Archive된 사유는 다음 중 하나에 해당 됩니다.
- 작성 된지 너무 오랜 시간이 경과 하여, API가 변경 되었을 가능성이 높은 경우
- 주인장의 Data Engineering으로의 변경으로 질문의 답변이 어려워진 경우
- 글의 퀄리티가 좋지 않아 글을 다시 작성 할 필요가 있을 경우
Deep Neural Network
안녕하세요? 오늘은 DNN, Deep Neural Network에 대해서 알아 보도록 하겠습니다.
여태까지 우리는 간단한 선형 모델에 대해서만 학습을 진행 하였습니다. (혹은 ) 와 같이, 선형 연산을 통해서, 데이터에 대해서 예측하고, 분류 해 보는 실습을 진행 하였습니다. 하지만, 이러한 선형적인 모델이 비선형적인 문제를 해결 하려면 어떻게 해야 할까요?
일단 간단한 예제를 생각 해 보겠습니다. XOR 문제를 예시로 들겠습니다. 우리가 과연 XOR 문제를 머신 러닝 파트에서 배웠던 것 처럼, 선형 분리가 가능 할 까요?
답은 '가능하지 않다' 입니다. 우리가 데이터를 이렇게 묶으면, 하나의 x값에 대해, 두 가지 y값이 나오게 되므로 선형 함수로는 데이터를 분류 하는 것은 불가능 해 보입니다. 이는 퍼셉트론(선형 분류기)의 한계를 설명 할 때 등장하는 XOR(exclusive OR) 문제 입니다.
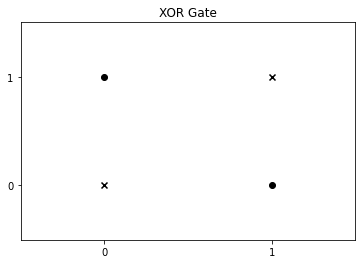
XOR Gate
우리는 이 문제를 해결하기 위해서 어떻게 하면 좋을까요? 방법은, 층을 쌓는 것 입니다. 보이시는 그래프처럼 두 가지 분류 기준을 만듭니다. 그림으로 직관적으로 보면, 파란색 선 아래, 청록색 선 위에 존재하는 데이터를 추출 하는 방식으로 말이죠.
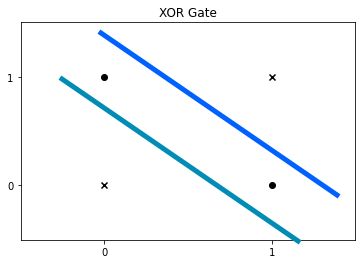
XOR Gate
파란색 선 위, 아래를 각각 0, 1 이라고 가정하고, 이를 x축에 대입 하겠습니다.
그 다음, 청록색 선 위, 아래를 각각 1, 0 이라고 가정하고, 이를 y축에 대입 하겠습니다.
그러면 다음과 같은 그래프가 만들어 지겠네요. 이제 선형 분류가 가능 하게 되었습니다.
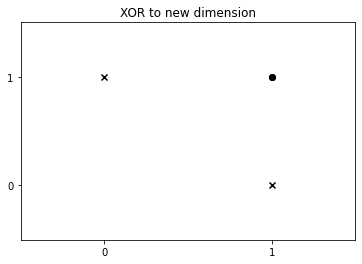
XOR to new dimension
위 과정을 그래프가 아닌 그림으로 나타 내 보겠습니다. 그러면 인공 지능에 관심이 있으셨다면 한번쯤 봤을 그림을 볼 수 있을 것 입니다.
파란색 선은 에 대한 결과, 청록색 선은, 에 대한 결과로 나타 낼 수 있을 것입니다. 그리고 파란색 선, 청록색 선에 대한 각각의 분류 결과를 으로 보내는 것이지요. 그렇게 우리는 비선형적인 정보들도 분류 할 수 있는 것 입니다.
