Archive된 사유는 다음 중 하나에 해당 됩니다.
- 작성 된지 너무 오랜 시간이 경과 하여, API가 변경 되었을 가능성이 높은 경우
- 주인장의 Data Engineering으로의 변경으로 질문의 답변이 어려워진 경우
- 글의 퀄리티가 좋지 않아 글을 다시 작성 할 필요가 있을 경우
Linear Regression, Classification
안녕하세요? Justkode 입니다. 오늘은 선형 회귀와 분류에 대해 이론을 공부 해 보고, 실습을 진행 해 보는 시간을 가져 보도록 하겠습니다.
Before we start
먼저 이번 실습에는 scikit-learn 모듈이 필요합니다. 다음을 통해 설치 해 주세요. (단, numpy, pandas, matplotlib이 설치 되어 있다면 scikit-learn만 설치 하셔도 됩니다.)
pip install numpy
pip install pandas
pip install -U matplotlib
pip install -U scikit-learnLinear Regression
선형 회귀에 대해서 설명 드리겠습니다. 선형 회귀란 한 개 이상의 독립 변수 (Feature)와 종속 변수 y (Target)와의 상관 관계를 선형적으로 모델링 하여, 연속적인 결과 값을 예측하는 데에 사용 됩니다. 예시로는 부동산 가격 예측, 키를 통한 몸무게의 예측 등등이 있겠습니다.
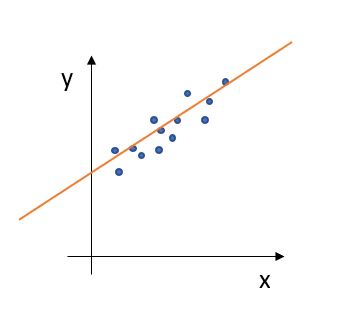
선형 회귀의 예시
위에 있는 예시는, 샘플에 있는 x값 (Feature)을 바탕으로 y값 (Target)을 예측 한다고 볼 수 있습니다. 선형적으로 말이죠. 해당 모델을 식으로 나타내면 다음과 같습니다.
여기서 는 Target (스칼라), 는 Feature 벡터, 는 Weight, 즉, 가중치 입니다. (벡터)
Feature를 좀 분해해서 보면, 다음과 같겠네요.
우리는, 가중치 를 갱신하여, 실제 값과 예측 값의 오차가 적은 모델을 만들어 나갈 것 입니다.
Cost Function
저번 시간에 비용 함수에 대해서 이야기 했습니다. 선형 회귀는 잘 훈련된 모델을 어떻게 평가 할까요? 답은, **MSE(Mean Square Error)**를 이용 합니다. 이는 실제 값과, 예측 값의 차이의 제곱의 합을 통해 모델을 평가 합니다. 식으로 나타내면 다음과 같습니다. 여기서 는 실제 값, 는 예측 값을 의미 합니다.
여담
MSE를 에 대해 미분 하면 다음과 같습니다. 그렇기 때문에, 안정적인 학습을 위해 를 정규화 해 주는 것이 좋습니다.
Code Implement
일단 필요한 Module을 전체 Import 합니다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sklearn
from sklearn import linear_modelTrain Data
일단 Train Data를 한 번 만들어 보겠습니다. Train Data는 numpy를 이용 하여 제작 합니다. 일단 train_x 데이터의 각 Element에 있는 요소는 차원이 일치 하여야 합니다. 예제는 train_x로 1차원 벡터의 집합을 사용 합니다.
# train_data
train_x = np.arange(0, 3, 0.1) # 0, 0.1, ... 2.9
train_y = (train_x * 2 + 1) + np.random.normal(0, 0.4, 30) # size 30의 random 값을 가진 array를 더함
plt.xlim(-0.5, 3.5)
plt.ylim(0, 9)
plt.scatter(train_x, train_y) # scatter
plt.show()
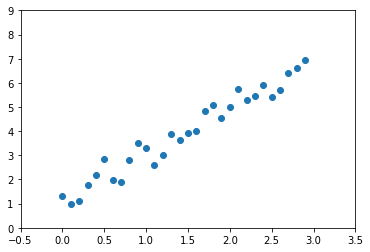
특정 규칙성을 띄며 찍한 샘플들
Train Model
그 다음, linear_model.LinearRegression() 객체를 이용하여, 모델을 생성 한 후, fit() 메서드를 통해 학습 시킵니다. 그러면 .coef_ (가중치), .intercept_ (bias)가 이에 따라 학습 된 것을 볼 수가 있습니다.
