저번 시간에는 Spark On Kubernetes에 대한 이론을 배웠습니다. 오늘은 Spark On Kubernetes에 대한 실습을 진행 하도록 하겠습니다.
사전 준비
- Docker
- Minikube (Kubernetes 1.20 버전 이상)
- kubectl
- Spark 3.0 버전 이상
최신 버전일 수록 좋습니다. 얼마 전에 구형 Docker가 깔려 있는 맥북에서 진행을 해 봤는데 Pod이 생성이 안되더군요..
Pyspark Image Build & Push
Kubernetes 에서 Spark Application을 수행 하기 전에, Spark Docker Image의 빌드가 선행 되어야 합니다. 일단. $SPARK_DIR (Spark가 설치된 경로) 안에, ./bin/docker-image-tool.sh를 이용 하여, Spark Base Image를 Build 할 수 있습니다.
해당 셸 스크립트의 build 관련 한 파라미터는 다음과 같습니다.
-f file: (Optional) JVM 기반 Image 빌드를 위한 Dockerfile 을 입력 합니다. 기본적으로 Spark와 함께 제공되는 Dockerfile을 빌드합니다. Java 17의 경우-f kubernetes/dockerfiles/spark/Dockerfile.java17을 사용합니다.-p file: (Optional) PySpark Image 빌드를 위한 Dockerfile을 입력 합니다. Python 종속성을 빌드하고 Spark와 함께 제공됩니다. 지정하지 않으면 PySpark 도커 이미지 빌드를 건너뜁니다.-R file: (Optional) SparkR Image 빌드를 위한 Dockerfile을 입력 합니다. R 종속성을 빌드하고 Spark와 함께 제공 됩니다. 지정하지 않으면 SparkR 도커 이미지 빌드를 건너뜁니다.-r repo: 레포지토리 주소를 입력 합니다.t tag: 빌드 된 이미지의 Tag를 입력 합니다,
일단 Spark Base Image를 빌드 해 보겠습니다. Kubernetes 에서 Spark Job을 구동 시키기 위해 기본적으로 만들어져 제공 된 Dockerfile을 사용 합니다. (./kubernetes/dockerfiles/spark/bindings/python/Dockerfile, SparkR은 ./kubernetes/dockerfiles/spark/bindings/R/Dockerfile 입니다.)
$ cd $SPARK_DIR # spark directory
$ eval $(minikube docker-env) # minikube docker image storage에 접근 하기 위함.
$ ./bin/docker-image-tool.sh -r k8s -t 1.0 -p ./kubernetes/dockerfiles/spark/bindings/python/Dockerfile build일단, 폴더를 하나 생성 한 후, 다음과 같이 파일을 생성하여 코드를 입력 해 줍니다.
<this repository path>/python/Dockerfile
FROM k8s/spark-py:1.0
COPY ./script /python<this repository path>/python/script/rdd_example.py
from pyspark import SparkContext, SparkConf
if __name__ == "__main__":
conf = SparkConf().setAppName("calculate_pyspark_example")
sc = SparkContext(conf=conf)
data = [i + 1 for i in range(10000000)]
distData = sc.parallelize(data)
print("sum :", distData.reduce(lambda a, b: a + b))그 다음, 방금 만들어진 Base Image를 이용 하여, Application image를 빌드 합니다.
$ cd <this repository path>/python
$ eval $(minikube docker-env)
$ docker build -t pyspark-on-k8s:1.0 .
$ minikube image load pyspark-on-k8s:1.0그 이후에 빌드된 모든 이미지를 확인 하기 위해, docker image ls를 입력 합니다.
$ docker image ls
REPOSITORY TAG IMAGE ID CREATED SIZE
pyspark-on-k8s 1.0 00a4af077a09 About a minute ago 938MB
k8s/spark-py 1.0 985cf805549a 13 days ago 938MB
k8s/spark 1.0 bd8ba88688d4 13 days ago 601MB
...How To Run Spark Application
Kubernetes에서 Spark Application을 실행 하기 전에, k8s service account, k8s clusterrolebinding를 생성 하여야 합니다. 왜냐 하면 Spark on K8S가 Driver Pod에서 Executor Pod의 상태를 관리 하는 형식이기 때문에, Driver Pod이 Pod edit 권한이 있는 service account를 가지고 있어야 합니다.