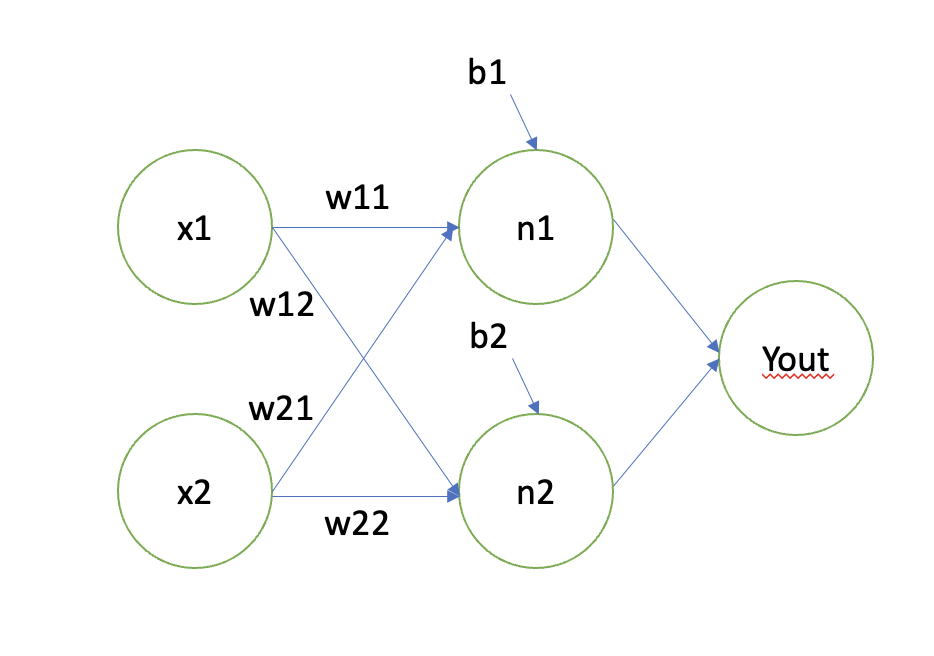
Multi-Layer Perceptron
이렇게 Multi-Layer Perceptron에 대해서 연구가 이루어 진 결과, 우리는 적절한 층과, 적절한 노드 갯수를 이용하여 우리는 선형 모델이 분류 하지 못했던 것들을 분류 할 수 있게 되었습니다. 또한, 역전파 알고리즘에 대한 연구가 이루어져서, 층을 3개 이상 쌓는 Deep Nerual Network의 부흥기가 시작 되었습니다. 자, 이제 우리는 이를 통해, 새로운 것들을 만들어 보고자 합니다.
우리가 오늘 해 볼 것은, DNN을 이용한 Fashion MNIST Dataset 분류 입니다. 여기서 말하는 Fashion MNIST는 입력이 28x28 크기의 행렬로 이루어져 있고 출력은 10개의 분류로 나타 냅니다. 열 개의 분류는 다음과 같습니다. (T-shirt/top, Trouser, Pullover, Dress, Coat, Sandal, Shirt, Sneaker, Bag, Ankle boot)
데이터의 크기는, 6만 개의 학습용 이미지, 만개의 테스트용 이미지로 구성 되어 있습니다.
일단 DNN을 구현 해 보기 전에, Pytorch에 대한 기본 사용법에 대해 다루는 내용들을 보고 오는 것을 추천 드립니다.
Fashion MNIST
일단, Module 부터 먼저 Import 해 보겠습니다. pytorch와 torchvision에 대한 데이터를 가져 옵니다.
# 여러분의 정신 건강을 위해, 그냥 프로젝트 옮길 때마다 복붙 해서 쓰는 것을 추천 드립니다.
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import Dataset
from torchvision.datasets import FashionMNIST
from torchvision import transforms
from torch.utils.data import DataLoader
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt첫 번째로, 데이터를 불러 오기 전, 데이터를 전처리 하기 위한 파이프 라인을 구성 해 보겠습니다. 아래 코드는 Input Data를 Tensor로 만들고, 이를 Z-Score Normalization을 하는 모습입니다. transforms.Compose를 이용하여 파이프라인을 구성하고, transforms.ToTensor()를 통해 Tensor로의 변환, transforms.Normalize를 통해 Z-Score Normalization을 실시 합니다.
