Intro
안녕하세요, 박민재입니다. 저번 시간에는 Table Optimization을 위한 압축 기법에 대해 배웠습니다. 이번 시간에는 압축을 제외한 Table Optimization 기법을 알아 보도록 하겠습니다.
Partitioning
역시, 기존의 방법을 꺼낼 때가 왔습니다. 바로 Partitioning입니다. 동일한 Column의 동일한 Value를 가진 친구들은 같은 File로 묶어 주는 방식이죠. 어? 왜 Directory가 아니라 File 이냐고요?
참고로, File이 저장 될 때 (Snapshot이 생성 될 때), Metadata Table인 files Table에서 각 file에 대한 partition 정보가 함께 삽입 됩니다. ref) https://iceberg.apache.org/docs/1.6.0/spark-queries/#querying-with-sql
추후 Query 실행 시, Physical Plan 측에서 이를 참고 합니다.
Hidden Partitioning
Iceberg는 Hidden Partitioning을 지원 합니다. 여기서 말하는 Hidden은 End User가 데이터를 삽입 함에 있어, Partitioning을 고려 하지 않고 데이터를 삽입 하여도 알아서 Query Planning에서 Partitioning을 수행 함을 의미합니다.
아래와 같이 timestamp를 가지고 있는 column에 대해서 PARTITIONED BY months(time)을 추가하여 CREATE TABLE을 수행 하면,
파일이 삽입 될 때, timestamp 내에서 가지고 있는 월별로 데이터를 삽입 합니다.
month 제외 하고도, 다양한 transforms function을 제공합니다.
- year: 연 단위 조회시 이점
- month: 월 단위 이상 조회에서 이점
- day: 일 단위 이상 조회에서 이점
- hour: 시간 단위 이상 조회에서 이점
- truncate(column, num): column내 문자열 중, num 번째 문자 까지 절삭하여 파티셔닝
- ex) a라는 column에서 'abc'라는 값을 가지고 있고, num=2 라면 a='ab'로 파티셔닝
- bucket(num, column): num 갯수만큼 hash 값을 바탕으로 파티셔닝 하여 저장. 단일 값을 추출 할 때 유용.
아래는 예시입니다.
CREATE TABLE catalog.MyTable (...) PARTITIONED BY months(time) USING iceberg;만약 상기한 테이블에 SELECT QUERY로 time column에 대해 조건을 넣어 쿼리를 수행 한다면, 조회 하려는 Partition을 명시 하지 않아도 Query Plan 수립 과정에서 최적화하여 조회 합니다.
SELECT * FROM MYTABLE WHERE time BETWEEN '2022-07-01 00:00:00' AND '2022-07-31 00:00:00';Partition Evolution
기존에는 Directory 별로 저장 되기 때문에, 만약 month로 파티셔닝 하다가, day로도 파티셔닝을 하려는 요구 사항이 있을 때, directory의 물리적인 한계 때문에 실시간으로 Partition을 Evolution 하는 것이 어려웠습니다.
하지만, Iceberg 에서는 이를 가능하게 할 수 있습니다. 기존 아래와 같은 테이블이 있다고 가정 하겠습니다.
CREATE TABLE catalog.members (...) PARTITIONED BY years(registration_ts) USING iceberg;만약 데이터의 절대적인 크기가 커져, 이를 월 단위로 파티셔닝 하여야 할 때, 다음 명령어로 Partition Evolution을 할 수 있습니다. 단, 해당 명령 수행 직후, 파일을 다시 Write하는 것은 아니고, rewriteDataFiles 수행 시에 다시 Write 하는 방식입니다.
ALTER TABLE catalog.members ADD PARTITION FIELD months(registration_ts)당연히 Partition 삭제 또한 가능합니다.
ALTER TABLE catalog.members DROP PARTITION FIELD bucket(24, id);Copy-on-Write VS Merge-on-Read
우리는 File Update, Delete가 발생 했을 때 기존에는 Copy-on-Write, 즉, File을 지우고 다시 쓰는 방법으로 대응 하였습니다. 하지만, Iceberg에서는 Merge-on-Read 라는 새로운 기법을 제공 합니다.
