Archive된 사유는 다음 중 하나에 해당 됩니다.
- 작성 된지 너무 오랜 시간이 경과 하여, API가 변경 되었을 가능성이 높은 경우
- 주인장의 Data Engineering으로의 변경으로 질문의 답변이 어려워진 경우
- 글의 퀄리티가 좋지 않아 글을 다시 작성 할 필요가 있을 경우
Generative Adversarial Network
안녕하세요? 오늘은 GAN, Generative Adversarial Network에 대해서 알아 보도록 하겠습니다.
Generative Adversarial Network을 직역하면 생성적 적대 네트워크 입니다. 말이 좀 어려워서 이게 뭘 이야기 하는지 직관적으로 파악할 수 힘든데, 쉽게 이야기 하면 경찰과 도둑을 생각 하시면 편합니다.
특정 상황을 빗대어 비유 해 보겠습니다.
어떤 위조 지폐를 만들어 내는 범죄자가 있고, 이를 잡으려는 경찰관이 있다고 가정 하겠습니다. 처음에는 범죄자가 위조 지폐를 찍어 내는 데 미숙한 나머지 쉽게 위조 지폐를 식별 할 수 있었습니다. 하지만, 나중에는 위조 지폐를 찍어내는 기술이 발달 하여, 실제 지폐와 유사한 지폐를 만들어 낼 수 있게 되었고, 경찰관은 이를 알아 볼 수 없었습니다. 하지만, 여기서 끝났을까요? 또, 경찰관 쪽의 기술이 발달 하여, 그렇게 어렵게 만들어 진 위조 지폐를 검출하는 기술이 만들어 지게 됩니다.
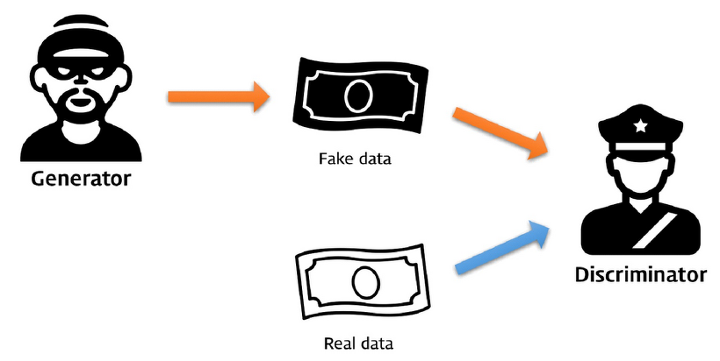
출처: https://files.slack.com/files-pri/T25783BPY-F9SHTP6F9/picture2.png?pub_secret=6821873e68
위와 같은 상황이 반복되게 된다면 어떻게 될까요? 그러면 나중에는 경찰관, 범죄자 모두 기술 경쟁으로 인해 서로 엄청난 기술이 만들어 지게 됩니다. GAN은 이러한 원리를 이용하여 학습 합니다.
우리는 GAN에서 두 가지 모델을 이용하여 학습 합니다. 바로 Generator와 Discriminator입니다. Generator는 위의 사례에서 이야기 한 범죄자 역할을 합니다. 가짜 정보를 만들어 내는 역할을 하죠. Discriminator는 위의 사례에서 경찰관 역할을 담당 합니다. 가짜 정보를 검출 하는 역할을 합니다.
손실 함수는 다음과 같습니다.
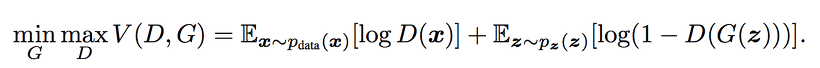
손실 함수
여기서 는 Discriminator, 는 Generator를 의미 합니다. 는 Discriminator가 실제 샘플 를 보고 판별하는 확률 예측값이고, 는 Generator가 만들어 낸 값입니다. 는 Discriminator가 가짜 샘플 를 보고 판별하는 확률 예측값입니다. 우리는 이 손실 함수를 다음과 같이 해석 할 수 있습니다.
일단, Discriminator 입장 에서는, 가짜 데이터를 잘 찾을 수록, 더 좋은 Discriminator 이라고 볼 수 있습니다. 그러면 Discriminator 입장 에서는 위에 있는 손실 함수의 값을 높여야 하는 것이지요.
