안녕하세요, 박민재입니다. 오늘은 Spark Application내의 각 Executor 내의 Task에 제한적으로 변수를 공유하는 두 가지 방법에 대해서 알아 보도록 하겠습니다.
시작하기에 앞서
단편적으로 생각 해 보면, Spark Application에서 연산 과정의 변수를 공유 한다는 것은 어려운 일인가? 라는 질문을 던져 볼 수 있습니다. 우리는 Task 내에서 변수를 공유 하기 위해서, 다음과 같은 코드를 작성 할 수 있겠죠.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.Row
val df = (...) // DataFrame 선언부
var i = 0
// repartition으로 Partitioning을 강제 함. 12개의 task가 생성 됨.
// Parameter로 들어간 lambda 함수를 실행.
df.repartition(12).foreachPartition((rows: Iterator[Row]) => {
i += 1
println(i) // 스포: 1 출력됨
})
println(i) // 스포: 0 출력됨이는 충분히 납득이 가능한 코드로 보입니다. DataFrame의 repartition Method를 생성 하여 12개의 Partition이 생성 되도록 repartition을 수행하고, 각 파티션 별로 i에 1씩 더해주는 코드로, 우리는 12라는 값이 출력 될 것이라고 예상할 수 있겠죠. 하지만, 우리는 Spark Application을 작성 할 때, 유의 할 점이 있습니다.
Spark Application Architecture
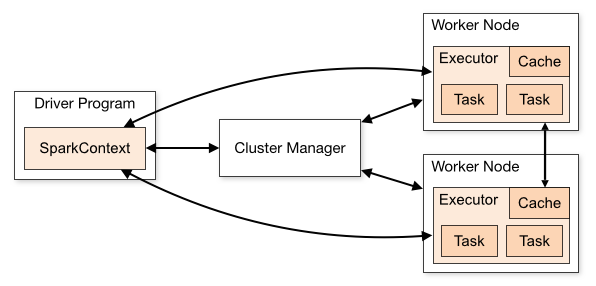
Spark Application Architecture를 다시 살펴 봅니다. Spark의 각 Partition 처리는 Task 단위로 수행되며, 이 Task는 Thread를 통해 1개의 CPU Core에서 수행 됩니다. (1개의 partition을 처리하는 1개의 task는 1개의 Core에서 실행) Spark Application이 실행 될 때, 아래와 같은 과정이 수행 됩니다.
- SparkContext가 생성 되면, 각 Worker Node 별로 Executor를 위한 JVM Context 생성
- Driver에서 Spark RDD 연산, 혹은 Spark SQL 연산에 대한 Action 코드 호출 시 Logical Plan을 SparkContext로 전달,
- SparkContext단에서 실제 Physical Plan을 수립한 후, Executor Process에 연산 해야 할 항목 전달
- 각 Task는 Executor Process 내에서 Thread를 생성하여 수행함.
추가적으로 Spark Application에서 사용되는 DataFrame API은 Logical Plan을 Driver Process에 제공하는 API에 불과 하다는 점도 유의 해야 합니다. 상기한 코드에서 사용된 Dataframe.foreachPartition은 각 Partition을 이용하여 Task를 처리 할 때 사용할 함수를 보내는 역할만을 수행 합니다.
결론적으로는 위에 있는 코드는 어떤 값을 반환 하냐고요? 각자 다른 Process에서 수행 되는 변수는 특별한 로직이 없다면 공유 될 수 없습니다. 그렇기 때문에 foreachPartition 밖에서 호출 된 println(i)는 0을 반환 하게 됩니다. foreachPartition으로 들어간 익명 함수 안에서는 1을 출력하고요.
그럼 어떻게 값을 공유할 수가 있나요?
사실 Spark에서 여러 Executor가 하나의 Driver와 값을 공유하는 패턴을 지양하긴 합니다. 이는 대부분의 상황에서 비효율적인 작업일 가능성이 높기 때문이에요. 하지만, 제한적인 기능만을 수행 하는 두 가지 API를 제공 합니다. 이는 Driver에서 Executor로의 일관 된 단방향 통신을 지원 하는 Broadcast와 Executor에서 Driver로의 단방향 통신을 지원 하는 Accumulator 입니다.
Supporting general, read-write shared variables across tasks would be inefficient. However, Spark does provide two limited types of shared variables for two common usage patterns: broadcast variables and accumulators.
