Spark
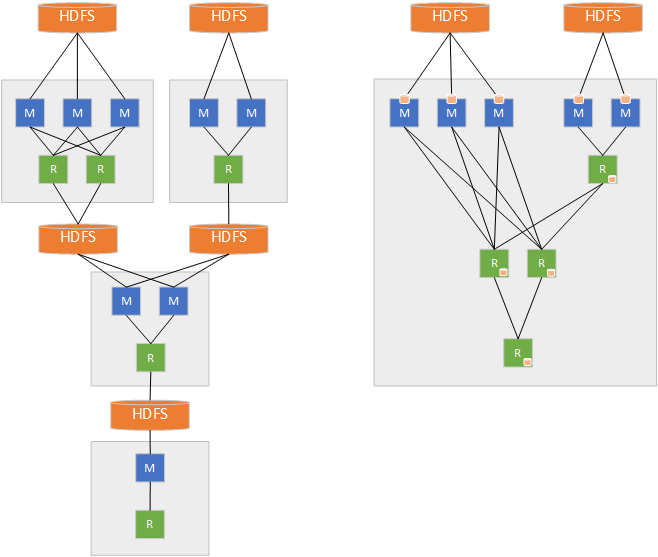
Apache Spark는 기존 Hadoop의 MapReduce 형태의 클러스터 컴퓨팅의 단점을 보완하기 위해 탄생한 프레임워크 입니다. 기존 하둡의 MapReduce에서는 Disk에서 데이터를 읽은 후, Mapping, Shuffling, Reducing의 과정을 거쳐서, 다시 Disk에 저장하는 형식으로 진행 되는데요, 이는 Disk I/O가 자주 발생 하기 때문에, 속도가 상대적으로 느리다는 단점이 있습니다.
하지만 Apache Spark는, RDD, Data Frame, Data Set을 바탕으로, In-Memory 연산을 통해, Disk I/O 대신, Memory I/O로 100배가 빠른 연산 속도를 이뤄 낼 수 있었습니다. 그 대신, In-Memory에서 작동 하기 때문에, 많은 양의 데이터를 메모리에 올려서 연산 하기에는 무리가 있다는 단점이 있습니다. 그렇기 때문에, 용량이 많지는 않지만, 빠른 연산을 요구 하는 경우에 자주 쓰이죠. 자주 사용되는 Cluster Manager로는 YARN, Apache Mesos가 있습니다.
Kubernetes
Kubernetes는 컨테이너를 쉽고 빠르게 배포/확장하고 관리를 자동화해주는 Container Orchestration Tool 입니다. Kubernetes 시스템을 통해, 다음을 제공 받을 수 있습니다.
- 서비스 디스커버리와 로드 밸런싱: DNS 이름, 혹은 자체 IP 주소를 이용하여 컨테이너를 노출 해 주고, 트래픽이 많아지면 로드 밸런싱을 제공 하여 줍니다.
- 스토리지 오케스트레이션: 로컬 저장소, 클라우드 공급자 등과 같은 저장소 시스템을 자동으로 탑재 하게 할 수 있습니다.
- 자동화된 롤아웃과 롤백: 컨테이너의 원하는 상태를 지정 해 놓으면, 이에 맞춰 롤아웃, 롤백을 자동으로, 원하는 속도로 수행 해 줍니다.
- 자동화된 빈 패킹 (bin packing): 컨테이너화된 작업을 실행하는 데 사용할 수 있는 쿠버네티스 클러스터 노드를 제공 하는데, 컨테이너가 필요로 하는 CPU와 메모리를 적정 하게 제공 해 줍니다.
- 자동화된 복구 (self-healing): 실패한 컨테이너를 다시 시작하고, 컨테이너를 교체하는 기술을 가지고 있습니다.
- 시크릿과 구성 관리: 암호, OAuth 토큰 및 SSH 키와 같은 중요한 정보를 관리 할 수 있습니다.

Why Spark On Kubernetes?
Spark Job를 왜 Kubernetes 환경에서 돌리는 것에 대한 의논이 왜 나왔을까요? 기존의 Hadoop Ecosystem에서 사용 하던 YARN도 있는데 말이죠.
YARN Cluster Manager
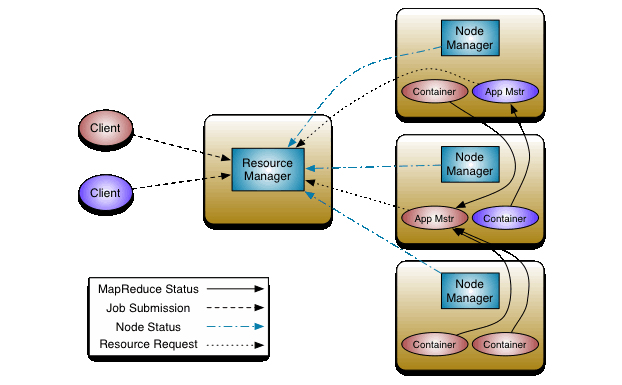
YARN이라는 Cluster Manager를 이용하여 Spark 연산을 수행 할 수 있습니다. YARN은 다음과 같은 구조를 가지고 있는 데요, 수행 과정은 다음과 같습니다.
- 클라이언트는 Resource Manager에게 Application Master 실행을 요청 합니다.
- Resource Manager는 컨테이너에서 Application Master을 실행 할 수 있는 Node Manager를 찾습니다.
- Node Manager에서 컨테이너 생성 후 Application Master를 실행 합니다.
