Intro
안녕하세요, 박민재입니다. 오늘은 Spark Memory에 관해 Deep Dive를 해 보도록 하겠습니다. Spark는 In-Memory를 이용하여, 빠른 연산을 할 수 있도록 보장합니다. 하지만, In-Memory 연산은 빠른 대신, 비싼 관계로 적은 리소스 만을 활용할 수 있습니다. 그렇기 때문에 우리는 효율적으로 Memory를 관리 하여, Spark Application이 빠르고, 안정적으로 Task를 수행 할 수 있도록 하여야 합니다.
오늘은 이를 위해, 다음과 같은 목차로 Spark의 Memory를 효율적으로 사용 할 수 있는 방법에 대해 알아 보려고 합니다.
- Executor Memory Structure
- User Memory는 왜 Usable Memory의 40% 가량을 사용 하는가?
- Execution Memory와 Storage Memory는 얼마가 충분 한가요?
- Caching 해야할 데이터가 너무 크다면?
Executor Memory Structure
Executor Memory Structure는 작년 Post에 설명 드렸던 것과 동일 합니다.
Spark에서 Executor는 독립된 JVM 프로세스로 실행 되며, Executor는 클러스터 내부의, 여러 개의 인스턴스에서 실행 될 수 있습니다. 또한, 각 인스턴스는 다수의 CPU 코어로 Task를 병렬로 실행 하여, 다수의 Partition을 처리 할 수 있습니다. 또한, 각 인스턴스의 메모리는 다음과 같이 구성 되어 있습니다,
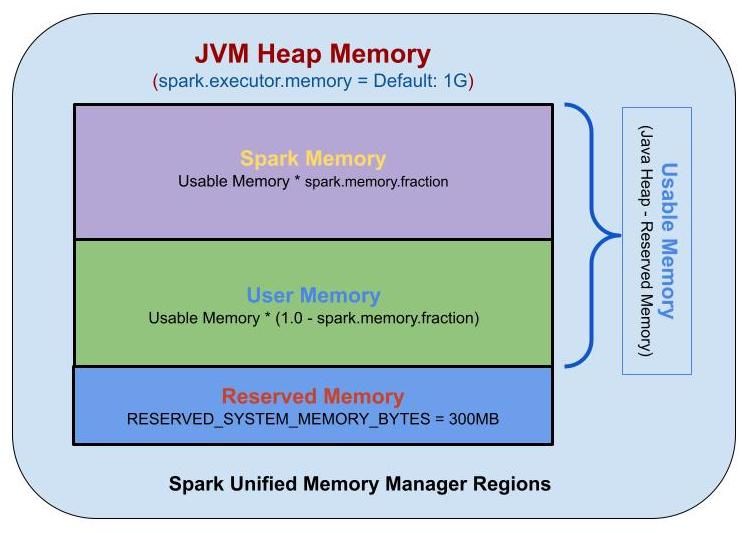
Spark Executor Memory의 구조는 크게 세 가지 영역으로 나눌 수 있습니다. 이 세 가지 영역은 다음과 같습니다.
- Reserved Memory: Executor의 기타 기능 및 운영체제에서 사용 하는 메모리 등을 위해 예약된 메모리 영역입니다. 예로 JVM 내에서 사용 하는 메모리, Java의 Garbage Collection에서 발생 하는 메모리 등이 저장 됩니다. 300MB가 고정 되어 있습니다.
전체 Executor Memory - Reserved Memory는 Usable Memory가 됩니다. - Spark Memory: Spark에서 사용하는 메모리 영역으로, RDD Cache, Broadcast 변수, 실행 계획 등이 이 영역에 저장 됩니다.
Usable Memory * spark.memory.fraction이 Spark Memory가 됩니다.spark.memory.fraction의 기본 값은 0.6입니다.- Storage Memory: Cache를 수행 한 데이터, Broadcast 변수가 저장 됩니다. 캐싱할 공간이 부족 하면, LRU(Least Recently Used) 방식으로 제거합니다.
