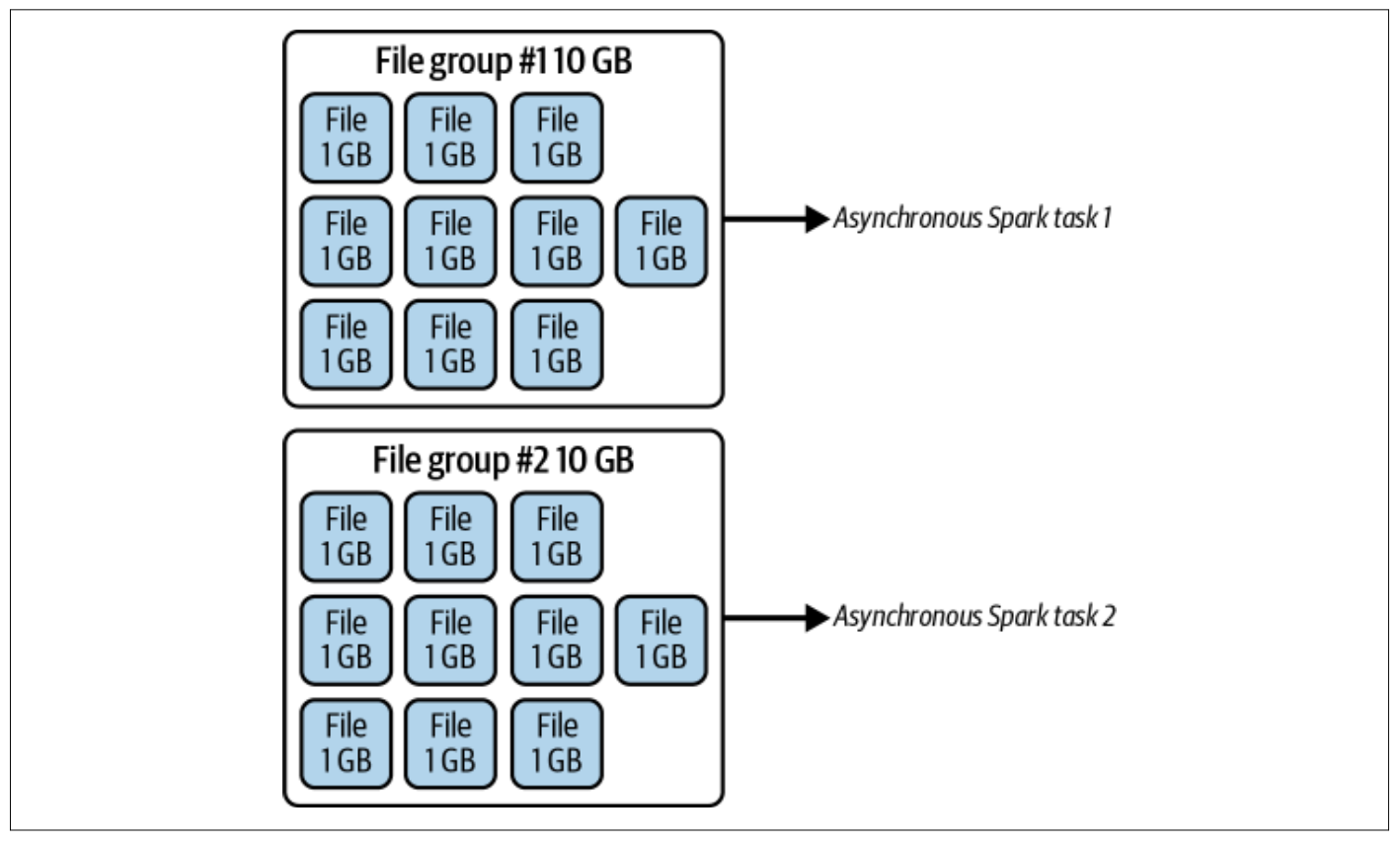
Partial Progress
Partial Progress는 특정 File Group에 대해 압축이 완료 되었을 때, 부분적으로 압축된 파일에 대해 다른 Query에서 접근을 허용하는 것입니다. 즉, 전체 압축 Action이 끝날 때 까지 기다리는 것이 아닌, File Group에 대해서 압축이 끝날 때 마다 Commit을 수행 하는 거에요.