RANDOM_SEED = 123
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
custom_train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
custom_test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])두 번째로는 만들어진 파이프라인에, Fashion MNIST 데이터를 넣어 전처리를 해 보겠습니다. 이는 Dataset을 불러 올 때 transform 파라미터에 값을 넣어 줌으로써 가능 합니다.
DataLoader를 통해 데이터 셋을 미니 배치로 분류하고, 데이터를 섞어 줄 수 있습니다.
BATCH_SIZE = 64
train_dataset = FashionMNIST(".", train=True, download=True, transform=custom_train_transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
test_dataset = FashionMNIST(".", train=False, download=True, transform=custom_test_transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=2)아래 창은 데이터가 잘 다운로드 되었는지 확인 하는 코드입니다.
for batch_idx, (x, y) in enumerate(train_loader):
print(' | Batch size:', y.size()[0])
x = x.to(DEVICE)
y = y.to(DEVICE)
print("X shape: ", x.shape)
print("Y shape: ", y.shape)
print('break minibatch for-loop')
breakDeep Neural Network
이제 DNN 모델을 구현 해 볼 시간입니다. 한 번 구현을 해 볼까요?
일단 코드 설명을 드리자면, 가장 먼저 해야할 일은 torch.nn.Module을 상속 받은 class를 만드는 것입니다. 그 다음, 생성자와 forward 함수를 구현 해 주면 됩니다.
먼저 생성자 함수는 super(클래스명, self).__init__()을 통해, 모델 초기화를 해 주어야 하며, 그 다음으로는 torch.nn.Linear로 층을 쌓아 줍니다. torch.nn.Linear는 파라미터로 (input_features, output_features)를 입력 해 줍니다. 입력 차원과 출력 차원을 입력 해 주어야 한다는 것입니다. 층을 입력 해 줄때마다 Input Vector에 대해 (input_features X output_features) 에 대한 행렬 곱을 하는 것과 같습니다.
forward에서는 순전파 연산을 진행 합니다. 파라미터로 데이터를 넣어 가면서 통과 시키면 되지만, 여기서 중간에 ReLU 함수를 넣는 것을 볼 수가 있습니다. 그 이유는, y = ax + b 꼴의 층을 쌓는다고 한들, 층을 하나 더 쌓으면 y = c(ax + b) + d = acx + bc + d 꼴이 되기 때문에, 학습이 되지 않습니다. 그렇기 때문에, 활성화 함수를 사용 합니다. 우리는 현재 가장 대중적으로 사용 되고 있는 ReLU 함수를 사용 해 보았습니다.
ReLU 함수는 0보다 작거나 같으면 0을, 0보다 크면 그대로 값을 반환 합니다.
여기서 적절한 층의 갯수나, 층별 노드 갯수는 어떻게 정해 질까요? 답은 해결 하고자 하는 문제에 따라 다르다 입니다. 검색해 보면 해결하고자 하는 문제에 따라 어떻게 노드와 층을 설계했을지 성능이 잘 나오는지, 벤치마킹 테스트 결과를 나타낸 결과 혹은 논문이 있습니다. 이를 참고하여 모델을 설계 해 주면 됩니다.
https://paperswithcode.com/ 다음 사이트를 참조 하시면, 많은 논문들을 코드로 구현한 것을 볼 수가 있습니다.