역으로 Generator 입장에서는, 가짜 데이터로 더 잘 속일 수록, 더 좋은 Generator라고 볼 수 있습니다. 그러면 Generator는 위에 있는 손실 함수의 값을 낮춰야 하는 것이지요.
이렇게 자강두천의 싸움이 지속 되면, Discriminator는 지도 학습의 방식으로, Generator는 비지도 학습의 방식으로 서로 더 강력한 모델을 만들어 나갈 수 있습니다.

Discriminator, Generator 싸움 수준 실화냐? 가슴이 웅장해진다...
Generator는 어떤 식으로 데이터를 만들어 낼 까요? 입력 값에 정규 분포 값으로 초기화 된 벡터를 넣음으로 가능합니다. 데이터가 나올 확률은 학습 데이터에서 사용 한 확률 분포와 유사 합니다. GAN의 목표는 Generator에서 만들어 내는 데이터가, 실제 데이터의 확률 분포와 유사하게 만드는 것을 목표로 합니다.
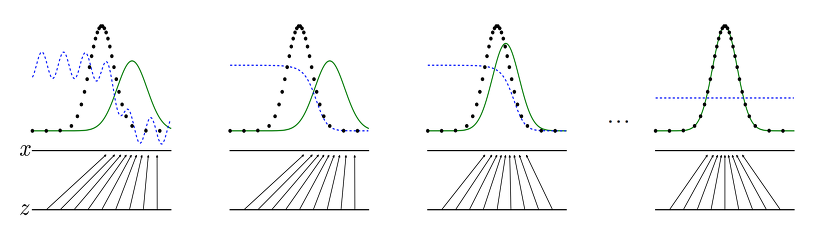
Ian Goodfellow의 논문에 수록된 그림.
여기서 우리가 모델을 학습 시키는 데에 주의 해야 할 점이 있다면, 한 쪽의 성능이 우월하게 되면, Gradient Vanishing 문제로 인하여, 학습이 잘 진행이 되지 않는다는 단점이 있습니다. 그리하여, 우리는 학습 횟수 및 학습률을 잘 조정 해야 합니다.
Code Implementation
다음은 코드 구현을 진행 하여 보겠습니다. 일단 저번 MNIST 실습 때 이용 했던 것처럼, MNIST data를 가져 오도록 하겠습니다.
import numpy as np
import torch
import torch.nn as nn
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torch.autograd import Variable
from torchvision.transforms.functional import to_pil_image
import torch.nn.functional as F
import matplotlib.pyplot as plt
BATCH_SIZE = 64
image_shape = (1, 28, 28) # MNIST 이미지 모양
EPOCH = 200
learning_rate = 0.0002
latent_dim = 100 # 입력 값의 차원
custom_train_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
custom_test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize(mean=(0.5,), std=(0.5,))
])
train_dataset = MNIST(".", train=True, download=True, transform=custom_train_transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
drop_last=True,
num_workers=2)
test_dataset = MNIST(".", train=False, download=True, transform=custom_test_transform)
test_loader = DataLoader(dataset=test_dataset,
batch_size=BATCH_SIZE,
shuffle=False,
num_workers=2)
img, label = train_dataset[0]
plt.title("label: " + str(label))
plt.imshow(to_pil_image(img), cmap='gray')
plt.show()
데이터를 잘 불러 온 모습.
Model
다음은 모델을 설계 할 시간입니다. 우리는 이를 학습 시킬 때, 두 가지 모델을 학습 시키기 때문에, 학습 시 두 가지 모델을 설계 하여야 합니다.
Generator
먼저 Generator 구현에 대해서 먼저 설명 드리겠습니다. 일단, 우리는 임의의 벡터를 입력 받아, 여러 개의 Affine 계층을 거친 후, 이미지와 비슷 한 사이즈로 만들어야 합니다.
class Generator(nn.Module):
def __init__(self, input_noise):
super(Generator, self).__init__()
def block(in_feat, out_feat, normalize=True):
layers = [nn.Linear(in_feat, out_feat)]
if normalize:
layers.append(nn.BatchNorm1d(out_feat, 0.8))
layers.append(nn.LeakyReLU(0.2, inplace=True))
return layers
self.model = nn.Sequential(
*block(latent_dim, 256, normalize=False),
*block(256, 512),
*block(512, 1024),
nn.Linear(1024, int(np.prod(image_shape))),
nn.Tanh()
)
def forward(self, z):
img = self.model(z)
img = img.view(img.size(0), *image_shape)
return img그 다음, Discriminator에서는, 이를 검출하기 위한 코드를 사용 합니다. 입력으로 이미지가 들어오면, 이를 진짜인지 아닌지를 검출 합니다.
