Archive된 사유는 다음 중 하나에 해당 됩니다.
- 작성 된지 너무 오랜 시간이 경과 하여, API가 변경 되었을 가능성이 높은 경우
- 주인장의 Data Engineering으로의 변경으로 질문의 답변이 어려워진 경우
- 글의 퀄리티가 좋지 않아 글을 다시 작성 할 필요가 있을 경우
Data Science, 어디부터 해야 할까?
안녕하세요? Justkode 입니다. 일단, 제가 대학교 1, 2학년 때 하던 고민들이 있었습니다. "나는 자연어 처리 쪽으로 공부를 하고 싶은데, 어디부터 해야할까?" 주변에 딱히 자연어 처리 쪽으로 공부 하는 선배들도 적었고, 그래서 학교에서 하는 프로젝트만 하다 보니, 어쩌다 보니 타의적(?) 풀스택 프로그래머 가 되어 있었습니다. 지금은 학기 중에 빅데이터 관련 프로젝트도 진행 해 보고, 군 복무 중에는 머신러닝, 딥러닝 이론 관련 공부도 진행 하면서 나름의 지식을 쌓은 것 같아요.

실제로 이번학기에 진행한 3GB 가량의 MBTI 가량 데이터로 추출한, 특정 유형별 연관 단어 추출 결과 입니다.
그래서 이번 기회로 어떻게 Data Science를 공부 할 수 있을까에 대한, 여러분들의 고민을 해결 하기 위해, 데이터 전처리 부터, 기본 적인 수학이론, Machine Learning, Deep Learning 이론들을 여러분들과 공유 하고자 합니다. 물론 깊게 다루지는 않을 예정입니다. 이 분야에 대해서 깊게 공부하기 위해 필요한 자료들을 매 포스트 끝에 첨부 할 테니 참고 해 주세요!
First, You Need to get to know...
첫 번째는 Linear Algebra (선형대수) 입니다. 간단한 행렬 연산과, 행렬 곱을 통해 나타나는 사영의 의미, 고유값과 고유벡터에 대한 가벼운 지식은 알고 계셔야 합니다.
두 번째는 Probability and random variables (확률과 랜덤변수) 입니다. 고등학교 교육과정의 확률과 통계 지식으로 충분합니다.
세 번째는 Python 기초 문법 지식입니다. 이 시리즈는 Python을 통해 진행 됩니다.
Bayes' theorem
Bayes' theorem은 Data Science 에서 가장 중요한 식 중 하나 입니다.
A, B 두 랜덤 변수 (혹은 사건)이 독립일 시 위 식은 성립합니다. 하지만, 이 식이 완전한 독립이 아니더라도 귀납적, 경험적으로 문제를 해결하기 위해 주로 사용됩니다. 이 식을 현실에 한 번 대입 해 볼까요?
저에게는 누나가 한 명 있고, 냉장고에 누나가 사놓은 아이스크림이 있다고 가정 하겠습니다. 다음과 같이 정리 해 보겠습니다.
- : 누나의 아이스크림을 먹는 사건. (A의 사전 확률)
- : 누나에게 두들겨 맞을(?) 사건. (B의 사전 확률)
그럼 다음과 같이 나타낼 수도 있겠네요,
- : 누나에게 두들겨 맞았을 때, 내가 누나의 아이스크림을 먹었을 확률. (사후 확률)
- : 누나의 아이스크림을 먹었을 때, 내가 두들겨 맞을 확률. (조건부 확률)
일단 누나의 아이스크림을 먹었을 때, 내가 두들겨 맞은 경우가 100% 라고 가정 하겠습니다. 그러면 라고 할 수 있겠네요.
엄마 입장에서 "누나의 아이스크림을 먹었을 때, 내가 두들겨 맞은 경우가 100%" 라는 사실을 알았다고 가정 하겠습니다. 또한, 제가 누나의 아이스크림을 먹는 확률이 10% 라고 가정 하겠습니다. 그러면 엄마는 "얘가 누나꺼 아이스크림을 훔쳐 먹었구나~" 라고 추정 할 확률은 라고 할 수 있겠네요.
여기서 사건 하나를 더 추가 해 보겠습니다.
- : 누나의 남은 치킨을 먹는 사건. (C의 사전 확률)
위와 마찬가지로 엄마 입장에서 누나의 남은 치킨을 먹었을 때, 내가 두들겨 맞은 경우가 100% 라는 사실을 알았다고 가정 하고, 제가 누나의 아이스크림을 먹는 확률이 50% 라고 가정 하겠습니다. 추가로, 저는 먹는 양이 많지 않은 관계로 치킨과 아이스크림을 동시에 먹지 않고, 그 이외에 누나에게 두들겨 맞는 일이 없다고 가정합니다.
그럼 다음 식들로 나타 낼 수 있겠네요.
자! 위의 가정을 통해서 만약 제가 누나한테 두들겨 맞고 있을 때, 엄마는 제가 뭘 했다고 유추 할 수 있을까요? 제가 또 누나꺼 치킨을 훔쳐 먹었다고, 추론 할 수 있을 것 입니다. 이렇게 저의 어머니는 사전 확률과, 조건부 확률에 대한 정보를 기반으로 사후 확률을 예측 할 수 있었습니다.