이는 Trade-Off가 있는데요, 압축 과정 중간에 수행되는 Query에서도 File Compaction이 된 File에 대해 접근을 할 수 있게 하지만, 그만큼 더 많은 Snapshot이 생성되는 것이니, partial-progress-max-commits 같은 옵션으로 조정이 필요하게 됩니다.
Compaction Strategies
테이블의 파일을 압축하면서 선택 할 수 있는 많은 전략들이 존재합니다. 예를 들어, 다음과 같은 방법들이 있습니다.
Binpack
Binpack은 가장 기본적인 압축 방식입니다. 정렬없이 파일 압축만을 수행하는 방법으로, Spark Structured Streaming 같은 Streaming Application에서 생성하는 Data가 저장되는 Streaming Table 같은 곳에서 사용하는 것이 유리합니다.
만약, Streaming Table에 대해서 압축을 주기적으로 수행 한다면, Airflow, Serverless Function, Cronjob 등을 사용하는 것을 고려하는 것이 좋습니다.
- Pros: 제일 빠른 압축 속도를 자랑합니다.
- Cons: 하지만 데이터의 정렬이 존재하지 않는 관계로, 해당 테이블에 대한 Query시 Full Scan을 수행 해야 한다는 문제점이 있습니다.
CALL catalog.system.rewrite_data_files(
table => 'streamingtable',
strategy => 'binpack',
where => 'created_at between "2023-01-26 09:00:00" and "2023-01-26 09:59:59" ',
options => map(
'rewrite-job-order','bytes-asc',
'target-file-size-bytes','1073741824',
'max-file-group-size-bytes','10737418240',
'partial-progress-enabled', 'true'
)
)Sorting
파일 압축 시, 데이터를 단일 Column, 혹은 복수의 Column의 값을 바탕으로 정렬하여 저장하는 방식입니다. 쿼리 시 해당 Column을 사용하게 된다면, 성능이 올라가는 효과를 누릴 수 있습니다.
Table을 생성 할 때, 다음과 같은 방식으로 생성 하게 되면, Data가 Write 될 때, 자동으로 정렬 된 형태로 데이터가 삽입 되게 할 수 있습니다.
CREATE TABLE catalog.nfl_players (
id bigint,
player_name varchar,
team varchar,
num_of_touchdowns int,
num_of_yards int,
player_position varchar,
player_number int,
)
-- 해당 옵션을 통해 추후 입력되는 데이터는 정렬 된 채로 Write 됨
ALTER TABLE catalog.nfl_teams WRITE ORDERED BY team;하지만, 정렬 된 채로 Write가 된다고 하더라도, 애매하게 작은 파일로 흩뿌려진 채로 Append 된다면 성능이 악화될 수 있습니다. 따라서 Sort 옵션이 추가 된 Compaction을 통해, 더 작은 파일의 갯수로 Compaction 해 줄 수 있습니다.
CALL catalog.system.rewrite_data_files(
table => 'nfl_teams',
strategy => 'sort',
sort_order => 'team ASC NULLS LAST' -- team Column에 대해 오름차순으로 정렬. null 값인 경우는 마지막에 저장 되도록.