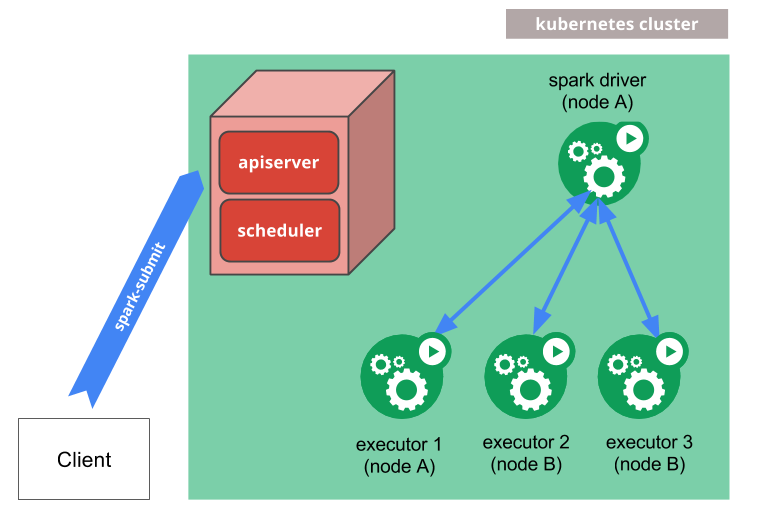
$ kubectl create serviceaccount spark
$ kubectl create clusterrolebinding spark-role --clusterrole=edit --serviceaccount=default:spark --namespace=defaultSpark Submit을 통해, Spark Job을 K8S에서 구동 할 수 있습니다.
$ kubectl proxy
Starting to serve on 127.0.0.1:8001
# In another terminal
$ kubectl create namespace spark-job
# rdd_example
$ ./bin/spark-submit \
--master k8s://http://127.0.0.1:8001 \
--deploy-mode cluster \
--name rdd-example \
--class org.apache.spark.examples.SparkPi \
--conf spark.kubernetes.container.image=pyspark-on-k8s:1.0 \ # Pyspark Image 지정
--conf spark.kubernetes.driver.pod.name=rdd-example-pod \ # Driver Pod 이름 지정
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \ # Service account 지정
--verbose \
"local:///python/rdd_example.py" # Docker file 기준의 Local 입니다.
$ kubectl logs rdd-example-pod # log check
# dataframe_example
$ ./bin/spark-submit \
--master k8s://http://127.0.0.1:8001 \
--deploy-mode cluster \
--name dataframe-example \
--class org.apache.spark.examples.SparkPi \
--conf spark.kubernetes.container.image=pyspark-on-k8s:1.0 \
--conf spark.kubernetes.driver.pod.name=dataframe-example-pod \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--verbose \
"local:///python/dataframe_example.py"
$ kubectl logs dataframe-example-pod # log check기타 자잘한 옵션들은 공식 문서에서 확인 할 수 있습니다.
client mode?
--deploy-mode client 옵션을 지정하여, Driver는 Spark Submit을 수행 하는 로컬에서, Executor는 Cluster 내에서 작동하게 할 수 있습니다.
$ ./bin/spark-submit \
--master k8s://http://127.0.0.1:8001 \
--deploy-mode client \
--name dataframe-example \
--class org.apache.spark.examples.SparkPi \
--conf spark.kubernetes.container.image=pyspark-on-k8s:1.0 \
--conf spark.kubernetes.driver.pod.name=dataframe-example-pod \
--conf spark.kubernetes.authenticate.driver.serviceAccountName=spark \
--verbose \
"local://<this repository path>/python/script/rdd_example.py" # Spark-submit에 있는 로컬에서 구동
