Archive된 사유는 다음 중 하나에 해당 됩니다.
- 작성 된지 너무 오랜 시간이 경과 하여, API가 변경 되었을 가능성이 높은 경우
- 주인장의 Data Engineering으로의 변경으로 질문의 답변이 어려워진 경우
- 글의 퀄리티가 좋지 않아 글을 다시 작성 할 필요가 있을 경우
Recurrent Neural Network
안녕하세요? 오늘은 RNN, Recurrent Neural Network에 대해서 알아 보도록 하겠습니다.
RNN은 인공 신경망의 한 종류로, 내부 순환 구조로 이루어져 있어, 시간 정보를 가지거나, 순차적인 데이터를 학습 하는데 주로 이용합니다. 예를 들어, 자연어 처리, 문자열 처리, 시세 예측 등등에 사용 됩니다. 이는 순환 구조를 이용 하기 때문에, 시퀀스 길이에 관계없이 인풋과 아웃풋을 받아 들일 수 있는 매우 큰 장점을 가지고 있습니다.
RNN은 다음과 같은 구조를 갖습니다. Input(x) 값이 모델에 삽입 되면, Output(o) 값이 나오며, 새로운 State(h) 값이 생성 됩니다.
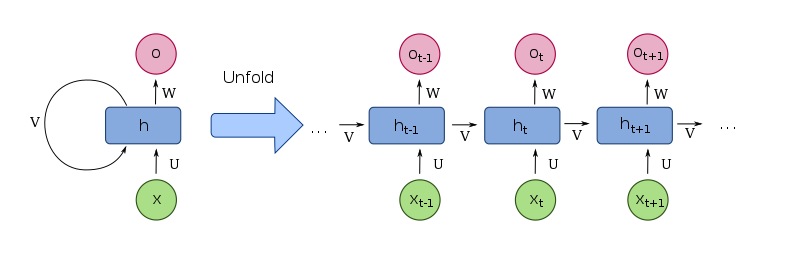
출처: 위키피디아
또한, RNN의 종류는 One to Many, Many to One, Many to Many 총 3가지가 있습니다. One to Many는 사진에 설명을 붙일 때 사용하고, Many to One은 감정 분석, Many to Many는 번역에 주로 사용 됩니다.
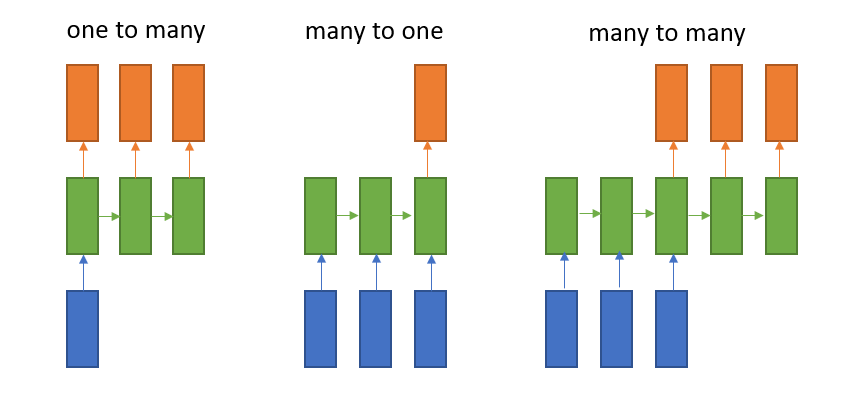
RNN 종류들
다음으로, RNN 내부에서 어떤 연산이 이루어 지는지 설명을 드리겠습니다.
- : Input Vector 입니다.
- : Hidden State 이며, 계산식은 입니다. 는 하이퍼볼릭탄젠트로, RNN의 활성화 함수로 사용 됩니다. 는 직전의 히든 state과 행렬 곱을 한 후 더해집니다. 는 Input Vector와 행렬 곱을 한 후 더해집니다.
- : Output Vector 입니다. 계산식은 이며, 현재 Hidden State인 와, Output Vector를 만들기 위한 가중치 가 행렬 곱을 하여, Output Vector가 만들어 집니다.
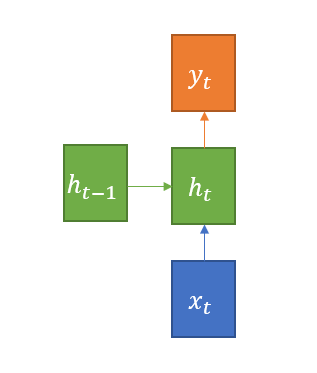
RNN 내부 연산
LSTM?
