Archive된 사유는 다음 중 하나에 해당 됩니다.
- 작성 된지 너무 오랜 시간이 경과 하여, API가 변경 되었을 가능성이 높은 경우
- 주인장의 Data Engineering으로의 변경으로 질문의 답변이 어려워진 경우
- 글의 퀄리티가 좋지 않아 글을 다시 작성 할 필요가 있을 경우
Convolutional Neural Network
안녕하세요? 오늘은 CNN, Convolutional Neural Network에 대해서 알아 보도록 하겠습니다.
저번 시간에는 DNN에 대해서 다뤄 보았습니다. 우리가 층을 쌓음으로써, 선형적인 문제 만을 해결하는 것이 아닌, 비선형적인 문제 또한 해결 할 수 있었습니다. 하지만, 우리에게는 문제가 있었습니다. 바로, 이미지의 국소적인 정보를 추출 할 수 없다는 것입니다.
다음 예제를 보겠습니다. 우리가 DNN 예제에서는 우리가 어떻게 28x28의 행렬을 학습 했는지 기억 나시나요? 다음 그림과 같은 방식으로 28x28의 크기의 행렬을 786차원의 벡터로 바꿨습니다. 그렇게 되면, 우리는 이미지의 가로, 세로, 대각의 국소적인 정보를 추출 할 수 없게 됩니다.
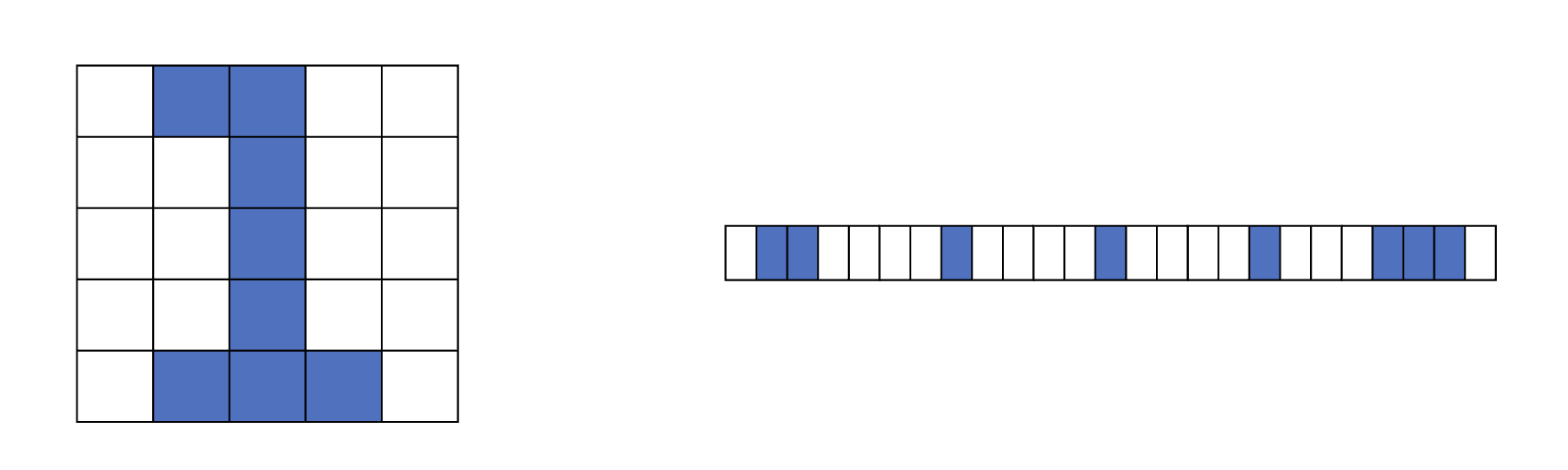
이렇게 벡터로 찢어 버리다 보니...