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(int(np.prod(image_shape)), 1024),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(1024, 512),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(512, 256),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.3),
nn.Linear(256, 1),
nn.Sigmoid()
)
def forward(self, img):
img_flat = img.view(img.size(0), -1)
validity = self.model(img_flat)
return validityTraining
다음은 학습을 실시 할 시간 입니다. Generator는 가짜 데이터가 Discriminator에 통과 된 결과값을 보고, 내가 제대로 속였는지, 안 속였는지에 대해서 손실 함수를 계산 합니다. Discriminator는 Generator에서 나온 가짜 데이터를 제대로 검출 했는지 안 했는지, 그 다음 실제 데이터를 진짜라고 판별 했는지, 안 했는지에 대해서 손실 함수를 계산 합니다.
adversarial_loss = torch.nn.BCELoss() # Binary Cross Entropy
generator = Generator(latent_dim) # Generator
discriminator = Discriminator() # Discriminator
# Optimizer
optimizer_G = torch.optim.Adam(generator.parameters(), lr=learning_rate)
optimizer_D = torch.optim.Adam(discriminator.parameters(), lr=learning_rate)
batch_count = 0
Tensor = torch.FloatTensor
for epoch in range(EPOCH):
for i, (imgs, _) in enumerate(train_loader):
valid = Variable(Tensor(imgs.size(0), 1).fill_(1.0), requires_grad=False) # 배치 사이즈로 Target: True 삽입
fake = Variable(Tensor(imgs.size(0), 1).fill_(0.0), requires_grad=False) # 배치 사이즈로 Target: False 삽입
# Configure input
real_imgs = Variable(imgs.type(Tensor))
# Train Generator
optimizer_G.zero_grad()
z = Variable(Tensor(np.random.normal(0, 1, (imgs.shape[0], latent_dim))))
gen_imgs = generator(z) # 이미지 생성
g_loss = adversarial_loss(discriminator(gen_imgs), valid) # Generator Loss 계산, 속이면 속일 수록 낮아짐
g_loss.backward()
optimizer_G.step()
# Train Discriminator
optimizer_D.zero_grad()
real_loss = adversarial_loss(discriminator(real_imgs), valid) # Discriminator Loss 계산, 진짜 레이블에 대해서
fake_loss = adversarial_loss(discriminator(gen_imgs.detach()), fake) # Discriminator Loss 계산, 가짜 레이블에 대해서
d_loss = (real_loss + fake_loss)
d_loss.backward()
optimizer_D.step()
# Epoch 마다 이미지 생성 시각화
print(
"[Epoch %d/%d] [D loss: %f] [G loss: %f]"
% (epoch, EPOCH, d_loss.item(), g_loss.item())
)
print("Epoch:", epoch)
fig, axes = plt.subplots(1, 4)
z = Variable(Tensor(np.random.normal(0, 1, (4, latent_dim))))
gen_imgs = generator(z)
for i in range(4):
axes[i].imshow(gen_imgs.detach().numpy()[i][0])
plt.show()하지만, 데이터의 결과가 영 시원 찮은 것을 볼 수 있습니다. 일단, 데이터를 생성 하고, 데이터를 판별 하는데에 일반 DNN을 적용 했기 때문 입니다. 데이터를 생성하고, 데이터를 판별 할때 CNN을 사용 한 것을 DCGAN이라고 합니다. 아마, 그렇게 하면 성능이 더 잘 나올 것이라고 예상 됩니다.

결과
마치며
이번 시간에는 GAN에 대해서 배워 보았습니다. 오늘, 이렇게 마지막 시간을 갖게 되었습니다. 사실, 찍먹 시리즈에서 제가 다룬건 겉핥기 수준에 불과 합니다. 실제 우리가 이를 이용하여 어플리케이션을 만들 때는 많은 수학적인 이해, 통찰력, 경험이 필요 합니다. 이를 통해 데이터 사이언스에 관심이 생기셨다면, 논문과, 다른 블로그나 영상을 통해 심층 적으로 공부 하시는 걸 추천 드립니다! (개인적으로 Andrew ng씨의 강의를 추천 드립니다.) 모두 부족한 제 포스트를 따라 공부해 주심에 감사 드립니다.