오늘은 Spark 성능 튜닝에서 가장 중요한 SQL Tuning에 대해서 알아 보도록 하겠습니다.
사실 파라미터(Shuffle Partition 갯수, Executor Instance, Core, Memory 조정) 튜닝 또한, 도움이 될 수 있겠습니다만, 그 전에 Execution Plan이 잘 짜여져 있지 않다면, 파라미터 튜닝이 큰 영향을 주지는 못할 것 입니다.
What is Execution Plan?
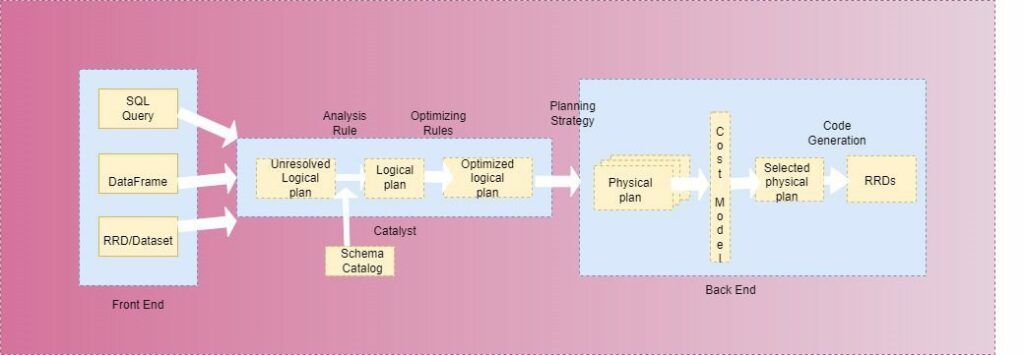
Exection Plan은 뭘까요? 우리가 Spark SQL API인 Dataframe Aggregation Code를 작성 했다고 가정 하겠습니다. 그렇게 되면, Spark 내부의 Catalyst Optimizer는 다음과 같은 동작을 수행 합니다.
- DataFrame, SQL, RDD로 작성 된 코드를 최적화 되지 않은 Unresolved Logical Plan으로 변환 합니다.
- Schema 등을 확인 하여, 해당 Unresolved Logical Plan이 Spark 상에서 가동 가능 하다는 판단이 되면, 이를 Logical Plan으로 전환 하고, 내부에 구현되어 있는 Optimizing Rules에 기반하여, 이를 최적화된 Optimized Logical Plan으로 구현 합니다.
- 최적화 된 Optimized Logical Plan을 각 Executor에 전달하여 수행 합니다.
우리는 실제로 연산이 되는 것을 어떻게 확인 할 수 있을까요? 우리는 explain() 메서드를 통해, 논리적으로 어떻게 연산이 진행 되는지 확인 할 수 있습니다.
import spark.implicits._
val data = Seq(("1", 20000), ("1", 30000), ("2", 10000), ("2", 20000), ("3", 5000), ("3", 10000))
val testDf = spark.createDataFrame(data).toDF("id", "score")
val resultDf = testDf.groupBy(col("id")).agg(sum("score"))
resultDf.explain()== Physical Plan ==
AdaptiveSparkPlan isFinalPlan=false
+- HashAggregate(keys=[id#16], functions=[sum(score#17)])
+- Exchange hashpartitioning(id#16, 200), ENSURE_REQUIREMENTS, [plan_id=11]
+- HashAggregate(keys=[id#16], functions=[partial_sum(score#17)])
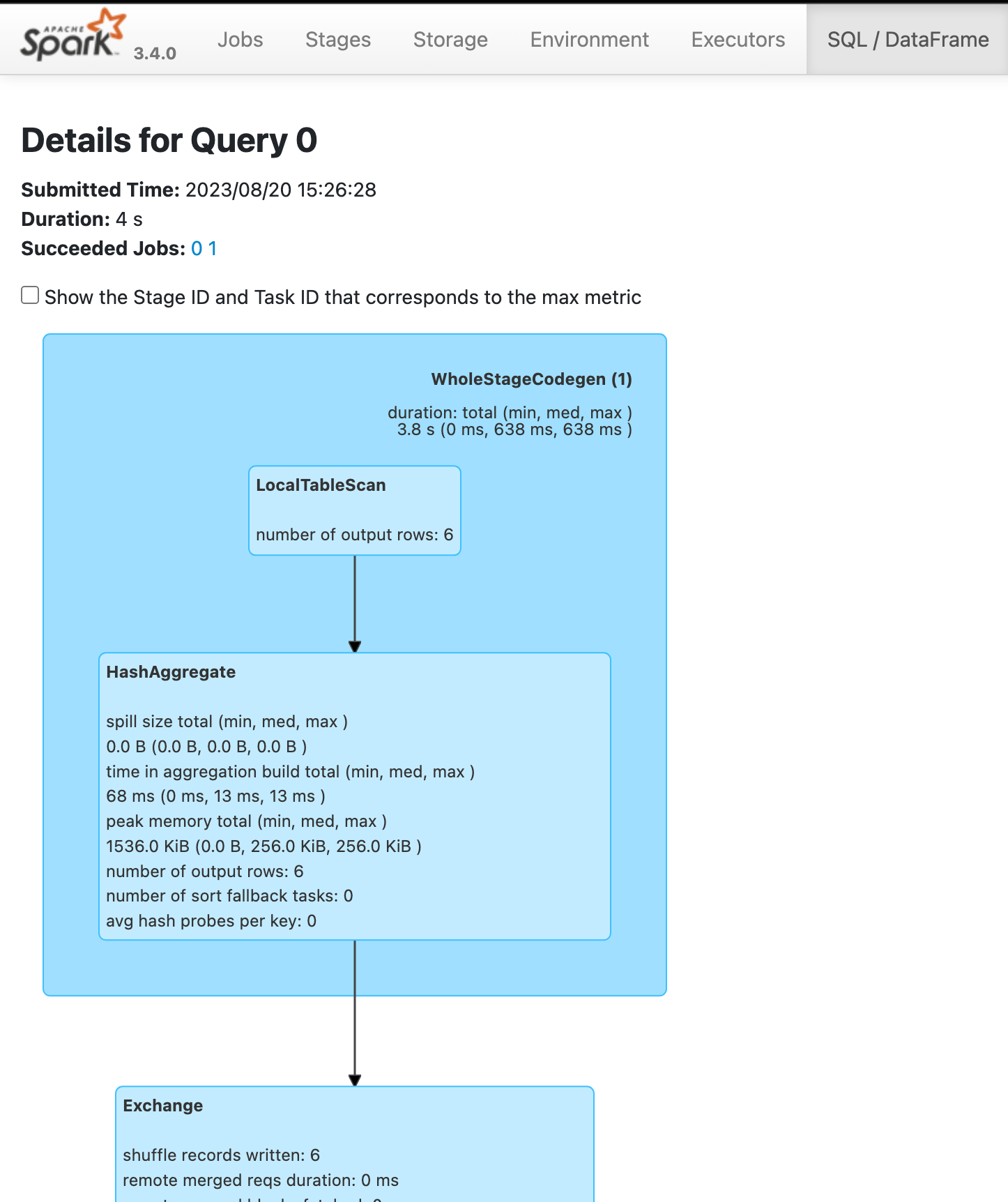