)
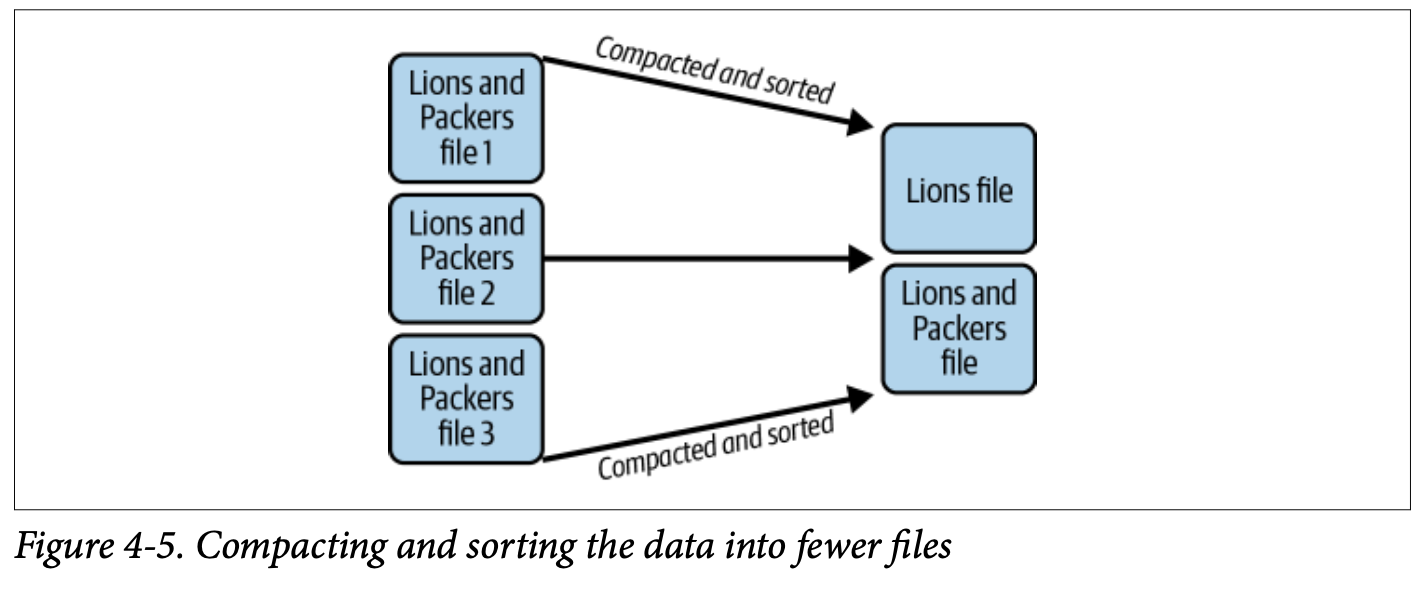
다중의 Column에 대해서도 수행해 줄 수 있습니다.
CALL catalog.system.rewrite_data_files(
table => 'nfl_teams',
strategy => 'sort',
sort_order => 'team ASC NULLS LAST, name ASC NULLS FIRST'
-- team Column에 대해 오름차순으로 && null 값인 경우는 마지막에 저장 되도록 정렬 후,
-- 동일한 team의 값을 가졌다면 name으로 오름 차순으로 null 값인 경우는 처음에 저장 되도록 정렬
)하지만, 위의 예제는 name column으로만 조회 할 때는 성능의 향상을 불러오기 어렵습니다. 보시다 싶이, 먼저 team column으로 정렬 한 이후, 같은 team column을 가진 값에 대해서 name column으로 sorting을 수행 하고 있기 때문에, name column의 데이터를 조회 하기 위해서는 사실 상 아래와 같은 상황에서는 거의 full scan을 해야 하죠.

Z-order
이를 위해 나온 구조는 Z-order 입니다. 복수 개의 Column으로 정렬 하였다 하더라도, Age로 조회 하든, Height으로 조회 하든 최소한의 성능을 보장하여 줍니다.
Age 1-50에 대해서 찾고 싶다면, 아래의 A,C 파일만 조회 하는 형식으로 말이죠.