기존 RNN에는 뼈아픈 단점이 있는데, 시퀀스가 길면 길어 질수록, 역전파시 그래디언트가 줄어, Gradient Vanishing 문제가 발생, 학습 능력이 저하 되는 문제점이 있습니다. 그리하여 **LSTM (Long Short-Term Memory)**이 등장 하였습니다. LSTM은 기존 RNN 구조에, *cell-state ()를 추가 하여, 오래된 state도 잘 학습 할 수 있도록 설계한 것입니다.
아래 사진 처럼 볼 수 있듯이, 기존 함수를 뛰어 넘어, 더 많은 레이어들이 추가 된 것을 볼 수 있습니다. 여기서, 는 forget gate로, 과거 정보를 덜어 내기 위한 게이트 입니다. 는 input gate로, 현재 정보를 저장 하기 위해 사용 합니다.
각 레이어는 다음과 같은 값을 지닙니다.
여기서 는 시그모이드 함수 입니다.
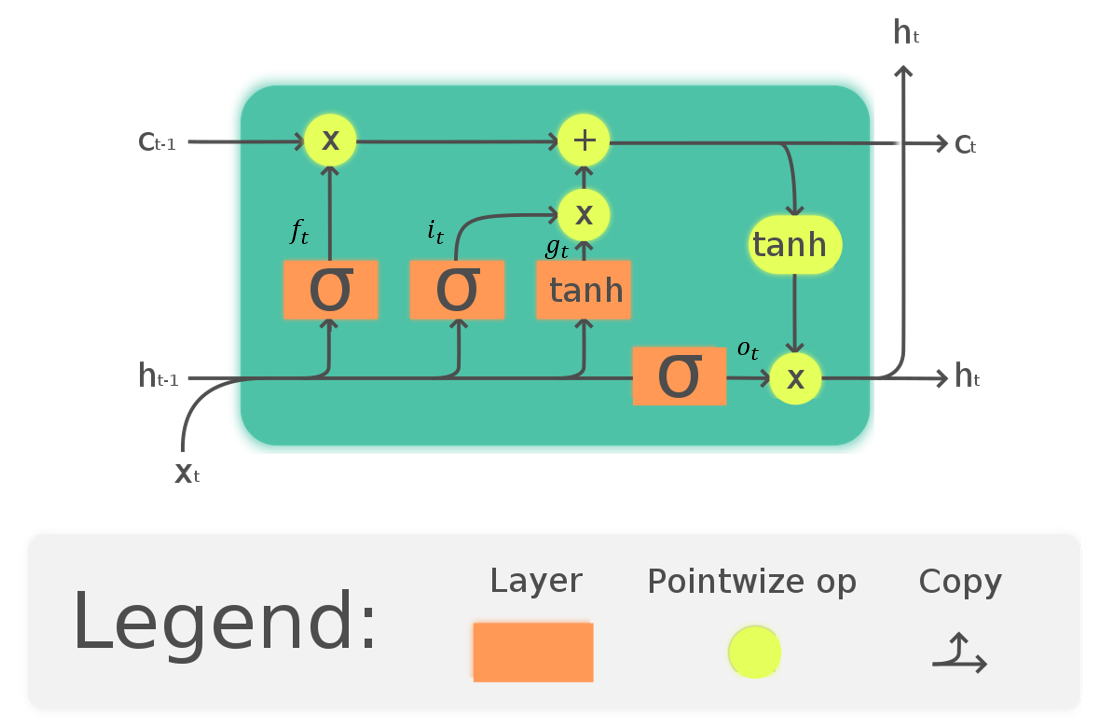
LSTM, 출처: 위키피디아
Code Implementation
이제 코드를 구현 할 시간입니다. 먼저 Module을 Import 해 보겠습니다.