# reshape: 파라미터로 shape의 모양이 들어 간다. -1인 경우 Element의 갯수에 따라 자동 조정
train_x = train_x.reshape(-1, 1) # train_x를 [[x1, x2 ... xn], [x1, x2 ... xn], ... [x1, x2 ... xn]] 형태로 변환 하여야 함
reg = linear_model.LinearRegression()
reg.fit(train_x, train_y) # fit: (x, y) => 여기선 x의 shape: (30, 1), y의 shape: (30)
print(reg.coef_, reg.intercept_) # coef: w, intercept: bResult
여기서 구한 .coef_, .intercept_을 바탕으로 직선을 그려 보겠습니다.
plt.xlim(-0.5, 3.5)
plt.ylim(0, 9)
plt.plot([0, 3], [0 * reg.coef_[0] + reg.intercept_, 3 * reg.coef_[0] + reg.intercept_], color='red')
plt.scatter(train_x, train_y)
plt.show()
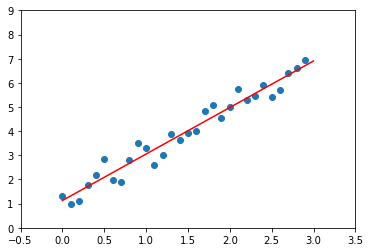
결과
곡선으로도 그릴 수 있나요?
네, 당연히 가능합니다. 바로 Polynomial Featrues를 통해서 말이죠.
가지고 있는 데이터가 직선보다 복잡한 형태일 경우, 각 특성의 거듭제곱을 새로운 특성으로 추가하고, 이렇게 새롭게 만들어진 특성에 대해 선형 모델을 훈련시키는 다항 회귀 방법을 사용 할 수 있습니다. sklearn.preprocessing 모듈 내의 PolynomialFeatures 클래스를 이용 하여 거듭제곱의 특성을 새로 추가 할 수 있습니다.
- In
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
import numpy as np
X = np.random.random((100, 2))
y = np.array([X[i][0] ** 2 + X[i][1] + 1 for i in range(100)]) # y = x_1^2 + x_2 + 1
poly_features = PolynomialFeatures(degree=2, include_bias=False)
X_poly = poly_features.fit_transform(X)
print(X[0]) # [x_1, x_2]
print(X_poly[0]) # [x_1, x_2, x_1^2, x_1*x_2, x_2^2]
lin = LinearRegression()
lin.fit(X_poly, y)
print(lin.intercept_, lin.coef_)- Out
[0.0800759 0.82814432]
[0.0800759 0.82814432 0.00641215 0.0663144 0.68582302]
0.9999999999999999 [ 7.06703197e-16 1.00000000e+00 1.00000000e+00 6.66133815e-16
-5.68989300e-16]Logistic Regression
로지스틱 회귀는 보다 높냐, 낮냐를 통해 레이블을 분류합니다. 일단, 로지스틱 회귀에 대해 자세히 알아보기 전에, Sigmoid Function에 대해 알아 볼 필요가 있습니다. 시그모이드 함수는 세상의 범주형 변수가 특정 결과를 갖는 확률은 S형 곡선을 가진다는 것에서 착안 되었습니다. 또한, 이 함수는 미분이 가능하여, 경사 하강법이 시행 가능합니다. 시그모이드 함수의 식은 다음과 같습니다.
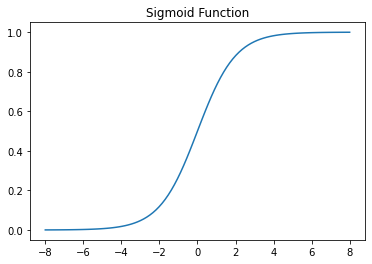
아마 머신 러닝을 미리 해 보신 분들은 이를 본 경험이 있을 것 입니다.
일단, 선형 회귀에서 한것 처럼 식을 세워 보겠습니다. 만약 0과 1중, 1일 확률을 정의해 보겠습니다. 하지만, 확률의 범위는 0~1 사이이므로, **승산(odds)**와 로그를 이용하여, 좌변의 범위가 음의 무한대부터, 양의 무한대 까지 가능하도록, 식을 다음과 같이 바꿔 써 보겠습니다.
