안녕하세요? 오늘은 Spark Structured Streaming에 대해서 알아 보도록 하겠습니다.
Spark Structured Streaming이란?
Spark Structured Streaming은, Spark SQL (Dataset/DataFrame) 엔진 기반의, 확장 가능하고, 내결함성이 있는 Stream Processing Engine 입니다. 이는 Batch 작업에서 구조화된 데이터를 처리 하는 것 처럼, Streaming 작업에서도 구조화된 데이터 형태로 데이터를 받아 처리를 가능 하게 해 줍니다. (ex: DataFrame)
또한, Streaming Aggregation (스트리밍 집계), event-time windows, stream과 batch join 등이 최적화된 SQL Engine에서 작동 시킬 수 있으며, Write-Ahead 체크 포인트를 통해 end-to-end exactly-once fault-tolerance를 보장 할 수 있습니다.
기존 Spark Streaming과 같이, Micro-batch processing을 수행 하며, 또 다른 기능으로는, Micro-batch를 사용하지 않는, Continuous Processing 모드를 이용 하여, end-to-end latency를 1 millisecond 까지 줄일 수 있습니다. 단, 이는 실험적 기능으로 존재 하기 때문에, 큰 데이터를 처리하는 데에는 성능이 좀 보장 되기가 힘들 수도 있어 보이네요. (자원 사용량의 증가.)
Scala 예제로 들어가 보죠!
SparkSession을 생성 해 줍니다.spark.implicits._를 import 해 줍니다.spark.readStream을 통해서, Streaming Data Source를 읽습니다. socket 형식으로 읽으며, Host 이름과 포트번호를 지정 합니다. 이는 Kafka, File 등, 다양한 Data Source를 지원 합니다. return 값은 DataFrame 입니다.words를 통해,DataFrame을Dataset[String]으로 변환 시키고,wordCounts를 통해groupBy를 수행 합니다. 해당 부분이 Aggregation(집계) 을 수행 하는 역할 입니다. 추후에 사용 용도에 맞추어 해당 부분을 수정 가능 합니다.writeStream을 통해 출력을 할 수 있습니다. 현재console모드를 이용 하여, 결과물을 출력 합니다. 혹은 External Sink를 이용하여, HDFS, S3, 로컬 파일 시스템 등 다양한 곳에 데이터를 저장 할 수 있습니다.- Streaming Job이 종료 되지 않게 하기 위해서,
query.awaitTermination()을 통해, 종료 트리거가 될 때 까지 대기 합니다.
import org.apache.spark.sql.functions._
import org.apache.spark.sql.SparkSession
val spark = SparkSession
.builder
.appName("StructuredNetworkWordCount")
.getOrCreate()
import spark.implicits._
val lines = spark.readStream
.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
// Split the lines into words
val words = lines.as[String].flatMap(_.split(" "))
// Generate running word count
val wordCounts = words.groupBy("value").count()
val query = wordCounts.writeStream
.outputMode("complete")
.format("console")
.start()
query.awaitTermination()일단 터미널에 nc -lk 9999 를 작성하여, Socket 연결을 시도 해 보죠! (NetCat 이라는 친구 입니다.) 그 다음, Spark Application을 실행 해 보면 다음과 같습니다.
$ nc -lk 9999
apache spark
apache hadoop-------------------------------------------
Batch: 0
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 1|
| spark| 1|
+------+-----+
-------------------------------------------
Batch: 1
-------------------------------------------
+------+-----+
| value|count|
+------+-----+
|apache| 2|
| spark| 1|
|hadoop| 1|
+------+-----+이런 식으로, word를 split하여 group by 한 결과가 실시간으로 반영 되는 것을 볼 수가 있습니다.
원래라면, Trigger라는 요소를 사용하여, 들어 온 데이터에 대해 몇 초마다 쿼리를 수행 하고 저장 할 지를 정할 수도 있습니다. 다음과 같이, output option에 삽입 해 주면 됩니다. 아래 예제는 10초 마다 Trigger를 보내는 예제입니다.
...
import org.apache.spark.sql.streaming.Trigger
...
val query = wordCounts.writeStream
.trigger(Trigger.ProcessingTime("10 seconds"))
.outputMode("complete")
.format("console")
.start()
...기본 컨셉
Spark Structured Streaming의 주 컨셉은 Input Data Stream이 테이블의 행으로 계속 추가 되는 것 입니다.