우리가 사례를 통해서 배우듯, 머신러닝도 이러한 아이디어에서 크게 벗어나지 않습니다. 우리가 특정 사진의 분류 모델을 학습시킬 때는 다음과 같은 과정을 거칩니다.
- **레이블 정보(무슨 사진인지)**와 **특징 정보(사진의 RGB값)**를 제공 받습니다.
- 특정 알고리즘을 통해 특징 정보에 대한 값을 바탕으로, 해당 정보가 무슨 레이블인지 판별 합니다.
- 손실 함수(loss function)를 이용하여, 추정한 값과 실제 값을 비교합니다. 추정 값이 실제 값과 비슷할 수록, 손실함수의 값은 작습니다.
- 특정 알고리즘 내부에 있는 파라미터를 조정하여, 손실 함수의 값을 줄여 나갑니다.
거시적인 측면에서 보자면, 이렇게 이야기 할 수 있습니다. 그림을 보고 A라고 판별하는 것은 사후확률 (), A가 그 그림에 나타나는 경우를 조건부 확률 ()이라고 하면, 우리는 A가 그 그림에 나타나 있다는 정보를 통해서, 그 그림이 A라고 판별하는 확률을 높여 나가는 것입니다.
즉, 핵심은 관찰을 통해 새로운 정보를 획득하고, 믿음의 정도 (Likelihood)를 업데이트 하는 것. 이것이 머신러닝의 핵심이며, 이는 베이즈 정리에 잘 나타나 있다고 이야기 할 수 있습니다.
Machine Learning? Deep Learning?
많은 사람들이 궁금해 합니다. 도대체 딥러닝과 머신러닝의 차이가 무엇인가요? 다음의 벤 다이어그램이 답을 줄 것입니다.
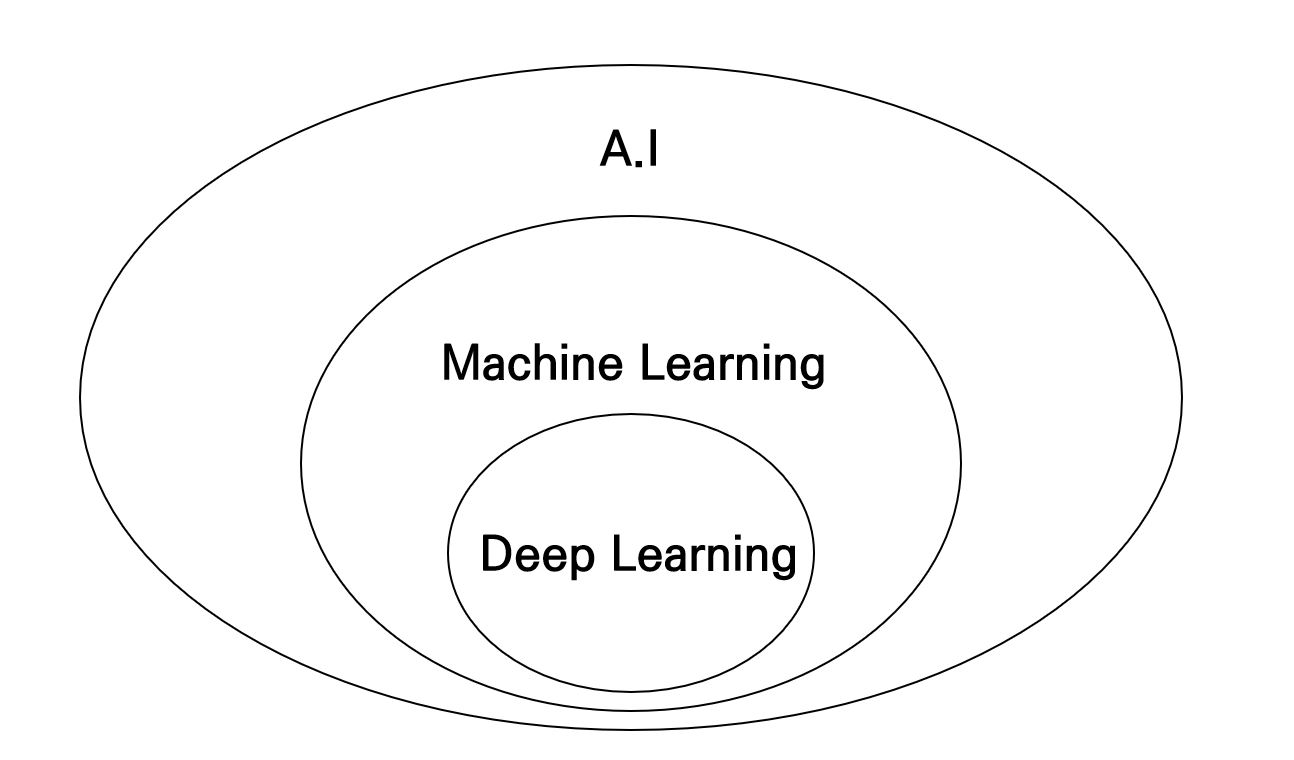
사실, 딥러닝은 머신러닝의 하위 개념이다.