그 다음, 를 로, 우항을 로 치환하면,
이를 통해 알고 있는 것은, 범주가 두 개인 분류 문제중, 특정 답이 나올 확률은 시그모이드 함수로 표현이 가능하다는 것입니다.
이항 로지스틱 회귀가 결과를 반환하는 방법
이항 로지스틱 모델에, 입력벡터 를 넣으면 범주 1에 속할 확률을 반환해 주려면, 가장 간단하게 확률 값을 구할 수 있는 방법은 다음과 같습니다.
좌변을 로 치환 하면 다음과 같습니다.
시각화 하면 다음과 같은 결과를 도출 할 수 있습니다. 위에서 시그모이드 함수를 도출 한 결과와, 이항 로지스틱 회귀의 결과 반환을 통해서 알 수 있는 결과는, 은, 로지스틱모델의 결정경계라고 할 수 있다는 것입니다.
Cost Function
Cost Function으로는 어떤 것을 쓸까요? 답은, 해당 문제를 답으로 예측한 확률과 실제 분류의 차이 값에 로그를 씌운 값을 더함으로써 기능 하는, Cross-Entropy Loss를 사용 합니다.
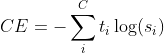
Cross-Entropy Loss, C는 클래스의 갯수, t_i는 i번째 레이블이 참이면 1, 아니면 0, s_i는 i번째 레이블이라고 예측한 확률
Code Implementation
그 다음, 데이터를 임의로 생성 해 보겠습니다. y는 x[0] * 2 + x[1] 가 1 이상일 경우 1을 나타냅니다.
train_x = np.random.randn(100, 2)
train_y = np.array([1 if x_1 * 2 + x_2 > 1 else 0 for x_1, x_2 in train_x])
color = {0: 'blue', 1: 'red'}
for i in range(100):
plt.scatter(train_x[i][0], train_x[i][1], color=color[train_y[i]])
plt.show()
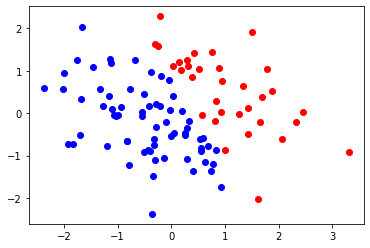
레이블이 분류된 화면
이제, LogisticRegression() 객체를 이용하여, 데이터를 학습시킬 시간입니다. 학습을 시킨 후에, 값을 해당 모델을 이용해 예측 해 본후, 이를 시각화 해 보았습니다.
lr = linear_model.LogisticRegression().fit(train_x, train_y)
print(lr.coef_, lr.intercept_) # lr.coef_가 2차원으로 쌓여 있는 이유는 다중 레이블에 대해서도 분류 하기 위함.
for i in range(100):
plt.scatter(train_x[i][0], train_x[i][1], color=color[train_y[i]])
plt.plot([-3, 3], [-(lr.coef_[0][0] * (-3) + lr.intercept_) / lr.coef_[0][1], -(lr.coef_[0][0] * 3 + lr.intercept_) / lr.coef_[0][1]], color='black')
plt.show()
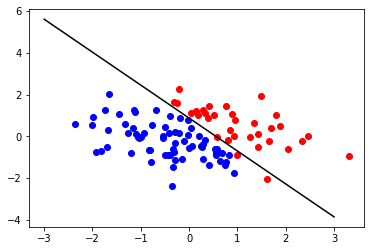
결과
다중 로지스틱 회귀?
다중 레이블에 대해서는 어떻게 할까요? 간단 합니다. 그냥 선을 여러 개 그리면 됩니다. 이에 대해 간단히 설명 하자면, 다중 로지스틱 회귀는 시그모이드 함수의 개념을 진화 시킨, 소프트맥스 함수에 더 가깝습니다. 범주가 3개인 회귀 모델이라고 가정해 보겠습니다.
이를 이항하여 정리하면, 다음과 같습니다. 이러한 연산과, 경사 하강법을 통해 답에 점점 가까워 지도록 파라미터가 학습 됩니다.
코드 또한 y에 해당하는 범주를 늘리면 간단하게 구현 가능합니다.
마치며
이번 시간에는 선형 회귀와 로지스틱 회귀에 대해서 배워 보았습니다. 다음 시간에는 SVM, K-NN, Random forest에 대해 이론을 알아 보고, scikit-learn으로 실습 하는 시간을 가져 보도록 하겠습니다.