Spark Memory * spark.memory.storageFraction이 Storage Memory가 됩니다.spark.memory.storageFraction의 기본 값은 0.5입니다. - Execution Memory: Spark가 task를 실행 하는 동안 생성되는 object들인 Map 수행 시 Shuffle Intermediate Buffer, Hash aggregation step에서의 Hash Table 등이 저장 됩니다. 메모리가 충분 하지 않으면, 디스크로 Spill을 하기 때문에 디스크 I/O를 줄이기 위해서 고려 하여야 합니다
Spark Memory * (1 - spark.memory.storageFraction)이 Execution Memory가 됩니다. - Storage Memory와 Execution Memory는 필요 시 서로의 메모리를 점유 할 수 있습니다.
- 여기서 Spark Memory가 꽉 차있는 상황이라면, Storage Memory는 Execution Memory를 축출할 수 없지만, Execution Memory는 Storage Memory의 임계값(
spark.memory.storageFraction) 까지 축출 할 수 있습니다.
- 여기서 Spark Memory가 꽉 차있는 상황이라면, Storage Memory는 Execution Memory를 축출할 수 없지만, Execution Memory는 Storage Memory의 임계값(
- Storage Memory: Cache를 수행 한 데이터, Broadcast 변수가 저장 됩니다. 캐싱할 공간이 부족 하면, LRU(Least Recently Used) 방식으로 제거합니다.
- User Memory: 사용자 코드에서 직접 할당 되는 메모리 영역입니다. Spark 내부 메타데이터, 사용자 정의 데이터 구조, UDF, RDD 종속성 정보 등, 요약하면 사용자가 정의한 데이터구조, UDF가 저장되는 공간입니다.
Usable Memory * (1 - spark.memory.fraction)이 User Memory가 됩니다.
User Memory는 왜 Usable Memory의 40% 가량을 사용 하는가?
생각 해보면, User Memory는 사용자 코드에서 직접 할당되는 메모리 영역으로, SparkSQL API를 주로 사용 한다면 굳이 40%나 할당 할 필요는 없어 보이는데요, 왜 기본 옵션으로 40% 가량이 User Memory로 사용 되는 것 일까요? 그 이유는 JVM의 Garbage Collection Option과 관련이 있습니다.
OpenJDK를 포함한 대부분의 JVM 기본 Old Generation과 Young Generation의 비율은 2:1로 설정이 되어 있는데요, Spark Memory는 기본적으로 Old Generation 영역에 있는 것이 GC의 효율상 좋기 때문입니다. 왜냐하면 연산에 필요한 Spark Memory에 해당 하는 영역들은 재사용 될 일이 훨씬 많기 때문이에요, 그렇기 때문에 성능 최적화를 위해서 Old Generation 영역 > Spark Memory 영역을 유지하여 주고, Spark Memory는 Old Generation 영역에 유지 시켜 주는 것이 좋죠.
그러면, JVM NewRatio Parameter를 조정 해서 Old Generation의 비율을 무조건 늘리는게 좋을까요? 아닙니다. 새로 들어온 Input Partition은 Young Generation 영역에 들어 오게 될꺼에요. 그렇기 때문에, Spark Documentation에서도, 가능한 해당 옵션은 건들지 말라고 합니다. 그럼에도 불구하고 spark.memory.fraction을 건드려야 할 일이 있다면, 아래의 원문 설명을 참조 하세요.
In the GC stats that are printed, if the OldGen is close to being full, reduce the amount of memory used for caching by lowering spark.memory.fraction; it is better to cache fewer objects than to slow down task execution. Alternatively, consider decreasing the size of the Young generation. This means lowering -Xmn if you’ve set it as above. If not, try changing the value of the JVM’s NewRatio parameter. Many JVMs default this to 2, meaning that the Old generation occupies 2/3 of the heap. It should be large enough such that this fraction exceeds spark.memory.fraction.