우리는 이를 어떻게 해결 할 수 있을까요? 국소적인 정보들을 추출 하기 위해서 우리는 **Filter(필터)**를 이용 합니다. 이는 문서에 따라 **kernel(커널)**이라고도 불립니다. 필터를 Stride(스트라이드) 만큼 옮겨 가며, 스칼라 곱을 하여, 정보를 추출 합니다. 이렇게 여러 개의 필터를 옮겨가며, 가로 정보, 세로 정보를 추출 합니다.
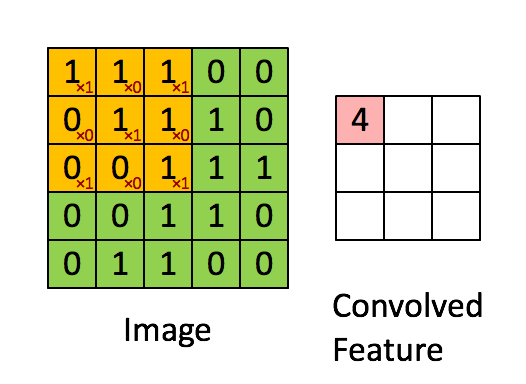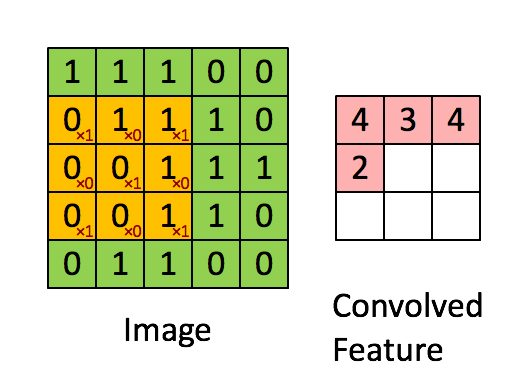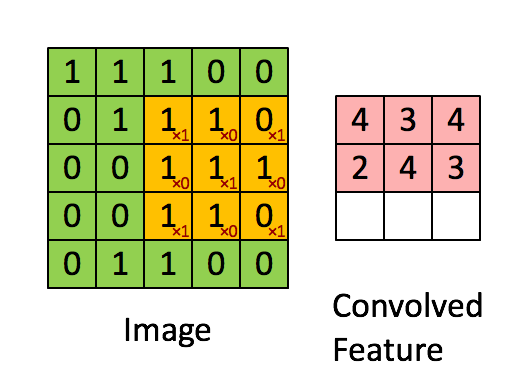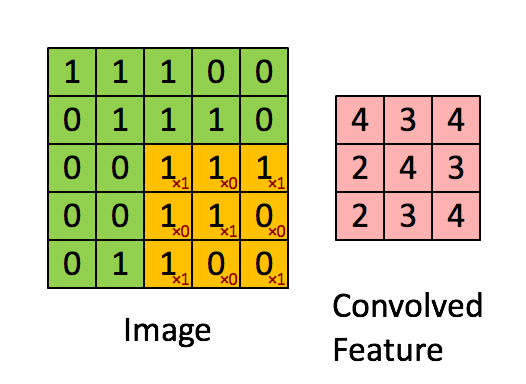
출처: http://deeplearning.stanford.edu/wiki/index.php/Feature_extraction_using_convolution
필터를 옮겨 가며 스칼라 곱을 실시 합니다. 필터는 주어진 값에 따라, 다음과 같이 Edge에 대한 정보, 윤곽에 대한 정보 등을 추출 하여, 학습을 하는 데에 정보를 제공 합니다.

출처: 위키피디아
이렇게 위와 같이 연산 하게 되면, width와 height이 감소합니다. 만약, width와 height을 유지 하고 싶을 때는 어떻게 하면 될까요? 그럴 때는 Zero Padding을 추가 해 주면 됩니다. Zero Padding을 하게 되면 가장 자리에 있는 정보를 추출 하는데 도움이 되기도 합니다.
