안녕하세요, 박민재입니다. 저번 시간에는 Spark Operator가 무엇인지 간단하게 알아 보았는데요, 이번 시간에는 실제로 Spark Operator Helm Chart를 설치하여, Spark Operator 관련 구동 준비를 한 후, Spark Operator 관련 Resource를 작성 하여 실제 Job을 제출 해 보는 시간을 가져 보도록 하겠습니다.
Spark Operator Helm Chart
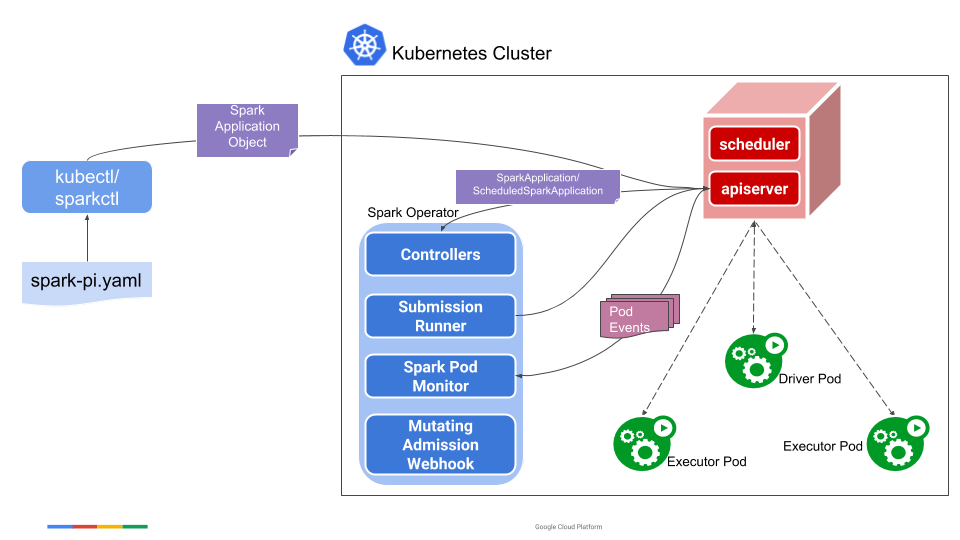
Spark Operator를 사용 하기 위해서는 저번 시간에 언급 드렸던 것처럼, Spark Operator Resource를 해석 할 수 있는 Component들이 먼저 구동 되어야 하고, 이를 통해 Cluster가 SparkApplication Resorce가 제출 되었을 때 Resource를 해석 할 수 있어야 합니다. 이를 위해 Spark Operator Component들을 Helm Chart를 통해 Cluster에 우선적으로 설치하는 작업이라고 이해해 주시면 됩니다.
저번에 언급 드렸던, Controller, Submission Runner, Spark Pod Monitor, Mutating Admission Webhook이 이에 해당합니다.
Helm Chart를 설치 하기 전, 해당 버전의 Helm과 Kubernetes가 준비 되어야 합니다.
- Helm >= 3
- Kubernetes >= 1.16
이 둘이 설치 되었다면, Helm Repository를 추가 하여 주고, Update를 수행 한 후, Kubernetes Cluster에 Operator를 설치 합니다.
helm repo add spark-operator https://kubeflow.github.io/spark-operator
helm repo update
# helm install [RELEASE_NAME] spark-operator/spark-operator
helm install spark-operator spark-operator/spark-operator \
--namespace spark-operator # namespace 지정 \
--create-namespace # 해당 namespace를 생성 하며 Install추가적으로 Helm Chart를 설치 할 때, --set 을 통해 Flag를 지정 하여 옵션을 추가 하여 줄 수 있습니다. 추가 할 수 있는 Value 관련 정보는 다음을 확인 해 주세요.
helm install my-release spark-operator/spark-operator \
--namespace spark-operator \
--create-namespace \
--set webhook.enable=true대표적으로 자주 사용 되는 Value들은 다음과 같습니다.
webhook.enable: Mutating Webhook을 활성화합니다.spark.jobNamespaces: 실제 Spark Job을 수행하는 Pod이 할당 될 Namespace를 설정 합니다. (ex:--set "spark.jobNamespaces={test-namespace}")image.repository: Controller, WebHook 등에서 사용하는 Docker Image의 Repository를 기입 합니다.image.tag: Controller, WebHook 등에서 사용하는 Docker Image의 Tag를 선택 합니다.
Spark Operator Resource
Helm Chart 설치가 완료 되었다면, 그 다음은 SparkApplication Resource를 등록 할 차례 입니다. YAML 파일을 작성 한 후에 이를 kubectl로 제출 하는 방식으로 주로 사용하는데요, 기본적인 틀은 다음과 같습니다.