요약하면 다음과 같습니다.
| Update Style | Summary | Read Speed | Write Speed | Best Practice |
|---|---|---|---|---|
| Copy-on-Write | 파일 내의 특정 Row에 Update가 필요하게 될 경우, 해당 파일을 다시 Write 합니다. | 가장 빠름 | 가장 느림 | |
| Merge-on-Read (position delete) | 파일 내의 특정 Row에 Update가 필요하게 될 경우, 특정 Row의 Position을 기억하고, 해당 Row가 어떻게 Update 되어야 하는지 내역을 저장 합니다. 읽을 때는, 해당 Postition의 Row인 경우, Data를 수정 하여 Read 합니다. | 빠름 | 빠름 | Read Cost를 감소 시키기 위해서 File Compaction을 수행 |
| Merge-on-Read (equality delete) | 파일 내의 특정 Row에 Update가 필요하게 될 경우, 해당 파일이 어떻게 Update 되어야 하는지 내역을 저장 하고, 읽을 때 전체 Update를 수행 합니다. | 느림 | 매우 빠름 | Read Cost를 감소 시키기 위해서 File Compaction을 자주 수행 |
Copy on Write
기존의 방식과 동일하게, File Update가 필요 할 경우, Rewrite를 수행합니다.

Merge On Read
Copy-on-Write의 대체 방식입니다. Update/Delete 시에 File을 Rewrite 하는 것이 아닌, Datafile/Delete File을 생성 하고, 읽을 때 이를 대응 합니다.
File Update/Delete의 성능을 올리기 위해 사용합니다. 단, 조회 시 이를 Merge 하는 과정이 있어, 조회가 많은 Table에 사용하기 적합하지 않습니다.
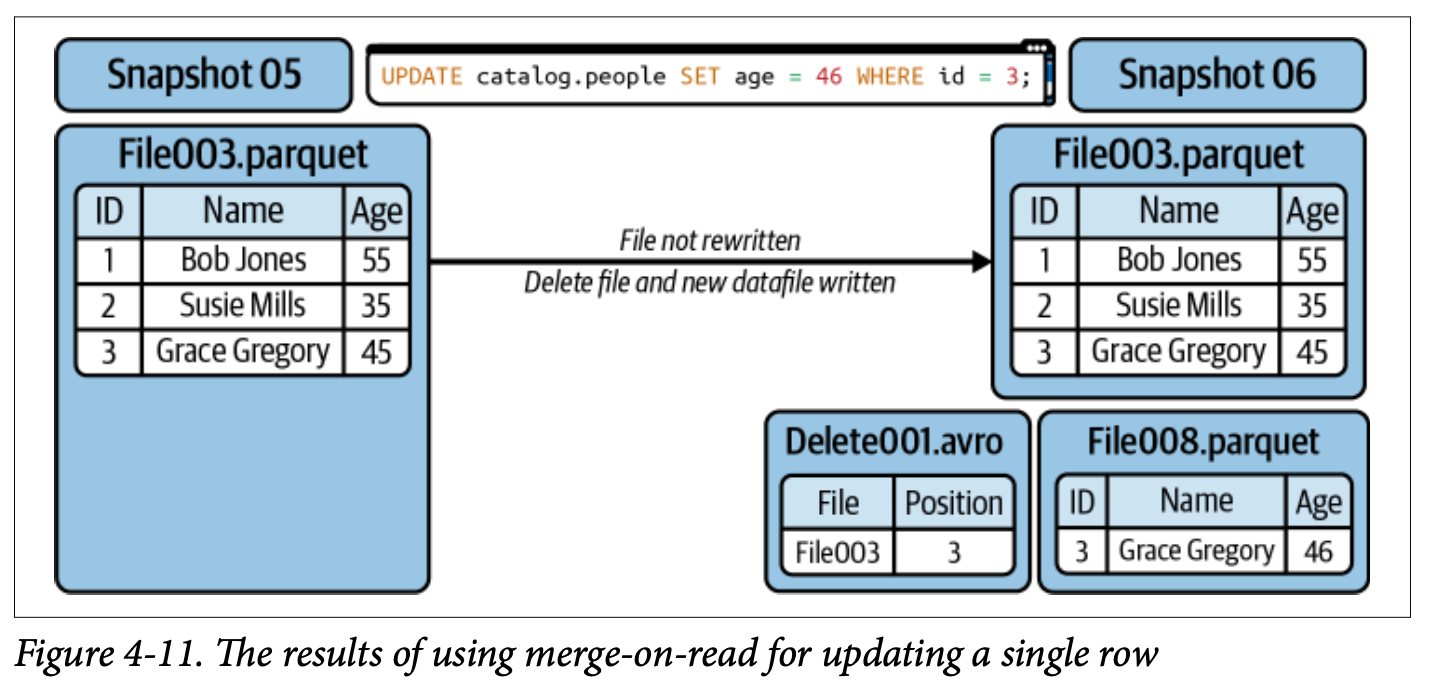
아래의 예시는 Position delete의 예시입니다.