일단, 층이 너무 깊으면 학습이 안되고, Overfitting에 빠진 가능성이 높습니다. 노드가 너무 많으면 시간이 너무 오래 걸리고, 이에 따른 성능 향상도 크지 않아요. 고로, 적절한 노드 갯수과, 적절한 층의 갯수를 선택 하는 것이 좋습니다!
class DNN(torch.nn.Module):
def __init__(self, num_features, num_hidden_1, num_hidden_2, num_hidden_3, num_classes):
super(DNN, self).__init__()
self.num_classes = num_classes
self.linear_1 = torch.nn.Linear(num_features, num_hidden_1)
self.linear_2 = torch.nn.Linear(num_hidden_1, num_hidden_2)
self.linear_3 = torch.nn.Linear(num_hidden_2, num_hidden_3)
self.linear_out = torch.nn.Linear(num_hidden_3, num_classes)
def forward(self, x):
### activation 함수 변경 가능
### (optional)레이어간의 연결 추가, 변경 가능
out = self.linear_1(x)
out = torch.relu(out)
out = self.linear_2(out)
out = torch.relu(out)
out = self.linear_3(out)
out = torch.relu(out)
logits = self.linear_out(out)
probas = torch.sigmoid(logits)
return logits, probas
random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
model = DNN(num_features=28*28,
num_hidden_1=1024,
num_hidden_2=128,
num_hidden_3=64,
num_classes=10)
model = model.to(DEVICE)Training
Training 과정에 대한 코드는 주석으로 설명 하겠습니다. 다음 코드를 실행하면 학습이 진행 됩니다. 하지만, 여기 내부에 있는 함수들을 Pytorch Documentation에서 하나하나 공부하여 내부 원리를 파악 하는 것을 추천드립니다.
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # 파라미터 학습을 위한 optimizer, 경사 하강법에 도움을 줌
NUM_EPOCHS = 20
def compute_accuracy_and_loss(model, data_loader, device): # 손실 계산
correct_pred, num_examples = 0, 0
cross_entropy = 0.
for i, (features, targets) in enumerate(data_loader): # 미니 배치 iteration
features = features.view(-1, 28*28).to(device) # view를 통해 [batch_size * 784] 크기로 변경
targets = targets.to(device) # 타겟
logits, probas = model(features) # 모델 결과 반환 (결과, sigmoid 적용한 결과)
cross_entropy += F.cross_entropy(logits, targets).item() # 타겟과 연산 결과의 cost 결과
_, predicted_labels = torch.max(probas, 1) # 예측 결과 반환
num_examples += targets.size(0) # input 개수 반환
correct_pred += (predicted_labels == targets).sum() # 맞은 갯수 반환
return correct_pred.float()/num_examples * 100, cross_entropy/num_examples # 정확도, cost 평균
start_time = time.time() # 시작 시간 계산
train_acc_lst, test_acc_lst = [], [] # 훈련 데이터 정확도, 테스트 데이터 정확도
train_loss_lst, test_loss_lst = [], [] # 훈련 데이터 손실함수, 테스트 데이터 손실함수
for epoch in range(NUM_EPOCHS): # EPOCH 만큼 반복
model.train() # 학습 모드
for batch_idx, (features, targets) in enumerate(train_loader): # 미니 배치 iteration
### PREPARE MINIBATCH
features = features.view(-1, 28*28).to(DEVICE)
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features) # 순전파
cost = F.cross_entropy(logits, targets) # 예측 결과에 대한 cost 계산
optimizer.zero_grad() # 기울기 0 초기화
cost.backward() # 역전파
### UPDATE MODEL PARAMETERS
optimizer.step() # 모델 파라미터 업데이트
### LOGGING
if not batch_idx % 40:
print (f'Epoch: {epoch+1:03d}/{NUM_EPOCHS:03d} | '
f'Batch {batch_idx:03d}/{len(train_loader):03d} |'
f' Cost: {cost:.4f}')