아래와 같이 Spark Application 관련 정보를 입력 하여 주면, 이를 spark-submit 으로 변환하여 제출 해 줍니다. 그 이후, Spark Pod Monitor를 통해 Application 상태를 모니터링 하는 방식입니다.
apiVersion: sparkoperator.k8s.io/v1beta2
kind: SparkApplication
metadata:
name: spark-pi
namespace: default
spec:
type: Scala
mode: cluster
image: spark:3.5.1
mainClass: org.apache.spark.examples.SparkPi
mainApplicationFile: local:///opt/spark/examples/jars/spark-examples_2.12-3.5.1.jarspec.type: Java, Python, R, Scala 등 Application의 종류를 입력 합니다.spec.mode: client, cluster, in-cluster-client 등, Deploy 방식을 선택 할 수 있습니다. 현재 안정적으로 제공 하는 DeployMode는 cluster가 유일 하기 때문에 cluster 모드로 설정 하는 것을 권장합니다.spec.image: Driver, Executor, inin-container의 Image를 지정합니다.spec.mainClass: Java/Scala Application의 MainClass를 지정 합니다.spec.mainApplicationFile: Application의 파일 경로를 지정합니다. Hadoop 관련 설정이 완료 되었다면, HDFS 내의 파일도 접근 가능합니다.
Application Dependencies
Application에 대한 의존성 추가를 위해서는 다음과 같은 옵션을 추가하여 주면 됩니다.
spec:
deps:
jars:
- local:///opt/spark-jars/gcs-connector.jar
files:
- gs://spark-data/data-file-1.txt
- gs://spark-data/data-file-2.txt
repositories:
- https://repository.example.com/prod
packages:
- com.example:some-package:1.0.0
excludePackages:
- com.example:other-package
...spec.deps.jars: Application에 Jar File로 Dependency를 추가 합니다.spark-submit의--jarsOption에 해당 합니다.spec.deps.files: Application에 File을 추가 합니다.spark-submit의--filesOption에 해당 합니다.spec.deps.repostories: 설치할 Package가 있는 Repository를 지정 합니다.spec.deps.packages: 설치할 Package를 지정 합니다.spec.deps.excludePackages: Package 설치 과정에서 함께 설치되는 Package 중 설치에서 제외할 Package를 지정 합니다.
Spark Configuration
Spark Configuration은 spec.sparkConf 하위에 삽입 하여 설정 할 수 있습니다. 참고로 Type 관련 설정 때문에, spec.sparkConf 하위에 있는 모든 Key의 Value는 string 이어야 합니다.
spec:
sparkConf:
spark.ui.port: "4045"
spark.eventLog.enabled: "true"
spark.eventLog.dir: "hdfs://hdfs-namenode-1:8020/spark/spark-events"
...Driver + Executor Spec
Driver와 Executor Spec은 다음과 같이 설정 해 줄 수 있습니다.
spec:
driver:
cores: 1
coreLimit: 200m
memory: 512m
labels:
version: 3.1.1
serviceAccount: spark
javaOptions: "-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap"
executor:
cores: 1
instances: 1
memory: 512m
labels:
version: 3.1.1
serviceAccount: spark
javaOptions: "-XX:+UnlockExperimentalVMOptions -XX:+UseCGroupMemoryLimitForHeap"
...공통적인 옵션들은 다음과 같습니다.
cores: 하나의 Instance에 몇개의 Core를 할당 할지 설정 합니다. Instance는 Pod으로 할당 됩니다.memory: 하나의 Instance에 얼마만큼의 Memory를 할당 할지 설정 합니다. Instance는 Pod으로 할당 됩니다.coreLimit: Pod별 CPU core를 얼마만큼으로 제한할 지 설정 합니다.memoryOverhead: off-heap Memory를 얼마만큼 할당할 지 설정 합니다.serviceAccount: 어떤 Service Account로 Pod을 할당 할지 설정 합니다.javaOptions: Java Options를 설정 합니다.image: 어떤 이미지를 사용 할 지 설정 합니다.
그 외에도 Env, ConfigMap, Secret, Volume, Pod Affinity 등 또한 설정 해 줄 수 있는데요, 해당 내용은 공식 Document 주소로 갈음 하도록 하겠습니다.
YAML 파일이 작성이 되었다면 다음과 같이 kubectl 로 제출 할 수 있습니다.
kubectl apply -f your-app.yamlkubectl describe를 통해 다음과 같이 Application의 상태를 확인 할 수 있습니다.
kubectl describe sparkapplication [YOUR APPLICATION]
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SparkApplicationAdded 5m spark-operator SparkApplication spark-pi was added, enqueued it for submission
Normal SparkApplicationTerminated 4m spark-operator SparkApplication spark-pi terminated with state: COMPLETED다음 시간에는 Spark Operator의 고가용성을 위한 설정, Scheduling 등의 방법에 대해서 알아 보도록 하겠습니다.