또 다른 Convolution으로 Dilated Convolution가 있습니다. 확장된 Convolution 이라고도 불립니다. 이는 주로 실시간으로 데이터를 처리할 경우 동일 계산 양으로 많은 데이터를 처리 하고자 할 때 사용됩니다.
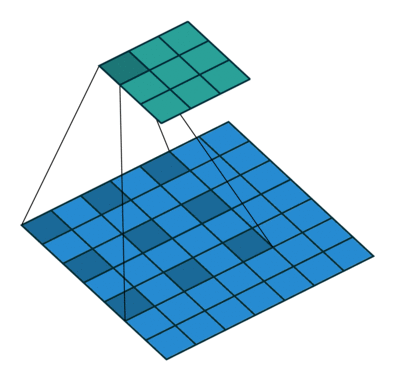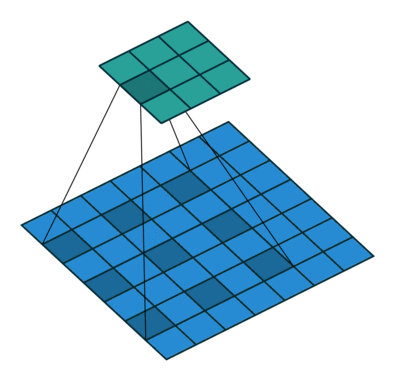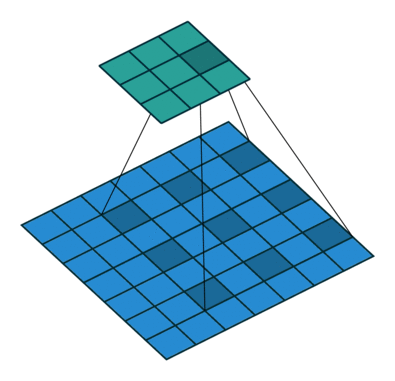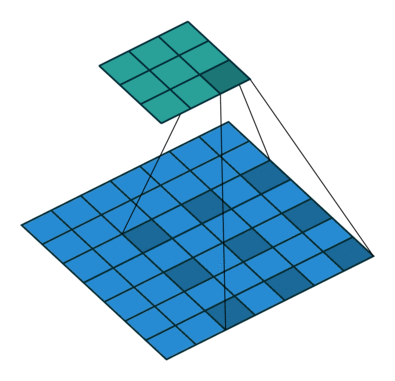