As an example, if your task is reading data from HDFS, the amount of memory used by the task can be estimated using the size of the data block read from HDFS. Note that the size of a decompressed block is often 2 or 3 times the size of the block. So if we wish to have 3 or 4 tasks’ worth of working space, and the HDFS block size is 128 MiB, we can estimate the size of Eden to be 4 * 3 * 128MiB.
Execution Memory와 Storage Memory는 얼마가 충분 한가요?
연산 과정에서 Input Partition (기본값 spark.sql.files.maxPartitionBytes 128mb)은 크기가 얼마인지, 한 개의 Instance에 몇 개의 Core가 할당 되는지, 중간중간 Shuffle Partition의 크기는 얼마인지 (만약, Partition의 크기가 크다면, Shuffle Partition 갯수를 늘리거나, Spark 3의 AQE 기능을 사용 하면 됩니다.) 어떻게 사용 될 지 알아야, 적정 메모리를 산정 할 수 있습니다. 먼저 Execution Memory 부터 보겠습니다.
Execution Memory는 실질적으로 Shuffle, Join, Aggregation 등의 연산을 수행 하는 메모리입니다. 그렇기에 Task를 수행 하는 Instance가 Partition * Core 수의 크기를 버틸 수 있는 수준이어야 합니다. 위에서 언급 되었던 것처럼, Input Partition의 크기는 압축 되어 있는 File을 In-memory에서 Deserialize 하게 되면, 크기가 2~3배 가량으로 더 증가 하기 때문에 이를 고려 하여야 하고요, 그렇기 때문에 Input Partition 크기 * 3 * Core 수 + Aggregation에 사용되는 Object 객체가 저장 될 수 있는 공간 정도가 초반에는 있어야 겠군요. 중간중간 Shuffle Partition의 크기는 Shuffle Partition의 갯수 (spark.sql.shuffle.partitions)로 조정 할 수 있는데요, Shuffle Partition은 Core 수의 배수로 (Core 병렬 연산을 최대화 하기 위함), Memory Spill이 발생 하지 않는 크기 수준으로, 대신 Overhead를 고려하여 너무 많지는 않게 설정하면 됩니다. 그런데 사실 AQE (Adaptive Query Execution) 사용 하면 그만이긴 한데요
Storage Memory 같은 경우에는, Cache 되는 데이터의 크기 / Instance 갯수 정도로 러프하게 계산 할 수 있을 것 같은데요, 하지만, Data Skew가 발생하는 경우, 특정 Instance에만 더 많은 데이터가 Cache 될 수 있으니 유의 하시는 것이 좋습니다. 또한, Broadcast Variable 같은 경우도 해당 영역에서 저장 되기 때문에 더 넉넉하게 지정 하는 것이 좋습니다.
Caching 해야할 데이터가 너무 크다면?
기존 많이 사용하는 df.cache()를 통해서 메모리를 Cache하면, 내부적으로 MEMORY_AND_DISK Storage Level로 저장 되는 데요, 이는 Deserialize 한 데이터를 그대로 저장 하고, 메모리 공간에 더 이상 저장할 수 없는 경우 디스크에 저장을 수행 합니다. 그렇기 때문에, 성능을 위해 In-Memory에 저장을 수행 하기 위해서는 MEMORY_AND_DISK_SER 혹은 MEMORY_ONLY_SER 옵션을 사용 하여, Serialize 된 데이터를 In-Memory에 Cache 하는 것도 방법 입니다. 이는 df.persist(StorageLevel.MEMORY_AND_DISK_SER) 과 같이, df.persist() 메서드를 이용 하여 수행 할 수 있습니다. 추가적으로 기존 Java Serialization 보다 더 성능이 좋은 Kryo Serialization을 이용 하여, Data를 더 Compact 하게 만들어 In-Memory에 저장 할 수 있습니다. 사용 하는 방법은 spark.serializer를 org.apache.spark.serializer.KryoSerializer 로 변경 하여 주면 됩니다.