Broadcast
Broadcast는 Driver에서 Executor로의 일관 된 단방향 통신을 지원 합니다. 이는 Spark의 low-level API를 개발 할 때도 사용하지만, SparkSQL 단에서 Join을 수행 할 때, 작은 Table을 Join하게 될 때 성능을 높이기 위해서, 실제 Logical Plan 단에서 크기가 작은 Table을 Broadcast 하여 각 Task에서 Join하는 경우도 있습니다.(ref)
사용 방법은 SparkContext의 broadcast(value) Method를 호출 하여, Broadcast 객체를 얻어 내고, 이를 실제 연산하는 함수에서 참조하여 사용하는 방식입니다.
Broadcast.unpersist() 를 이용하여 Executor에 Broadcast 된 데이터만을 파기 하거나 (이를 이용한 경우, Broadcast 변수가 다시 사용되게 되면, 다시 Broadcast를 수행 하여, 데이터를 받을 수 있습니다.) Broadcast.destroy() 는 Broadcast로 전파된 모든 데이터와 메타데이터를 파기하여, 다시 사용할 수 없게 합니다. destroy(true) 로 동작 시키게 되면, Broadcast 된 데이터가 실제로 파기 될 때 까지 데이터 접근을 blocking 합니다.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.Row
val df = (...)
// SparkSession.sparkContext.broadcast(value)로 Broadcast 객체 생성
// type: org.apache.spark.broadcast.Broadcast[Array[Int]]
val broadcast = spark.sparkContext.broadcast(Array(1, 2, 3))
df.repartition(12).foreachPartition((rows: Iterator[Row]) => {
println(broadcast.value.mkString("Array(", ", ", ")")) // Array(1, 2, 3)
})
broadcast.unpersist()
df.repartition(12).foreachPartition((rows: Iterator[Row]) => {
println(broadcast.value.mkString("Array(", ", ", ")")) // Array(1, 2, 3)
})
broadcast.destory()
df.repartition(12).foreachPartition((rows: Iterator[Row]) => {
println(broadcast.value.mkString("Array(", ", ", ")")) // ERROR OCCUR!
})Accumulator
Accumulator는 Executor에서 Driver로의 일관 된 단방향 통신을 지원 합니다. 단, 여러 개의 Executor에서 연산 된 값들을 하나의 Driver로 모아주는 역할을 수행 하다보니, 결합법칙과 교환법칙이 가능 한 연산을 지원 합니다. 대표적으로 덧셈 연산이 있죠.
저희 학생 때 한 내용이라 기억이 잘 안나실까봐...
세 정수 a, b, c에 대하여
- 교환법칙: a + b = b + a, a × b = b × a
- 결합법칙: (a + b) + c = a + (b + c), (a × b) × c = a × (b × c)
기본적으로 SparkContext에서 longAccumulator, doubleAccumulator를 사용 하실 수 있습니다.
여기서 동작을 유심히 보면 좋은데요, Driver에서 accumulator.value 를 참조 하였을 때와, Executor 내에서 수행되는 함수에서 accumulator.value 를 참조 하였을 때, 각 Executor에서 연산 된 값을 지속적으로 Drvier의 Accumulator에 더해 주는 것을 확인 할 수 있습니다.
import org.apache.spark.sql.functions._
val df = (...)
var long = spark.sparkContext.longAccumulator("My Accumulator")
// SparkSession.sparkContext.longAccumulator(name)으로 name이라는 이름을 가진 LongAccumulator 생성
df.repartition(12).foreachPartition(rows => {
long.add(1)
})
println(long.value) // 12를 출력합니다. 해당 println은 Driver 단에서 호출 됩니다. Partition 갯수 만큼 add가 된 모습.
df.repartition(12).foreachPartition(rows => {
long.add(1)
})
println(long.value) // 24를 출력합니다. 이는 계속 누적됩니다.
df.repartition(12).foreachPartition(rows => {
long.add(1)
println(long.value) // 각 Executor에서는 1을 출력 합니다.
})
println(long.value) // 36을 출력 합니다.직접 AccumulatorV2 라는 친구를 상속 받아, 결합법칙과 교환법칙이 가능한 연산에 대해서 Accumulator를 구현 할 수 있습니다.
class VectorAccumulatorV2 extends AccumulatorV2[MyVector, MyVector] {
private val myVector: MyVector = MyVector.createZeroVector
def reset(): Unit = {
myVector.reset()
}
def add(v: MyVector): Unit = {
myVector.add(v)
}
...
}
// Then, create an Accumulator of this type:
val myVectorAcc = new VectorAccumulatorV2
// Then, register it into spark context:
sc.register(myVectorAcc, "MyVectorAcc1")