Deep Learning은 사실 Machine Learning의 하위 개념입니다. 하지만 오늘날에 굳이 따지자면, Deep Learning이냐 Machine Learning이냐는 신경망 학습의 사용 유무에 따라 달라질 수 있겠습니다. 신경망 학습은 사람의 뇌 구조를 유사하게 따라하여 만든 구조로, 여러 층의 퍼셉트론을 쌓아 만든 모델이라고 할 수 있습니다. 하지만, 여러 층의 행렬 연산을 요구 하기 때문에 컴퓨팅 파워측면에서 효율적이지 않지만, 좋은 성능을 내는 모델을 만들 수 있습니다.
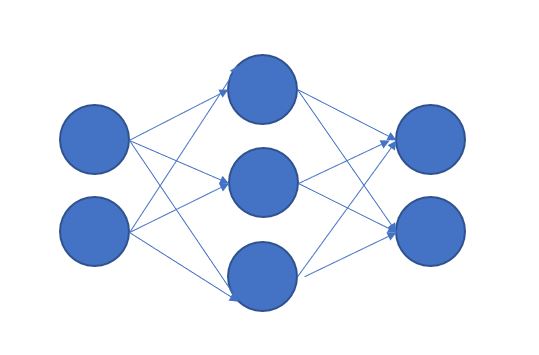
신경망 학습
그러면 딥러닝만 배워도 되지 않느냐? 라고 할 수 있습니다. 하지만, 많은 회사에서 속도와 효율적인 측면에서 일반 머신러닝 모델을 계속 차용하고 있으며, 많은 딥러닝의 아이디어는 모두 기존 머신러닝의 아이디어에서 온 것이기 때문에, 절대 머신러닝 이론을 무시 하고 딥러닝을 완벽하게 이해할 수는 없습니다.
- Deep Learning: 신경망을 이용한 학습, 연산량 매우 높음, 모델 정확도 매우 높음
- Machine Learning: 신경망을 이용하지 않고 통계학적인 원리 기반으로 학습, 연산량 낮음, 모델 정확도 높음
Contents
1. Orientation
Anaconda를 이용하여 개발 환경을 세팅하고, Data Science가 무엇인지, Machine Learning은 Deep Learning과 무엇이 다른지에 대해서 배워 봅니다.
2. Basic Math, Numpy
해당 강의를 진행하기 위해 필요한 수학 지식을 간단하게 복습 해 보고, Numpy 관련 실습을 진행 합니다.
3. Pandas
Pandas의 Series, Pandas에 대해서 다뤄 봅니다.
4. matplotlib
Matplotlib의 사용법에 대해서 배워 봅니다.
5. SQL
SQL문에 대해서 복습해 보는 시간을 가져 봅니다. Join 까지만 진행 합니다.
6. Machine Learning Basic
Machine Learning에 핵심이 되는 학습의 과정을 수학적인 관점에서 파악 해 봅니다.
7. Linear Regression, Logistic Regression
scikit-learn을 이용하여 선형 회귀 문제와 분류 문제를 해결 해 봅니다.
8. SVM, K-NN, Random forest
Machine Learning에서 자주 사용 되는 SVM, K-NN, Random forest를 실습 해 봅니다.
9. Normalization, PCA
정규화를 이용하는 이유를 수학적인 관점에서 파악해 보고, 정규화를 실시 하여 보며, PCA를 이용하여 정보의 손실을 최소화 하며 차원을 축소 시켜보는 실습을 진행합니다.
10. DNN
Pytorch를 통해 Deep Neural Network를 구축 해 봅니다.
11. CNN
이미지 인식에 주로 사용 되는 Convolutional Neural Network를 구축 해 봅니다.
12. RNN
자연어 처리, 시계열 데이터 처리에 주로 사용 되는 Recurrent Neural Network를 구축 해 봅니다.
13. GAN
경찰과 도둑 역할을 하는 두 가지 모델을 사용 하여, 진짜 같은 가짜 데이터를 생성하는 Generative Adversarial Network에 대해서 배워 봅니다.
마치며
가장 중요한 것은, 머신러닝, 딥러닝 모델을 짜는 것도 중요하지만, 그 내부의 수학적인 원리를 이해하고, 전처리가 왜 필요하고, 어떻게 해야 하는지, Computer Science의 관점에서 어떻게 연산양을 줄일 수 있고, 빠르게, 그리고 효율적으로 연산 할 수 있는지에 대한 고찰입니다. 외우려고 하거나, 그 미시적인 딥러닝의 세계를 이해하려고 하지 않으면, 좋은 모델을 만들 수 없습니다. 다음 시간에는 기본적인 수학과 numpy 사용법에 대해 공부해 보는 시간을 가져 보겠습니다.
p.s. 수학 못하는데 머신러닝 해도 되나요?
네, 가능합니다. 수학 식을 이해하고 적용할 수 있으면 돼요, 저 수학 겁나 못합니다.