Dilated Convolution, dliation rate는 2
기존 DNN에서는 다음과 같은 구조로 학습을 진행 하였습니다. Affine 계층은 선형 연산 계층이라고 생각 하시면 됩니다.
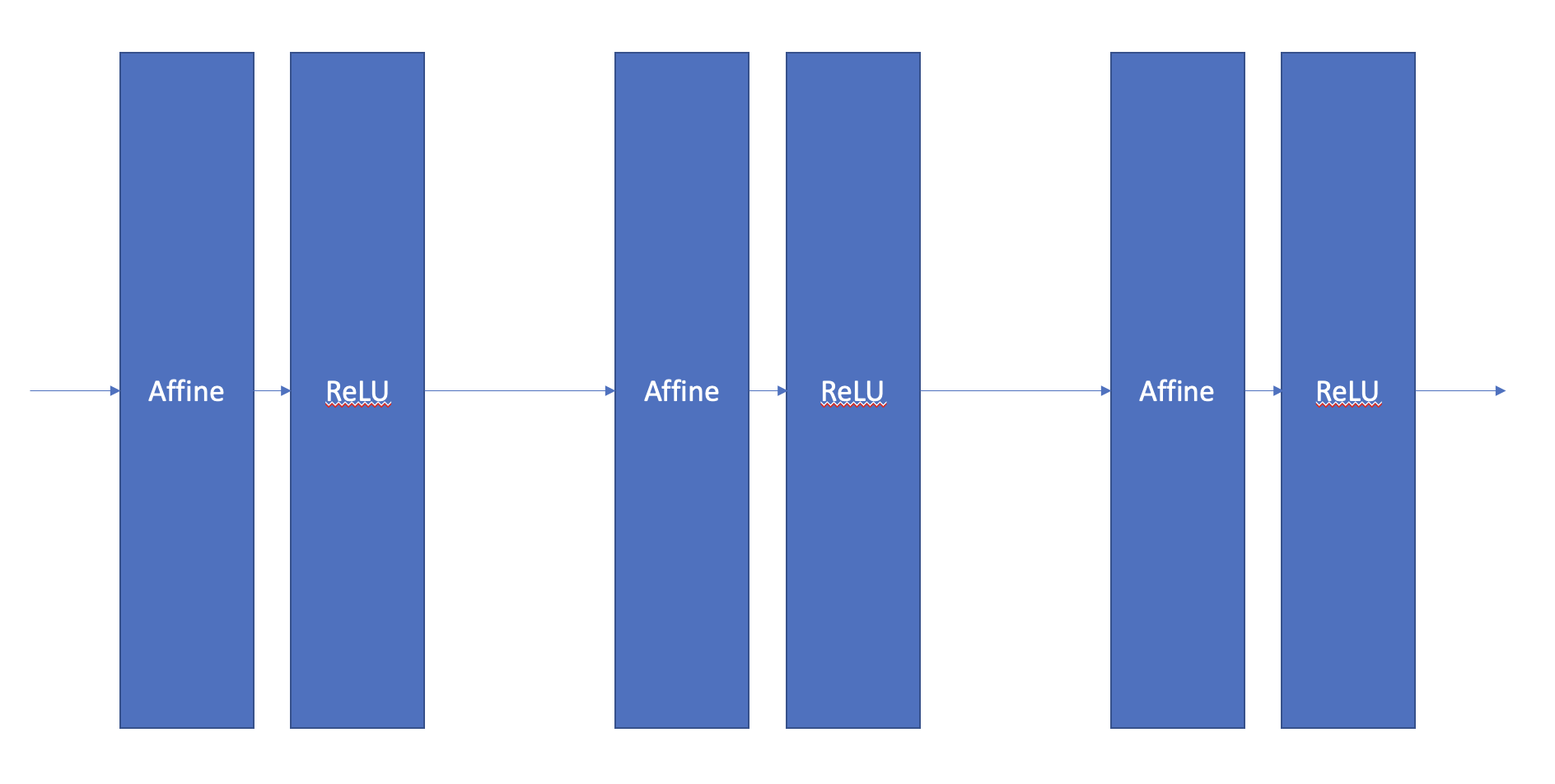
기존 DNN의 학습
하지만 CNN은 약간 다릅니다. 위에서 언급한 방식을 사용 하는 Conv 계층과, Pooling 계층이 추가 되고, 마지막에 Affine 계층을 추가하여 연산하는 모습입니다.