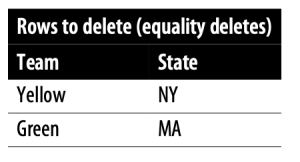
아래는 Equality delete의 delete file의 예시입니다.
Read 성능을 높이기 위해서는 압축을 자주 수행 해 줘야 하는데요, 전체 파일에 대해서 재압축 하는 것은 효율적이지 않습니다. timestamp에 대한 Partition을 이용하여, 다시는 Update / Delete가 없을 것으로 예상 되는 최신의 Record에 압축을 수행 하는 것을 권장하고 있습니다. 또한, partial progress로, 현재 파일을 읽고 있는 유저에게도 업데이트 된 파일이 최대한 보이게 하는 것도 좋습니다.
Configuring COW and MOR
DELETE, UPDATE, MERGE 각각의 Update 시에 다른 Operation이 수행 되도록 설정 해 줄 수 있습니다.
- write.delete.mode
- write.update.mode
- write.merge.mode
CREATE TABLE catalog.people (
id int,
first_name string,
last_name string
) TBLPROPERTIES (
'write.delete.mode'='copy-on-write',
'write.update.mode'='merge-on-read',
'write.merge.mode'='merge-on-read'
) USING iceberg;
ALTER TABLE catalog.people SET TBLPROPERTIES (
'write.delete.mode'='merge-on-read',
'write.update.mode'='copy-on-write',
'write.merge.mode'='copy-on-write'
);하지만, 해당 옵션들은 Spark 외의 다른 Engine을 사용 할 때 무시 될 수 있으니, 각 Engine을 사용 할 때 마다 이를 지원 하는지 확인이 필요 합니다.
Other Considerations
Metric Collection
여러 개의 Data File을 가르키고 있는 Manifest 파일은, 쿼리의 최적화를 위해서 각 field의 metric을 Tracking 하고 있습니다.
- Value의 갯수, null 값의 갯수, distinct 한 값의 갯수
- Upper Bound + Lower Bound
만약, 테이블의 column이 100개를 넘어 간다면, 일부 metric을 수집하지 않는 것을 고려 해 볼 수 있습니다.
ALTER TABLE catalog.db.students SET TBLPROPERTIES (
'write.metadata.metrics.default'='none'
'write.metadata.metrics.column.col1'='none',
'write.metadata.metrics.column.col2'='full',
'write.metadata.metrics.column.col3'='counts',
'write.metadata.metrics.column.col4'='truncate(16)',
);- write.metadata.metrics.default: 전체 Column의 Metric 수집 기본값을 설정 해 줄 수 있으며, default value는 truncate(16) 입니다.
- write.metadata.metrics.column.col1: 특정 Column의 Metric 수집 값을 설정 해 줄 수 있습니다.
다음은 Option입니다.
- none: 아무 metric도 수집하지 않습니다.
- counts: values, distinct values, null values 의 count 만을 수집 합니다.
- truncate(num): counts + upper/lower bound를 수집하는데, 문자열인 경우 num 번째 문자열 까지 절삭한 데이터로 메타 데이터를 수집 합니다.
- full: count + upper/lower bound를 수집합니다. 문자열인 경우, 전체 문자열에 대해 메타 데이터를 수집 합니다.
Rewriting Manifests
Streaming Table 같이, 많은 Commit이 발생하면 수많은 Metadata가 쌓이게 되어 문제가 발생 할 수 있습니다. Metadata가 산개하여 있다면, 그 만큼 많은 Metadata를 읽어야 한다는 것이 문제에요.