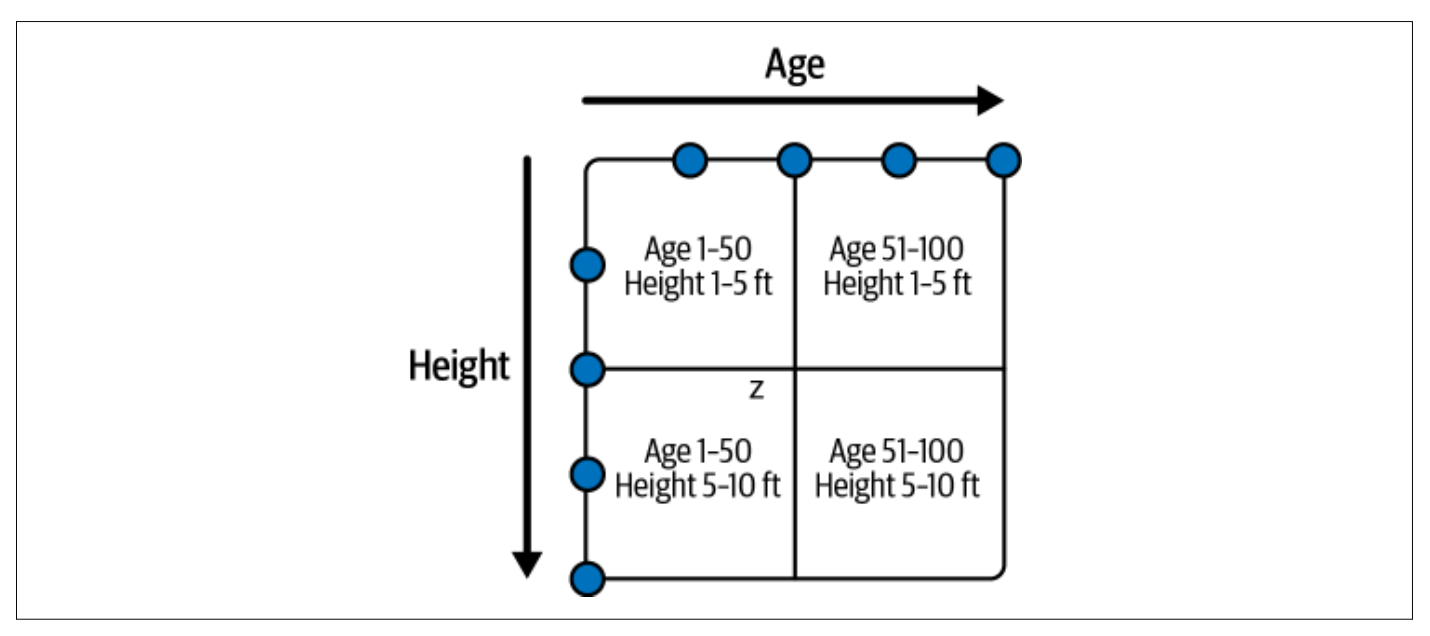
- A: File with records containing Age 1–50 and Height 1–5
- B: File with records containing Age 51–100 and Height 1–5
- C: File with records containing Age 1–50 and Height 5–10
- D: File with records containing Age 51–100 and Height 5–10
압축 방법은 다음과 같습니다.
CALL catalog.system.rewrite_data_files(
table => 'people',
strategy => 'sort',
sort_order => 'zorder(age,height)'
)Sort, Z-order와 같은 방식은 Read에 있어 좋은 성능을 보장하지만, 결론적으로 단점이 있다면 압축 전에는 작은 파일로 산개되어 있는 파일들을 거의 모두 읽어 봐야 한다는 점입니다.
또한, 위의 예시에서 나이가 30대인 사람만 관심이 있다면, 어쩔 수 없이 파일 앞뒤에 붙어 있는 20대, 40대의 다른 Row들도 Scan을 해야 된다는 점이 문제에요.
마치며
다음 시간에는 Partitioning, Merge-On-Read / Copy-On-Write, Metric Collection, Bloom Filter 등의 Table Optimization 기법을 알아 보도록 하겠습니다.