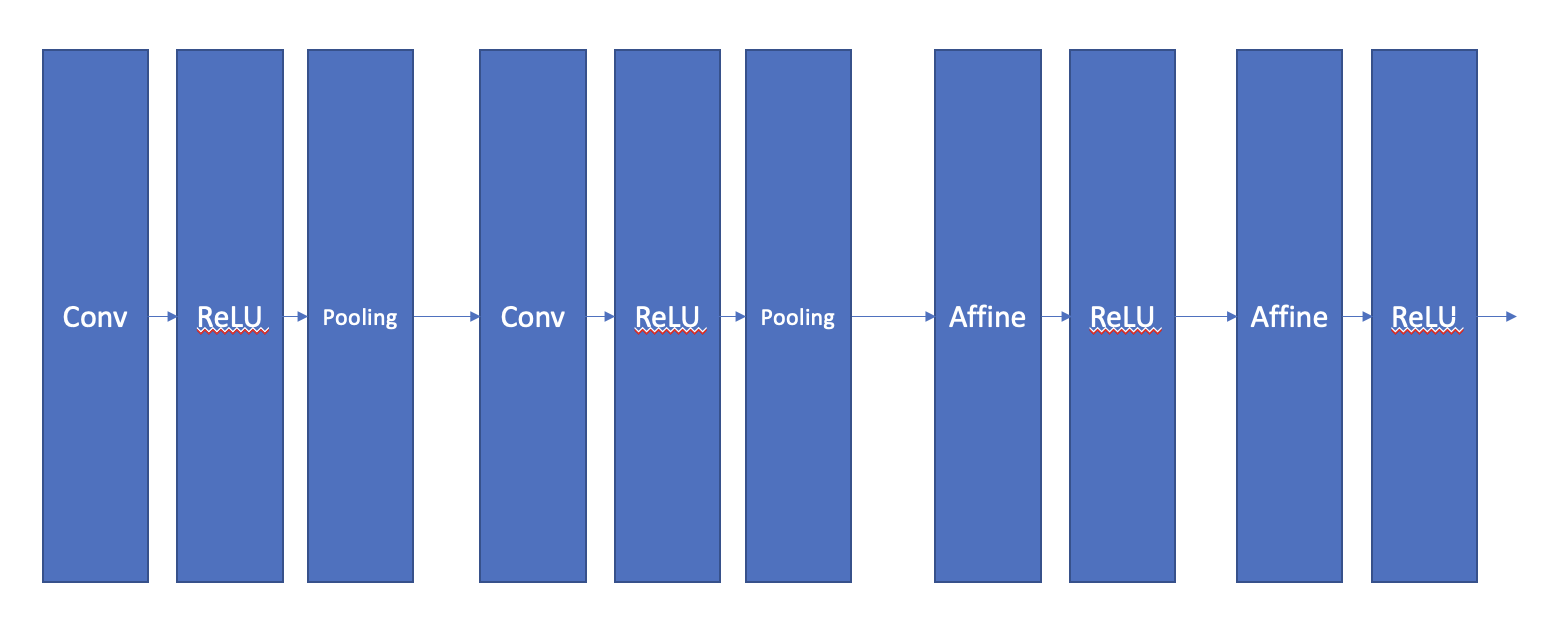
CNN의 학습
Conv 계층
일단 Conv 계층은 위에서 언급한 테크닉을 이용하여, 입력 행렬의 지역적인 정보를 추출 합니다. 윤곽은 어떻게 되는지, 가로, 세로 정보는 어떤 값을 갖고 있는지를 추출합니다.
Conv 계층의 연산은 어떻게 진행 될까요? 만약 내가 개의 채널에 대해, 개의 채널로 변환 시키려고 할때 내부에서는 다음과 같은 연산이 일어납니다. 은 Output Tensor의 i번째 채널이고, 는 Input Tensort의 j번째 채널 입니다.
이런식으로 각 채널의 input값에 해당 output 채널의 weight 값을 스칼라 곱해 줍니다. 여기서 Conv 계층을 지난 후, Input Tensor의 모양은 어떻게 변할까요?
Input Tensor의 모양과 Output Tensor의 모양은 다음과 같습니다.
Input Tensor
- : batch의 크기
- :
in_channels에 넣은 값과 일치하여야 함. - : 2D Input Tensor의 높이
- : 2D Input Tensor의 너비
Output Tensor
- : batch의 크기
- :
out_channels에 넣은 값과 일치 함.
Pooling 계층
Pooling 계층이 의미하는 것은 특징을 뽑아 내는 것이라고 정리 할 수 있습니다. 애초에 CNN은 이미지 속에서 지역적인 특징을 뽑아내기 위해 실시한 것입니다. 그렇기 때문에 Pooling을 통해서 input size를 줄이고, Overfitting을 줄이는 데에 목적이 있다고 할 수 있겠습니다.