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence그 다음, Input Data를 정제 해 보겠습니다. sentences에 있는 모든 단어들을 추출하여, word_list 에 삽입 하고, 이를 enumerate() 함수를 이용하여 각 단어마다 int형 숫자를 할당 해 줍니다. word_dict는 (키: 단어, 값: 숫자) 로 연결 할 수 있는 dict 객체 이며, number_dict는 (키: 숫자, 값: 단어) 로 연결 할 수 있는 dict 객체 입니다.
sentences = [
"i am happy", "you are happy", "feel good", "you feel good", "i am not sad", "you feel not bad",
"i am sad", "you are sad", "feel bad", "you feel bad", "you are not happy", "i feel not good"
]
targets = [1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0] #1 긍정, 0 부정
dtype = torch.float
word_list = list(set(" ".join(sentences).split())) # 단어 리스트
word_dict = {w: i for i, w in enumerate(word_list)} # 단어 -> 숫자
number_dict = {i: w for i, w in enumerate(word_list)} # 숫자 -> 단어
n_class = len(word_dict) # 단어 갯수그 다음 batch를 만들어 줄 차례 입니다. make_batch 함수를 보시겠습니다.
일단, 각 문장마다 길이가 조금씩 다르기 때문에, 문장이 끝이 났다면, 0을 입력하여, RNN 모델에 문장이 끝이 났다는 것을 알립니다. 또한, 우리가 batch 학습을 진행하기 때문에, 각 문장의 길이를 추출 하고, 문장의 길이에 따라 input vector와 output 값을 정렬 합니다.
batch_size = len(sentences)
n_embedding = 4 # 단어 임베딩 사이즈
n_hidden = 10 # 은닉층 사이즈
max_length = 4 # 문장 단어 최대 갯수
def make_batch(sentences, targets): # 데이터 전처리
input_batch = []
input_length = []
for sen in sentences:
word = sen.split()
input = [word_dict[n] + 1 for n in word] # word_dict에 있는 숫자 + 1
input += [0] * (max_length - len(word)) # 빈 값은 0으로 처리
input_batch.append(input)
input_length.append(len(word))
input_batch = torch.LongTensor(input_batch)
input_length = torch.LongTensor(input_length)
target_batch = torch.LongTensor(targets)
input_length, sorted_idx = input_length.sort(0, descending=True) # 길이 정렬
input_batch = input_batch[sorted_idx] # 길이별로 문장 정렬
target_batch = target_batch[sorted_idx] # target 값도 같이 정렬
print("Input batch:", input_batch)
print("Input length:", input_length)
print("Target batch:", target_batch)
return input_batch, input_length, target_batch
input_batch, input_length, target_batch = make_batch(sentences, targets)Out
Input batch: tensor([[ 5, 3, 6, 10],
[ 7, 2, 6, 9],
[ 7, 4, 6, 1],
[ 5, 2, 6, 8],
[ 5, 3, 1, 0],
[ 7, 4, 1, 0],
[ 7, 2, 8, 0],
[ 5, 3, 10, 0],
[ 7, 4, 10, 0],
[ 7, 2, 9, 0],
[ 2, 8, 0, 0],
[ 2, 9, 0, 0]])
Input length: tensor([4, 4, 4, 4, 3, 3, 3, 3, 3, 3, 2, 2])
Target batch: tensor([1, 1, 0, 0, 1, 1, 1, 0, 0, 0, 1, 0])이제 모델을 만들 차례 입니다. 일단 nn.Embedding을 통해서, Word2Vec을 실시 합니다. 단어를 하나의 벡터로 만든다는 뜻입니다. (클래스 갯수, 임베딩 차원 갯수, padding 값) 이 파라미터로 들어 갑니다. Word2Vec에 대한 자세한 내용은 여기로...
그 다음 nn.LSTM을 통해서, LSTM Layer를 생성 합니다. 사용 법은 다음과 같습니다.
Parameters
input_size:Input의 사이즈에 해당 하는 수를 입력하면 됩니다.hidden_size: 은닉층의 사이즈에 해당 하는 수를 입력하면 됩니다.num_layers:RNN의 은닉층 레이어 갯수를 나타냅니다. 기본 값은 1입니다.bias: 바이어스 값 활성화 여부를 선택합니다. 기본 값은True입니다.batch_first:True일 시,Output값의 사이즈는 (batch, seq, feature) 가 됩니다. 기본 값은False입니다.dropout: 드롭아웃 비율을 설정 합니다. 기본 값은 0입니다.bidirectional:True일 시, 양방향 RNN이 됩니다. 기본 값은False입니다.proj_size: output vector의 길이를 설정 합니다.
