오늘은 Spark의 성능 튜닝에 대해서 이야기 해 보겠습니다. Spark는 요약해서 말하면, **in-memory(RAM 위에서)**에서 작동 하는 분산 컴퓨팅을 쉽게 지원해 주는 프레임워크 입니다.
in-memory 연산은 빠르지만, 불안정 합니다. 메모리 관리, CPU Core 수의 관리를 통해 Out of memory가 발생 하지 않는 선에서, Job이 성공적으로 수행 될 수 있도록 하여야 하며, 적절한 캐싱 전략, 직렬화, Executor 파티션 갯수 선정을 통해, 많은 컴퓨팅 자원을 점유하지 않도록 해야 합니다.
이제 하나씩 알아 보도록 하겠습니다.
Executor
Spark에서 Executor는 Spark Cluster 내에서 데이터를 처리하는 단위이며, 독립된 JVM 프로세스로 실행 됩니다. Executor는 클러스터 내, 여러 개의 인스턴스에서 실행 될 수 있으며, 각 인스턴스는 다수의 CPU 코어로 작업을 병렬로 실행 될 수 있습니다. 또한, 각 인스턴스의 메모리는 다음과 같이 구성 되어 있습니다,
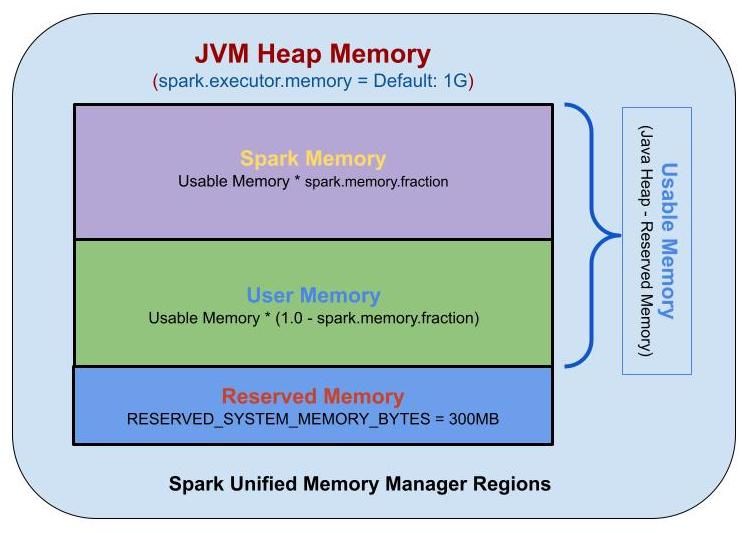
Spark Executor Memory는 세 가지 영역으로 나눌 수 있습니다. 이 세 가지 영역은 다음과 같습니다.
- Reserved Memory: Executor의 기타 기능 및 운영체제에서 사용 하는 메모리 등을 위해 예약된 메모리 영역입니다. 예로 JVM 내에서 사용 하는 메모리, Java의 Garbage Collection에서 발생 하는 메모리 등이 저장 됩니다. 300MB가 고정 되어 있으며,
spark.testing.reservedMemory로 설정을 변경 할 수 있으나, 오로지 테스트 용도 입니다.전체 Executor Memory - Reserved Memory는 Usable Memory가 됩니다. - Spark Memory: Spark에서 사용하는 메모리 영역으로, RDD Cache, Broadcast 변수, 실행 계획 등이 이 영역에 저장 됩니다.
Usable Memory * spark.memory.fraction이 Spark Memory가 됩니다.- Storage Memory: Cache 데이터, Broadcast 변수가 저장 됩니다. 캐싱할 공간이 부족 하면, LRU(Least Recently Used) 방식으로 제거합니다.
Spark Memory * spark.memory.storageFraction이 Storage Memory가 됩니다. - Execution Memory: Spark가 task를 실행 하는 동안 생성되는 object들인 Map 수행 시 Shuffle Intermediate Buffer, Hash aggregation step에서의 Hash Table 등이 저장 됩니다. 메모리가 충분 하지 않으면, 디스크로 Spill을 하기 때문에 디스크 I/O를 줄이기 위해서 고려 하여야 합니다
Spark Memory * (1 - spark.memory.storageFraction)이 Execution Memory가 됩니다. - 참고 사항: Storage Memory와 Execution Memory는 필요 시 서로의 메모리를 점유 할 수 있습니다. 여기서 Storage Memory는 Execution Memory로부터 쫓겨날 수 있지만, Execution Memory는 Storage Memory로부터 쫓겨 날 수 없습니다.
- Storage Memory: Cache 데이터, Broadcast 변수가 저장 됩니다. 캐싱할 공간이 부족 하면, LRU(Least Recently Used) 방식으로 제거합니다.