# 매 Epoch마다 evaluation을 진행합니다.
# Epoch마다 Loss를 기록하여 학습과정을 살펴보고 Underfitting, Overfitting 여부를 확인합니다.
model.eval()
with torch.set_grad_enabled(False): # Gradient 계산이 안되도록
train_acc, train_loss = compute_accuracy_and_loss(model, train_loader, device=DEVICE) # train acc, loss 계산
test_acc, test_loss = compute_accuracy_and_loss(model, test_loader, device=DEVICE) # test acc, loss 계산
# list에 train, test의 acc, loss 추가
train_acc_lst.append(train_acc)
test_acc_lst.append(test_acc)
train_loss_lst.append(train_loss)
test_loss_lst.append(test_loss)
# 로깅
print(f'Epoch: {epoch+1:03d}/{NUM_EPOCHS:03d} Train Acc.: {train_acc:.2f}%'
f' | Test Acc.: {test_acc:.2f}%')
# 1 epoch 학습 소요시간
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
# 총 학습 소요시간
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')Epoch: 001/020 | Batch 000/937 | Cost: 2.3114
Epoch: 001/020 | Batch 040/937 | Cost: 2.2735
Epoch: 001/020 | Batch 080/937 | Cost: 2.2252
...
Epoch: 020/020 | Batch 800/937 | Cost: 0.3877
Epoch: 020/020 | Batch 840/937 | Cost: 0.1904
Epoch: 020/020 | Batch 880/937 | Cost: 0.1722
Epoch: 020/020 | Batch 920/937 | Cost: 0.3173
Epoch: 020/020 Train Acc.: 90.89% | Test Acc.: 87.81%
Time elapsed: 4.73 min
Total Training Time: 4.73 minEvaluation
테스트 데이터와 학습 데이터의 Loss변화를 확인합니다.
plt.plot(range(1, NUM_EPOCHS+1), train_loss_lst, label='Training loss')
plt.plot(range(1, NUM_EPOCHS+1), test_loss_lst, label='Test loss')
plt.legend(loc='upper right')
plt.ylabel('Cross entropy')
plt.xlabel('Epoch')
plt.show()
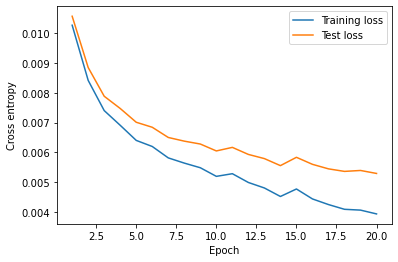
Loss Graph
plt.plot(range(1, NUM_EPOCHS+1), train_acc_lst, label='Training accuracy')
plt.plot(range(1, NUM_EPOCHS+1), test_acc_lst, label='Test accuracy')
plt.legend(loc='upper left')
plt.ylabel('Accuracy')
plt.xlabel('Epoch')
plt.show()
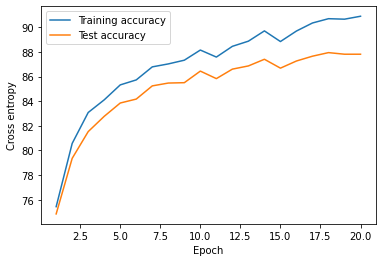
Accuracy Graph
model.eval()
with torch.set_grad_enabled(False): # save memory during inference
test_acc, test_loss = compute_accuracy_and_loss(model, test_loader, DEVICE)
print(f'Test accuracy: {test_acc:.2f}%')Test accuracy: 87.81%마치며
이렇게 간단하게(?) DNN 모델을 개발하여, 학습 해 보았습니다. 생각보다 사진 정보에 대한 학습 성능이 좋지 않았습니다. 왜 일까요? 답은, 우리가 이미지 부분부분에 대한 정보가 아닌 이미지를 쫙 펴서, 픽셀 정보로만 학습을 했기 때문입니다. 그렇기 때문에, 우리는 이미지의 국소적인 정보를 추출 하는 것이 중요합니다. 세로, 가로 정보 같은 것들 말이죠. 다음 시간에는 이에 대한 단점을 해결한 CNN에 대해서 배워 보겠습니다.