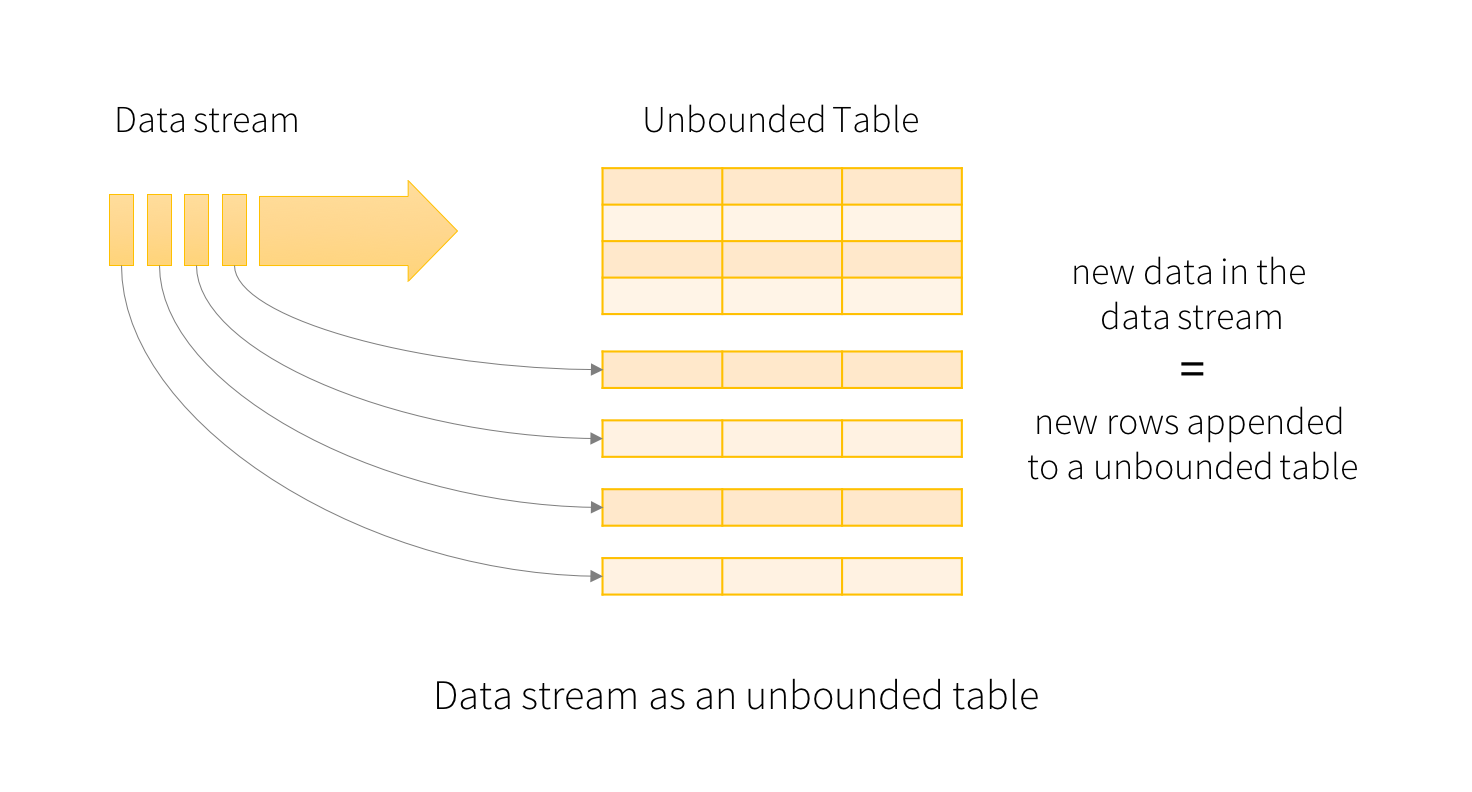
그렇게 계속 들어오게 된 Input들은, 매 trigger 시간마다, 작성한 쿼리를 바탕으로 Result Table을 생성 합니다. 위의 예제로 따지면, 작성한 쿼리는 words 에 해당 되겠네요! 현재 우리는 query 결과를 디버깅을 위해서 format으로 지정 했지만, file로 지정이 된다면, result table이 업데이트 될 때 마다, external sink에 저장 되는 형식으로 진행이 되겠군요.