우리는 이를 rewrite_manifest를 통해 해결 할 수 있습니다.
CALL catalog.system.rewrite_manifests('MyTable')
CALL catalog.system.rewrite_manifests('MyTable', false) -- Memory에 이슈가 있을 시, Spark에서 Cache하는 것을 중단Optimizing Storage
우리는 Table에 대해 update를 수행 하고, 압축을 수행하지만, 과거의 Snapshot이 과거의 데이터를 바라 본다면, 이는 계속 실제로 데이터가 Storage에 남게 되는 문제가 발생 합니다.
이를 해결하기 위해 우리는 snapshot을 expire 하고, 더 이상 snapshot이 가르키지 않는 파일들을 제거 해 줄 수 있습니다.
아래는 snapshot expire 예시입니다.
-- 2023-02-01 전 Snapshot 모두 삭제, 단 100개만 남기고
CALL catalog.system.expire_snapshots('MyTable', TIMESTAMP '2023-02-01 00:00:00.000', 100)
-- snapshot_ids=53 Snapshot만을 삭제
CALL catalog.system.expire_snapshots(table => 'MyTable', snapshot_ids => ARRAY(53))- table: Table 명
- older_then: 해당 timestamp 보다 오래된 snapshot 삭제
- retain_last: 삭제 이후 남길 최소한의 snapshot 갯수
- snapshot_ids: 삭제 할 snapshot id
- max_concurrent_deletes: 삭제 할 때 사용한 thread 갯수
- stream_results: File 삭제시, 삭제할 파일을 Spark Driver에 RDD partition으로 쪼개서 전송. 큰 데이터를 삭제할 때 유용
아래는 remove_orphan_file 예시입니다.
-- MyTable 내, Metadata가 가르키고 있지 않은 file 삭제
CALL catalog.system.remove_orphan_files(table => 'MyTable')- table: Table 명
- older_then: 해당 timestamp 보다 오래된 orphan file 삭제
- location: 삭제할 orphan file의 위치. 기본 값은 table의 location입니다.
- dry_run: 삭제하는 대신, 삭제할 파일의 list 출력
- max_concurrent_deletes: 삭제 할 때 사용한 thread 갯수
Write Distribution Mode
요약 하자면 비슷한 파일들은 비슷한 Task에 들어가서, 동일 File로 Write 되어야 합니다. 이를 위해서 pre-sort를 진행 하는 여러 가지 distribution mode를 지원 합니다.
아래는 테이블에 distribution mode를 지정 하는 예시입니다.
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.distribution-mode'='hash',
'write.delete.distribution-mode'='none',
'write.update.distribution-mode'='range',
'write.merge.distribution-mode'='hash'
);- none: 1.2.0 버전 이전의 기본 값으로, File Write를 수행 할 때, pre-sort를 진행 하지 않고, 빠르게 값을 Write 합니다.
- hash: 1.2.0 버전 이후의 기본 값으로, File Write를 수행 할 때, Partition Key에 맞춰서 Hash 값 바탕으로 pre-sort 하여 Write 합니다.
- range: File Write를 수행 할 때, Partition Key에 맞춰서 range 바탕으로 pre-sort 하여 Write 합니다.
Datafile Bloom Filters
bloom filter는 Hash 함수를 이용하여, 데이터가 있을 수도 있는 파일에 마킹을 하는 방식입니다.
다음과 같이 hash function으로 생성 된 Bloom Filter가 있다고 가정 하겠습니다 → [0,1,1,0,0,1,1,1,1,0]
0번째는 0값을 가지고 있으므로, 해당 File을 조회 할 필요가 없고, 1번째는 1값을 가지고 있으므로, 해당 파일을 조회하면 데이터가 있을 가능성이 있습니다.
Table에 설정은 다음과 같이 가능합니다.
ALTER TABLE catalog.MyTable SET TBLPROPERTIES (
'write.parquet.bloom-filter-enabled.column.col1'= true,
'write.parquet.bloom-filter-max-bytes'= 1048576
);Bloom Filter 크기를 키우면, 더 세밀한 bloom filter를 만들 수 있지만, 연산 시 Memory와 저장 시 Disk에 영향을 줄 수 있으니, Trade-off를 고려하여야 합니다.