- User Memory: 사용자 코드에서 직접 할당 되는 메모리 영역입니다. Spark 내부 메타데이터, 사용자 정의 데이터 구조, UDF, RDD 종속성 정보 등, 요약하면 사용자가 정의한 데이터구조, UDF가 저장되는 공간입니다.
Usable Memory * (1 - spark.memory.fraction)이 User Memory가 됩니다.
Partition
그 다음으로는 Spark의 Partition에 대해서 알아 보도록 하겠습니다.
Spark에서 파티션은 데이터를 분할하는 단위로, Spark에서 처리 하는 최소 단위라고 볼 수 있습니다. RDD(Resilient Distributed Dataset) 를 구성하는 최소 단위 객체이며, 각 파티션은 클러스터의 노드에서 분산 되어 처리 됩니다.
각 Partition은 서로 다른 노드에서 분산 처리 되며, 1개의 CPU Core가, 1개의 Partion에 대해, 1개의 최소 연산인 Task를 수행 합니다.
똑같은 크기의 데이터 입력 이라면 설정된 Partition 수에 따가 각 Partiton의 크기가 결정되는 것이죠!
- Partiton 수가 적어요 -> Partition의 크기가 커져요!
- Partiton 수가 많아요 -> Partition의 크기가 작아져요!
파티션을 작게 만들면, 더 작은 파일 단위로 쪼개어, Task당 필요한 메모리를 줄이고, 병렬화의 정도를 늘릴 수 있기 때문에 좋지 않을까요? 이는 정답이 아닙니다. 너무 많은 파티션으로 쪼개게 되면, 파티션 간 통신 비용이 증가 하게 되고, 저장 시에는 Small File Problem이 발생 하여, Disk I/O 비용이 증가 하게 되는 단점이 있습니다.
그렇다면 크게 만드는 것이 답일까요? 그것 또한 아닙니다. 너무 작은 수의 파티션은 적은 Task 수로 이어져, 병렬 처리에 불리합니다. 또한, Executor 메모리 사용량 증가, Partition의 데이터 분포가 고르지 않음으로 발생 하는, Data Skew현상 또한 발생 할 수 있습니다.
Partition의 종류는 3개로 나눌 수 있습니다.
- Input Partition: 처음 파일을 읽을 때 생성하는 Partition으로, 관련 설정 값은
spark.sql.files.maxpartitionBytes입니다. - Output Partition: 파일을 저장할 때 생성하는 Partition으로, 이 수가 HDFS 상의 마지막 경로의 파일 수를 지정합니다. 파일 하나의 크기를 HDFS Blocksize에 일치 하도록 생성 하는 것이 권장 됩니다.
df.repartition(cnt),df.coalesce(cnt)를 통해 수정 할 수 있습니다. - Shuffle Partition: Join, groupBy 등의 연산을 수행할 때 사용 됩니다.
spark.sql.shuffle.partitions로 설정을 변경 할 수 있습니다.
이 설정들을 적절히 활용 하여, Shuffle 과정에서 Shuffle Spill이 일어 나지 않도록 최적화를 하는 것이 중요합니다.
그러면 파티션과 Executor 설정을 어떻게 해야 할까요?
일단 통상 적으로 알려진 사항은 Shuffle Partition 크기가 100 ~ 200MB 정도 나오게 끔 쿼리를 조정 해 주는 것이 좋습니다. Shuffle Partition이 너무 커져서 Memory Spill을 방지 하기 위함 입니다. 또한, Core를 최대한 효율적으로 활용 하기 위해, Instance * Executor Core의 배수로 Shuffle Partition을 지정 하는 것이 좋습니다.
결론적으로는 최적화는 제일 먼저 쿼리를 통해, Shuffle Partiton 크기가 커지지 않도록 조정 하고, Partition 수를 Shuffle Spill이 발생하지 않으면서, 가용 가능한 CPU Core 리소스 안에서 증가 시키고, Core 당 메모리 또한, Shuffle Partition 크기 를 감당 할 수 있는 수준으로 조정 할 수 있게 하여야 합니다. 즉, Executor당 Core, Instance당 Memory, Instance 수를 잘 조정 하여야 한다는 이야기 입니다.
다음 시간에는 쿼리 최적화를 하는 방법을 한 번 가져 보도록 하겠습니다. 감사합니다.
Reference
- https://spark.apache.org/docs/latest/configuration.html
- https://tech.kakao.com/2021/10/08/spark-shuffle-partition/
- https://velog.io/@busybean3/Apache-Spark-%EC%95%84%ED%8C%8C%EC%B9%98-%EC%8A%A4%ED%8C%8C%ED%81%AC%EC%9D%98-%EB%A9%94%EB%AA%A8%EB%A6%AC-%EA%B4%80%EB%A6%AC%EC%97%90-%EB%8C%80%ED%95%B4%EC%84%9C