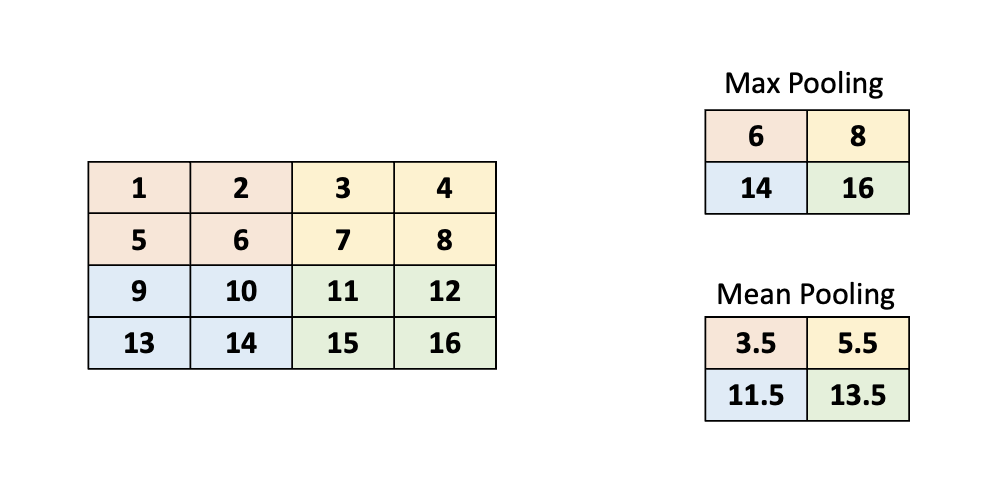
Pooling의 종류
Pooling의 종류에는 2가지가 있는데, 첫 번째는 Max Pooling 입니다. 특정 부분의 값중 가장 큰 값을 추출 합니다. 두 번째는 Mean Pooling 입니다. 특정 부분의 값들의 평균을 출력합니다. 특징을 추출 하기 위해서 보통의 경우에는 Max Pooling을 많이 이용합니다.
저번에 썼던 코드를 개선 해 보자!
저번에 썼던 코드를 그대로 사용합니다. 사실, 우리는 모델과 학습 과정만 수정 할 거에요.
모델 부분은 다음과 같이 수정 합니다.
저번 DNN 모델에서 사용한 테크닉과 같습니다. 사용한 레이어만 다를 뿐이죠, nn.Conv2d는 Convolution Layer를 구현 하는데 사용 하며, (input_channel, output_channel, filter_size)를 입력으로 받습니다. padding='same'을 적용 해 주면 너비와 높이를 유지 해 줍니다.
nn.MaxPool2d는 Pooling Layer를 구현 하는데 사용하며, (filter_size, stride)를 입력으로 받습니다.
여기 세 가지 특이점이 있습니다. 첫 번째는 nn.Sequential을 이용해서, 여러 개의 레이어를 한꺼번에 통과 시킬 수 있습니다. nn.Sequential에 원하는 레이어를 한꺼번에 넣어서, 이렇게 만들어진 파이프라인을 한 줄의 코드를 이용하여 통과 시킬 수 있습니다.
두 번째는, MaxPool2d Layer를 통과 하더라도, Tensor는 배치 사이즈를 포함한, 4차원의 shape를 유지 하기 때문에 (64, 64, 6, 6), 이를 2차원 (64, 64 * 6 * 6) 으로 펴주는 작업이 필요 합니다. 그리하여 out = out.view(-1, 64 * 6 * 6)를 통해 데이터를 펴 주는 모습 입니다.