Inputs: input, (h_0, c_0) (tuple 형태)
input: (seq_len, batch, input_size)h_0: (num_layers * num_directions, batch, hidden_size) 여기서bidirectional이True라면,num_directions는 2,False라면 1이 됩니다.c_0: (num_layers * num_directions, batch, hidden_size) 초기 Cell State 입니다.
만약 (h_0, c_0)이 없다면, 기본 값은 영벡터 입니다.
Outputs: output, (h_n, c_0) (tuple 형태)
output: (seq_len, batch, num_directions * hidden_size) 여기서bidirectional이True라면,num_directions는 2,False라면 1이 됩니다.h_n: (num_layers * num_directions, batch, hidden_size) 여기서bidirectional이True라면,num_directions는 2,False라면 1이 됩니다.c_n: (num_layers * num_directions, batch, hidden_size) Cell State 입니다.
그 다음, nn.Linear를 사용 하여 5차원에서 2차원(분류 하고 싶은 갯수)으로 만드는 데, 여기서 새로운 함수가 나타 납니다. 바로 pack_padded_sequence, pad_packed_sequence 입니다.
이는 RNN 모델에 padding 까지만 학습 할 수 있도록 PackedSequence 객체를 생성 합니다. pack_padded_sequence에는 (input tensor, lengths) 가 들어가며, 옵션으로 batch_first를 넣을 수 있습니다. pad_packed_sequence 에는 PackedSequence 객체가 파라미터로 들어가며, 다시 Tensor로 원상 복구 하는 역할을 합니다.
그 다음 원상 복구 된 Output Tensor의 마지막 Output Vector만 뽑을 수 있도록, output = output[range(output.shape[0]), lengths - 1, :] 으로 값을 추출 합니다.
class TextLSTM(nn.Module):
def __init__(self):
super(TextLSTM, self).__init__()
self.embed = nn.Embedding(n_class + 1, n_embedding, padding_idx=0) # 단어 임베딩
self.lstm = nn.LSTM(input_size=n_embedding, # input vector의 size
hidden_size=n_hidden, # hidden layer의 size
proj_size=5) # output vector의 size
self.linear = nn.Linear(5, 2)
def forward(self, X, lengths):
embeded = self.embed(X)
input_batch = pack_padded_sequence(embeded, lengths.tolist(), batch_first=True)
input_batch, hidden = self.lstm(input_batch)
output, output_length = pad_packed_sequence(input_batch, batch_first=True)
output = output[range(output.shape[0]), lengths - 1, :] # index slicing으로 값 추출
output = self.linear(output)
return output이렇게 output이 나오도록 설계를 완료 했다면 학습을 진행 할 차례입니다. nn.CrossEntropyLoss()를 이용하여 학습을 진행 합니다. 그 다음 마지막에 학습 데이터에 없는 문장 (단, 학습 데이터에 있는 단어로만 이루어 져야함.)을 이용하여, 결과 값을 출력 해 봅니다.
model = TextLSTM()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
for epoch in range(1000):
output = model(input_batch, input_length)
loss = criterion(output, target_batch)
if (epoch + 1) % 100 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
model.eval()
test_string = "i am not bad"
test_input, test_length, test_target = make_batch([test_string], [1])
predict = model(test_input, test_length).data.max(1, keepdim=True)[1][0][0]
print(test_string, '->', "positive" if predict == 1 else "negative")Out
Epoch: 0100 cost = 0.662862
Epoch: 0200 cost = 0.402148
Epoch: 0300 cost = 0.013209
Epoch: 0400 cost = 0.002958
Epoch: 0500 cost = 0.001429
Epoch: 0600 cost = 0.000866
Epoch: 0700 cost = 0.000588
Epoch: 0800 cost = 0.000427
Epoch: 0900 cost = 0.000325
Epoch: 1000 cost = 0.000256
Input batch: tensor([[5, 3, 6, 9]])
Input length: tensor([4])
Target batch: tensor([1])
i am not bad -> positive마치며
이렇게 오늘 RNN에 대해서 배워 보았습니다. 오늘은 감정 분석에 대해서만 실습을 진행 했지만, 자동 완성, 필기체 인식, 사진의 텍스트 화 등등, RNN은 많은 곳에서 이용 될 수 있습니다. 또한, 오늘은 LSTM만 이야기 했지만, LSTM의 연산 복잡도를 보완 한, **GRU (Gated Recurrent Units)**라는 메커니즘도 있습니다. 참고 하시기를 바랍니다!