+- LocalTableScan [id#16, score#17]혹은 실제로 Physical Plan (Execution Plan)이 실행 된 이후, Spark Web UI의 SQL에서 확인 해 볼 수도 있습니다.
실제로 Web UI를 잘 이용하면 좋은 것이, 각 연산 Job, Stage 별로 각 Executor 마다 얼마 만큼의 Data Input / Output이 발생 했고, Shuffle이 얼마나 발생 했는지, Data Spill은 얼마나 있었는지를 확인 할 수 있기 때문에, 튜닝 포인트를 찾을 때 유용 합니다.
How To Optimize Query
일단 일차적으로, 알고리즘 문제를 푼다고 생각하고, 어떻게 해야 연산량을 줄일 수 있을까? 라는 생각으로 접근 하셔야 합니다. 도움이 될 만한 몇 가지 테크닉이 있습니다.
Select Column & Filtering First
Spark Application에서 Memory 점유율을 낮추기 위해, Shuffle Data의 크기를 줄이기 위해 필요한 Column만 추출 하는 것이 중요 합니다., 또한, 데이터의 Record 갯수를 줄일 수 있는 Filtering은 맨 앞단에서 진행을 시켜 주는 것이 중요 합니다.
Adaptive Query Execution
Adaptive Query Execution을 이용하면, Spark가 Runtime에 Execution Plan을 변경 하게 할 수 있습니다. 이는 Spark Application에서 Runtime 도중의 Data 통계를 수집하여 다음과 같은 효과를 얻을 수 있습니다.
- Query 수행 간 효율적인 Partition 갯수를 설정하여 줌
- Skew(특정 Partition에 데이터가 몰리는 현상) data 같은 경우에 대해 Partition 증설
- Join시 Broadcast Join 혹은 Sort Merge Join의 사용을 결정
이는 spark.sql.adaptive.enabled 설정을 true 로 지정 하여 주면 됩니다.
Use Only Spark SQL API
가능한 UDF 함수를 사용 하지 않고, Spark SQL 내부의 함수를 이용하여, Logical Logic이 Optimizer를 태울 수 있도록 해 주는 것이 중요 합니다. 또한, 일반 Dataset, RDD를 사용 하는 것 보다는 Catalyst Optimzer에 최적화 된 DataFrame을 사용 하는 것이 Memory와 CPU의 효율성을 극대화 할 수 있습니다.
coalesce() vs repartition()
Partition 갯수를 늘리는 것이 아니라면, coalesce()를 사용 하는 것이 더 좋습니다. coalesce()는 Partition 갯수를 줄이는 데 있어, repartiton()의 최적화 된 버전입니다.
Etc
기타 중요한 테크닉은 다음과 같습니다.
- Network I/O를 많이 사용하게 되는 Shuffle 연산을 최소화 할 것.
- 만들어진 DataFrame을 재사용 하게 된다면, Cache를 잘 사용 할 것.