- 분산 처리를 위해, Resource Manager에게 더 많은 컨테이너를 요청합니다.
- 분산 처리를 수행할 수 있는 다른 Node Manager에게 컨테이너 생성을 요청 한 후, 분산 처리를 수행 합니다.
이렇게 보면 딱히 문제가 없는거 같지만, YARN 자체에는 내재 되어 있는 문제가 있습니다.
첫 번째는, 운영적인 측면입니다. YARN에서 프로세스를 수행 하게 된다면, 의존성 문제가 발생 하게 됩니다. 단일 Spark 버전만 사용 할 수 있기 때문에 발생 하는 멀티 테넌시 (단일 소프트웨어 인스턴스로, 여러 사용자 그룹에 서비스를 제공 하는 아키텍처) 운영 불가 문제, 성능을 위해서 Spark를 업그레이드 하려고 할 때 YARN 클러스터 전체를 업그레이드 해야 하는 문제 등, 여러 가지 문제가 내제 되어 있습니다.
두 번째는, Resource 문제 입니다. 기존에 대기 하고 있는 Node Manager에서 Task를 수행 하면, Kubernetes에 비해, 네트워크를 새로 연결 하고, Pod을 굳이 띄울 필요가 없으니, Overhead 측면에서는 YARN이 이득일 수도 있습니다. 하지만, 어떤 연산은 메모리가 더 필요하고, 어떤 연산은 CPU가 더 필요 할 수도 있습니다. YARN은 모든 Job에 대해서 동일 한 Resource를 할당하는 Container를 제공 합니다. 그렇기 때문에, 노는 CPU, 노는 메모리가 발생 할 수도 있는 것이죠.
세 번째는, Performance 입니다. 최신 버전 (3.2)에서는 Kubernetes 상의 성능 및 안정성 문제를 개선하여, Amazon에서 테스트 해 본 결과, YARN 보다 Kubernetes에서 Spark job을 돌리는 게 5%의 성능 향상을 불러 왔다고 하네요. Map-Reduce 과정의 Shuffling 과정은 많은 네트워크 I/O와, 많은 메모리를 사용 하는데, 이에 맞게 높은 I/O를 구동 할 수 있으면서, 대용량 메모리인 인스턴스를 이용 하여, 빠른 수행을 가능 하게 하는 거죠.
이들을 Spark On K8S는, 컨테이너화, 리소스 공유, 효과 적인 Auto Scaling을 통해서 이를 해결 합니다. 또한, Kubernetes 위에서 작동한다는 것은, Kubernetes의 다양한 생태계를 사용 할 수 있다는 걸 의미 합니다. 개발 상의 많은 이점이 존재 한다는 뜻이죠.
How To Work?
내부 동작은 다음과 같습니다.
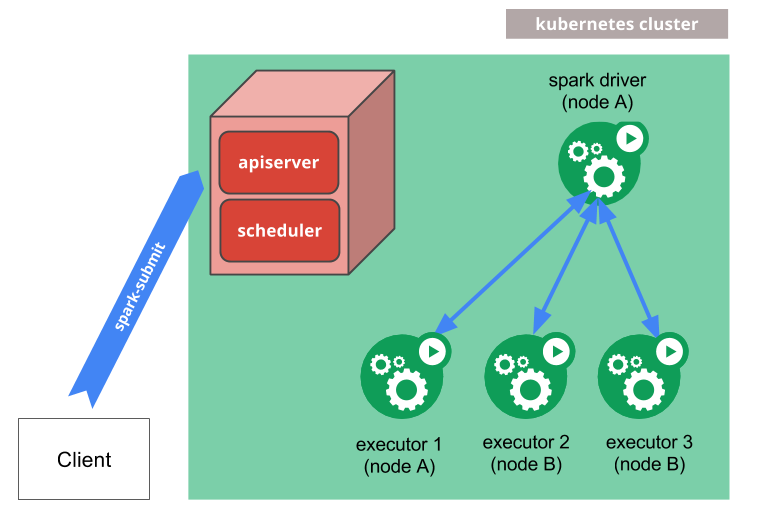
- spark-submit을 통해서 Spark는 Kubernetes Pod 내에서 실행되는 Spark Driver를 생성 합니다.
- Spark Driver는 Kubernetes Pod 내에서 Executor를 생성하고 연결하여, Application을 수행 합니다.
- Application이 완료되면, Executor Pod가 종료되고 정리 되지만, Driver Pod은 완료 상태로 로그를 유지하고, 가비지 수집 혹은 수동으로 정리 될 때 까지 남아 있습니다.
모니터링은 Prometheus를 통해 수행 할 수 있습니다. $SPARK_CONF_DIR 내에 Prometheus 관련 설정을 넣어 주신 후에, 다음과 같이, spark-submit 시에 spark.kubernetes.driver.annotation.prometheus.io 관련 설정을 만져 주면 가능합니다. 실행 중에 http://<spark-driver>/metrics/executors/prometheus에 접근 하면 확인 가능 합니다. 자세한 건 다음 시간에 알아 보도록 해요.
$ spark-submit \
--conf spark.ui.prometheus.enabled=true \
--conf spark.kubernetes.driver.annotation.prometheus.io/scrape=true \
--conf spark.kubernetes.driver.annotation.prometheus.io/path=/metrics/executors/prometheus \
--conf spark.kubernetes.driver.annotation.prometheus.io/port=4040 \
...다음 시간에는 이를 실제로 구현 해 보면서, 어떤 문제점이 내재되어 있는지를 알아 보는 시간을 가져 보도록 하겠습니다.