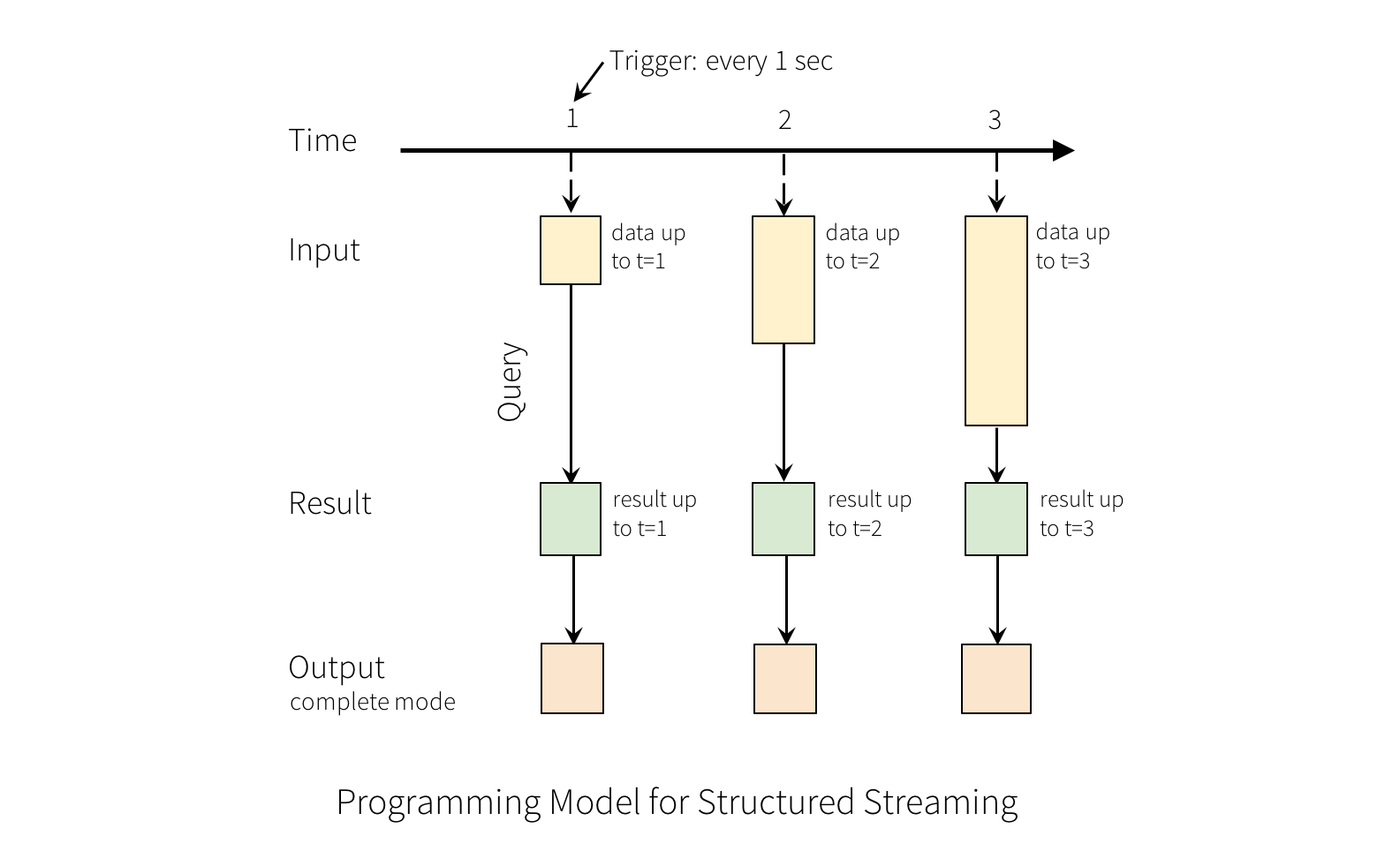
outputMode 의 설정을 통해서, external sink에 어떻게 저장 할 것인지 정해 줄 수 있습니다.
- Append Mode: last trigger 이후, 새롭게 추가된 row만 output sink에 기록 됩니다. 단, 추가된 row가 바뀔 일이 없어야 사용 할 수 있습니다. Streaming으로 들어온 데이터를 계속 적재 해 주는 식이라면 편하게 사용 할 수 있겠군요! 아마, select, where, map, flatMap, filter, join 같은, 기존에 row에 영향을 주지 않는 쿼리들을 수행 할 수 있을 것으로 보이네요.
- Complete Mode: Trigger된 모든 result table을 모두 저장하는 모드입니다. 주기적으로 복잡한 aggregation이 필요 한 경우에 사용 하면 될 것 같습니다.
- Update Mode: last trigger 이후, 업데이트 된 Result Table의 행만 추가 됩니다.
다음 시간에는, 로컬(Docker)에서 Kafka를 구동 하여, 실제 데이터를 받아보는 실습을 진행 하고, Trigger, Checkpoint, 그리고 StreamingQueryListener에 대해서 알아 보도록 하겠습니다.