세 번째는, 중간중간에 들어간 nn.BatchNorm2d와 nn.BatchNorm1d을 볼 수 있습니다. 이는 배치 데이터를 정규화 하여, 학습 과정을 안정화 합니다. 이를 통해 Gradient Vanishing / Exploding 문제를 해결 할 수 있습니다. nn.BatchNorm2d의 파라미터로는 채널 갯수가 들어가고, nn.BatchNorm1d의 파라미터로는 차원 갯수가 들어 갑니다.
class CNN(torch.nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.convs = nn.Sequential(
nn.Conv2d(1, 16, kernel_size=(3, 3)),
nn.ReLU(),
nn.BatchNorm2d(16),
nn.Conv2d(16, 32, kernel_size=(3, 3), stride=2),
nn.ReLU(),
nn.BatchNorm2d(32),
nn.Conv2d(32, 64, kernel_size=(3, 3), stride=2)
)
self.layers = nn.Sequential(
nn.Linear(64 * 5 * 5, 512),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.BatchNorm1d(512),
nn.Linear(512, 256),
nn.Linear(256, 128),
nn.Dropout(p=0.2),
nn.ReLU(),
nn.BatchNorm1d(128),
nn.Linear(128, 64),
nn.Linear(64, 10)
)
def forward(self, x):
out = self.convs(x)
out = out.view(-1, 64 * 5 * 5)
logits = self.layers(out)
probas = torch.sigmoid(logits)
return logits, probas
random.seed(RANDOM_SEED)
torch.manual_seed(RANDOM_SEED)
model = CNN()
model = model.to(DEVICE)또한, 이제 데이터를 펴 줘서 넣어 줄 필요가 없기 때문에, 모델에 데이터를 넣을때, view 함수를 사용 하지 않습니다.
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # SGD 에서, Adam으로 변경!
NUM_EPOCHS = 10 # 변경됨
def compute_accuracy_and_loss(model, data_loader, device):
correct_pred, num_examples = 0, 0
cross_entropy = 0.
for i, (features, targets) in enumerate(data_loader):
features = features.to(device) # 변경됨
targets = targets.to(device)
logits, probas = model(features)
cross_entropy += F.cross_entropy(logits, targets).item()
_, predicted_labels = torch.max(probas, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100, cross_entropy/num_examples
start_time = time.time()
train_acc_lst, test_acc_lst = [], []
train_loss_lst, test_loss_lst = [], []
for epoch in range(NUM_EPOCHS):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
### PREPARE MINIBATCH
features = features.to(DEVICE) # 변경됨
targets = targets.to(DEVICE)
### FORWARD AND BACK PROP
logits, probas = model(features)
cost = F.cross_entropy(logits, targets)
optimizer.zero_grad()
cost.backward()
### UPDATE MODEL PARAMETERS
optimizer.step()
### LOGGING
if not batch_idx % 40:
print (f'Epoch: {epoch+1:03d}/{NUM_EPOCHS:03d} | '
f'Batch {batch_idx:03d}/{len(train_loader):03d} |'
f' Cost: {cost:.4f}')
model.eval()
with torch.set_grad_enabled(False):
train_acc, train_loss = compute_accuracy_and_loss(model, train_loader, device=DEVICE)
test_acc, test_loss = compute_accuracy_and_loss(model, test_loader, device=DEVICE)
train_acc_lst.append(train_acc)
test_acc_lst.append(test_acc)
train_loss_lst.append(train_loss)
test_loss_lst.append(test_loss)
print(f'Epoch: {epoch+1:03d}/{NUM_EPOCHS:03d} Train Acc.: {train_acc:.2f}%'
f' | Test Acc.: {test_acc:.2f}%')
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')결과는 다음과 같습니다. Epoch를 줄였음에도 불구하고, 학습이 더 잘 된 모습을 볼 수 있습니다. (사실, 더 늘리면 Overfitting이 발생합니다.)
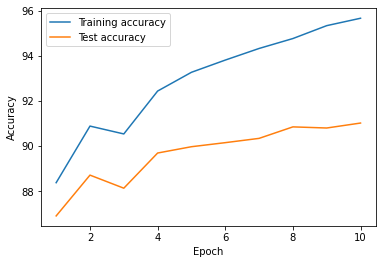
Accuarcy: 91.03%
마치며
오늘은 이미지의 국소 적인 정보를 추출 하는 CNN에 대해서 알아 보았습니다. 다음 시간에는 시계열 데이터를 위한 RNN에 대해서 알아 보도록 하겠습니다.